产品
解决方案
文档与社区
权益中心
定价
云市场
合作伙伴
支持与服务
了解阿里云
备案
控制台
< 查看全部产品
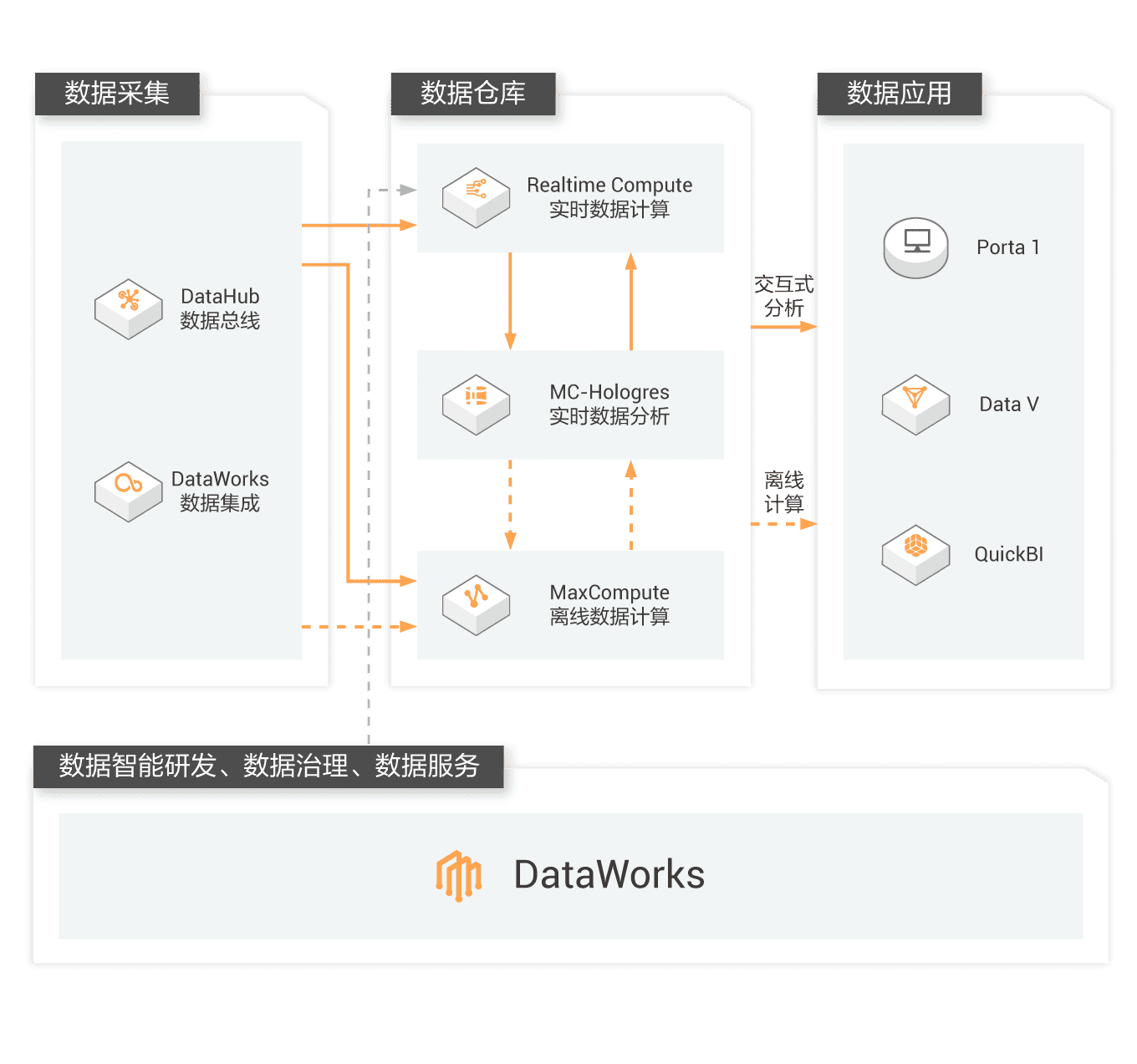
数据集成 Data Integration
数据集成 Data Integration是阿里云对外提供的安全、低成本、稳定高效、弹性伸缩的数据同步平台,属于DataWorks的核心能力之一,致力于提供复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动及同步能力。
立即开通
产品控制台
产品文档
产品价格
独享资源
产品社区
产品优势
产品规格
产品功能
应用场景
离线同步支持的数据源
实时同步支持的数据源
产品动态
文档与工具
最新活动
五折试用
独享资源组首月5折
动手实践
大数据workshop
近期重要功能
重磅发布
性能高1倍,价格低3/4!数据库实时同步新选择
新功能
一键实时/离线同步至Elasticsearch,数据集成再添新功能
产品优势
50+异构数据源
数据集成(Data Integration)支持关系型数据库、大数据存储、非结构化存储、NoSql数据库之间数据同步
查看详情
支持离线同步和实时同步
支持批量(离线)的全量/增量同步,支持单表或整库的实时同步,支持ETL,支持分库分表同步
查看详情
同步任务调度和监控报警
数据集成(Data Integration)将会监控同步任务运行的状况并对异常进行报警
查看详情
支持复杂同步场景解决方案
多种数据源之间进行不同数据同步场景的同步解决方案,包括实时数据同步、离线全量同步、离线增量同步等同步场景
查看详情
产品规格
活动中涉及“折扣”、“优惠”、“×折”或“省××元”,指相同规格产品的价格在本次活动与无任何活动时的比较。
产品优惠活动规则>
独享调度资源组
保障高峰期调度任务稳定运行及数据定时产出。
定时调度任务
首月5折
数据定时产出
首月特惠
¥
985
.00
/首月
¥985.00
立即购买
独享数据集成资源组
保障高峰期数据集成任务稳定运行及数据定时产出。
支持实时同步
首月5折
定时数据集成任务
首月特惠
¥
985
.00
/首月
¥985.00
立即购买
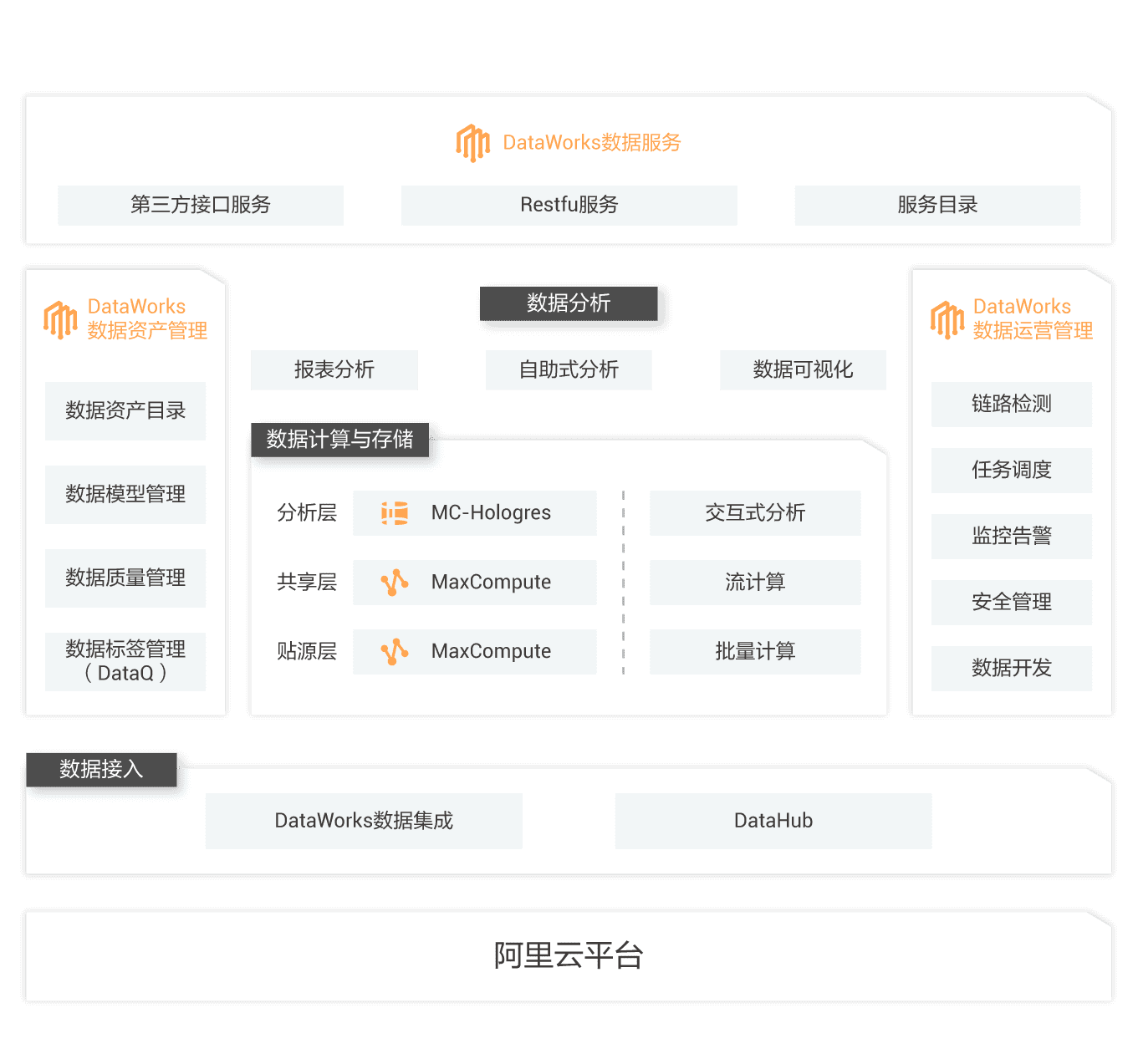
数据开发与治理产品包
阿里巴巴十二年数据中台建设黄金搭档,快速落地企业大数据开发与治理平台。
企业数据中台建设
SaaS模式云数据仓库
轻松数据治理与审计
首月特惠
¥
199
.00
/首月
¥4801.00
立即购买
数据加速分析产品包
实时、离线一体化大数据平台建设,提供百亿数据亚秒级查询能力。
搭配实时同步数据集成资源组
简化企业大数据架构
一站式OLAP开发
首月特惠
¥
199
.00
/首月
¥4812.33
立即购买
更多
产品功能
支持多种异构数据源
数据集成(Data Integration)比DataX更加高效、安全,且支持50+异构数据源之间的相互数据同步,通过数据源的Reader、Writer插件,无需用户实现复杂的编程,支持分库分表
Reader&Writer插件
主要通过定义数据来源和去向的数据源和数据集,提供一套抽象化的数据抽取插件(称之为 Reader)、数据写入插件(称之为 Writer),并基于此框架设计一套简化版的中间数据传输格式,从而达到任意结构化、半结构化数据源之间数据传输的目的。
查看详情
抽取、转换、导入
数据集成支持在数据抽取过程中进行简单的ETL数据转换操作(如日期解析、数据过滤等),导入到大数据处理中心,利用大数据引擎强大的计算能力可以再进行更复杂的数据转换操作。
跨公网传输
支持阿里云经典网络、专有网络(VPC)环境下的数据同步以及本地IDC网络环境下的数据集成。
查看详情
支持多种同步方式
数据集成 Data Integration支持数据批量(离线)的全量/增量同步以及实时同步和ETL(DataX不支持实时同步)
批量(离线)数据的全量/增量同步
批量同步主要应用场景为阿里云大数据计算存储(包括 MaxCompute、AnalyticDB 、HDFS等)提供离线(批量)的数据进出通道,支持分库分表同步。
查看详情
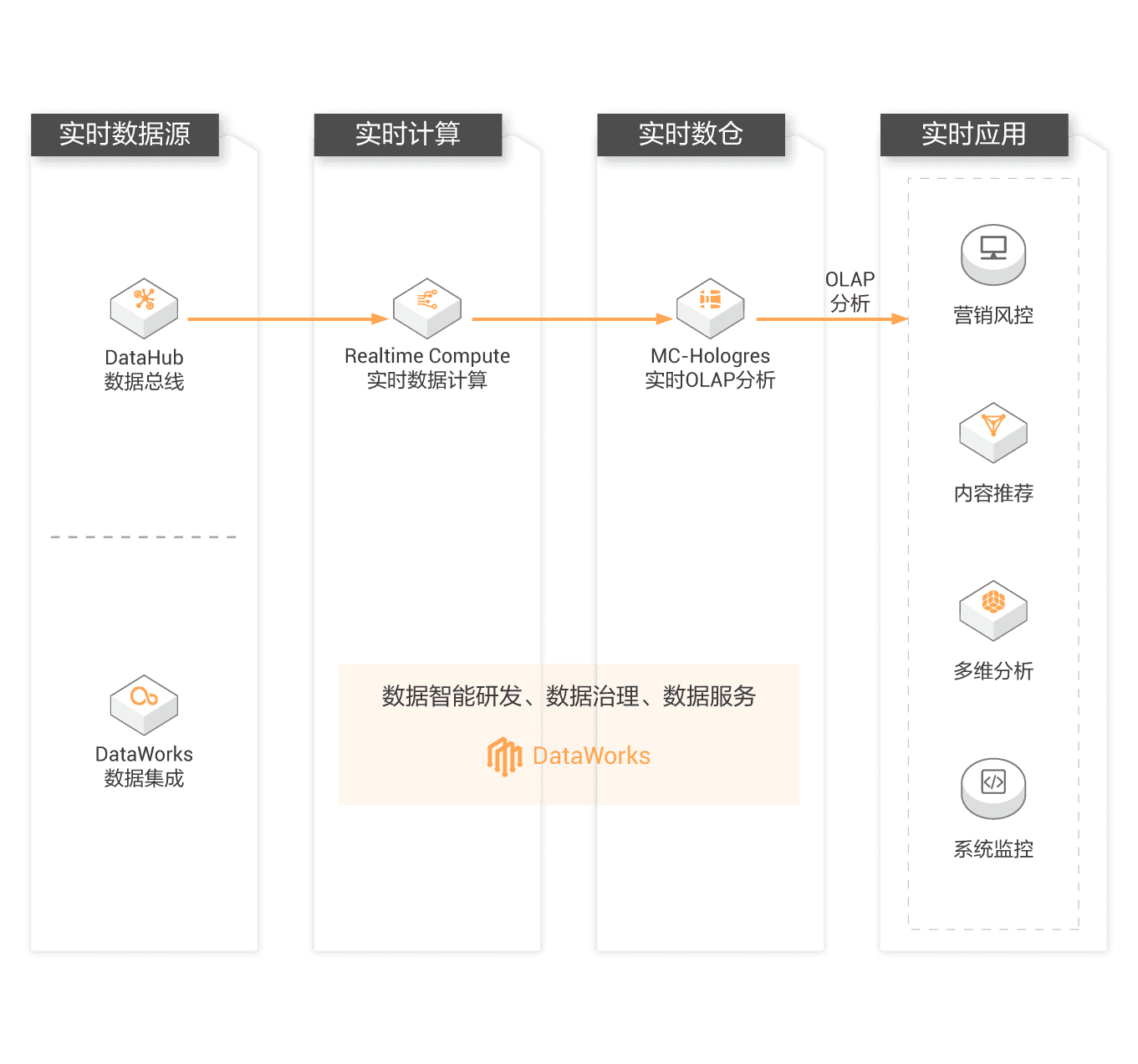
实时同步
实时数据同步功能,方便您使用单表同步或整库同步方式,将源端数据库中部分或全部表的数据变化实时同步至目标数据库中,实现目标库实时保持和源库的数据对应。
查看详情
全增量一体化同步
数据集成支持同步解决方案功能,您可以通过配置同步规则同步整库的离线全量和实时增量数据,支持一键同步至Elasticsearch、MaxCompute、Hologres
查看详情
调度&监控告警
数据集成 Data Integration与大数据开发套件深度集成,完全复用开发套件的调度能力和同步任务运维能力
定时任务调度
数据集成支持多时间维度(天、小时、分钟)的离线任务定时调度,只需要简单几步便可完成数据增量抽取。
任务出错报警
当任务出现错误的时候,数据集成支持通过预定义的方式告知用户任务失败。用户可以按照自己定义的规则来配置告警规则。
解决方案
数据集成 Data Integration提供多种数据源之间进行不同数据同步场景的同步解决方案(DataX不支持),支持ETL,助力企业数据更高效、更便捷的一键上云
一键实时同步至Elasticsearch
将指定的整个数据库全部或者部分表一次性的全部同步至Elasticsearch,并且支持后续的实时增量同步模式,将新增数据持续同步至Elasticsearch。
查看详情
一键实时同步至MaxCompute
可以将指定数据源中的数据,通过简单的配置,一次性的实时同步到MaxCompute中,支持整库内批量多表同步,同时也支持全增量一体化同步,先全量数据迁移,然后实时增量保持更新;支持自动建立实时后merge任务。
查看详情
一键实时同步至Hologres
可以将指定数据源中的数据,通过简单的配置,一次性的实时同步到Hologres中,支持整库内批量多表同步,同时也支持全增量一体化同步,先全量数据迁移,然后实时增量保持更新。
查看详情
整库迁移
整库迁移是数据集成 Data Integration提供的一种批量创建同步任务的快捷工具,可以快速完成把一个Mysql DB 库内所有表一并上传到 MaxCompute 中,节省大量初始化批量任务创建时间
MySQL整库迁移
快速把MySQL数据库内所有表一并上传至MaxCompute,极大减少您初始化上云的配置、迁移成本。
查看详情
Oracle整库迁移
快速把Oracle数据库内所有表一并上传至MaxCompute,极大减少您初始化上云的配置、迁移成本。
查看详情
其他类型整库迁移
支持PostgreSQL、SQL Server、DRDS、PolarDB、AnalyticDB for PostgreSQL、HybridDB for MySQL、AnalyticDB for MySQL 3.0和DM类型的数据源整库迁移至MaxCompute。
查看详情
应用场景
互联网
金融
新零售
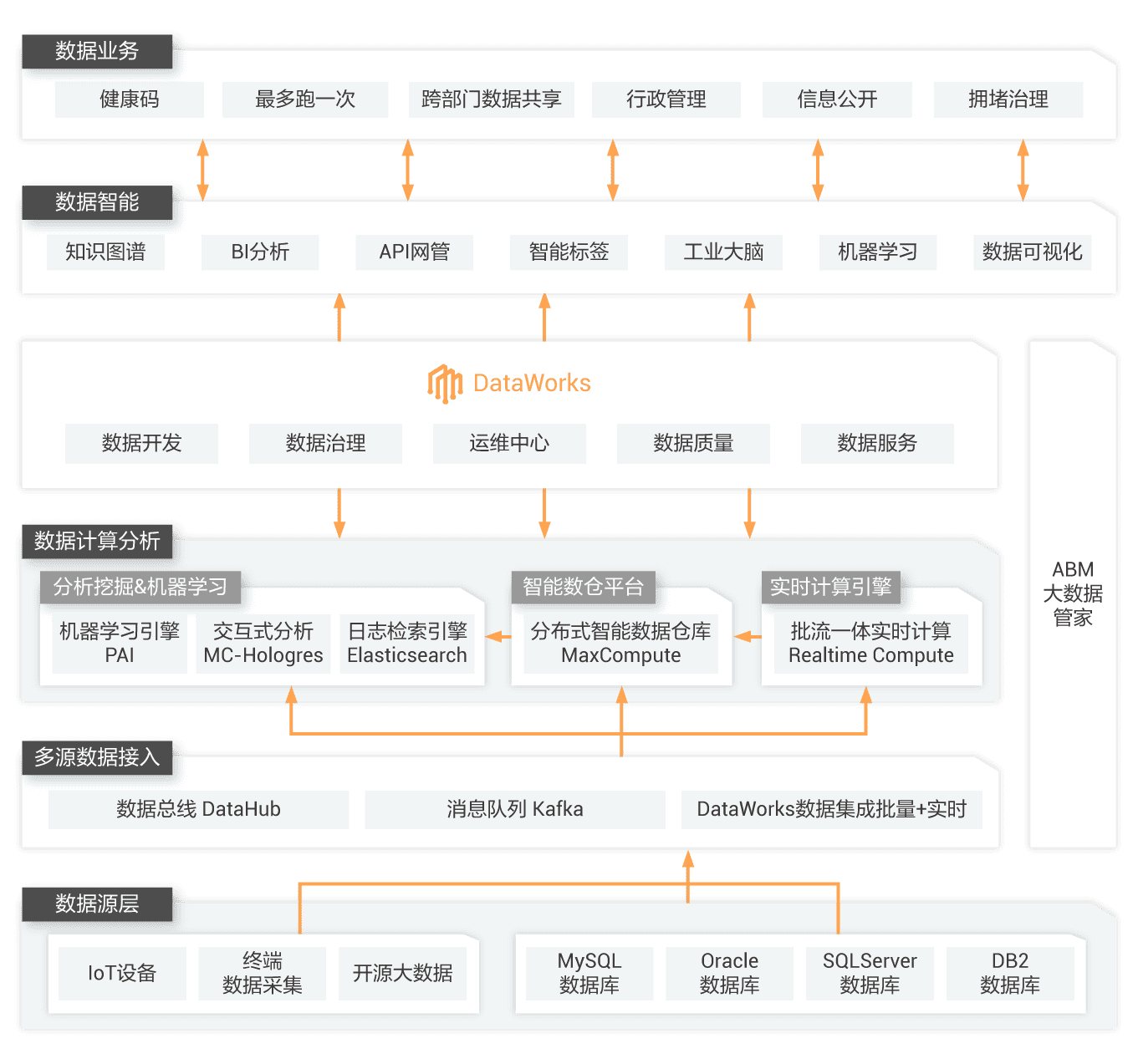
数字政府
电力
方案描述
互联网业务变化与增量速度都非常快,通过DataWorks构建简单、灵活,弹性的技术架构满足业务发展需求。
立即购买
能够解决
构建实时离线一体化数据仓库
推荐、风控、分析等实时业务
支持弹性伸缩,成本下降30%
简化纷繁复杂的多种大数据技术架构
推荐搭配使用
DataWorks
MaxCompute
Hologres
实时计算Flink版
方案描述
随着金融行业发展,传统的离线数仓已经越来越难以满足业务的实时诉求,通过DataWorks构建实时数据仓库,推动行业大数据业务化运营转型。
立即购买
能够解决
实时客户分析及精准推荐
实时营销活动分析及监控
构建客群标签画像,直观描述群体特征
减少重复营销成本,提高ROI
推荐搭配使用
DataWorks
实时计算Flink版
Hologres
数据总线DataHub
方案描述
为了快速数智化转型,拥抱新零售,新零售企业通过DataWorks构建数据中台,可以帮助企业降低TCO的同时,更好的依托云上生态,实现数据资产业务化闭环。
立即购买
能够解决
新零售数据中台建设
业务多维分析
业务数据化,全域数据中台构建数智底座
数据业务化,数据综合治理驱动业务增长
推荐搭配使用
DataWorks
MaxCompute
Hologres
实时计算Flink版
方案描述
随着新冠疫情等黑天鹅事件的发生,对政府敏捷性与灵活性提出了更高的要求。DataWorks数字政府解决方案与DataQ等生态产品的结合,助力政府协同化、数字化,智能化,协助政府更好服务社会公众。
立即购买
能够解决
政府数据中台建设
健康码等数据业务支撑
城市大脑数据底座
与生态结合,通过产品的高度成熟化,将理论与实践相结合,推动政府治理精细化,服务便捷化,响应敏捷化,民生普惠化
推荐搭配使用
DataWorks
MaxCompute
实时计算Flink版
机器学习PAI
方案描述
为了加快建设“三型两网、世界一流”发展战略,通过整体电力解决方案,进行数据中台规划与建设,构建电力行业新一代信息基础平台,带动公司IT和数据资源建设、应用及运维向企业级转变。
立即购买
能够解决
一云多Region数据中台架构
统一运营运维管理
建设电力一朵云,形成“IT资源服务中心”和“数据服务中心”,实现运营“两级协同”,满足公司泛在电力物联网建设需求
推荐搭配使用
DataWorks
MaxCompute
Hologres
离线同步支持的数据源
以下仅列出部分常见数据源,作为DataX的超集,数据集成 (Data Integration) 支持50+种数据源,完整的数据源列表以及对应使用文档请参看帮助文档。
点击前往查看
数据源类型
DataHub
Hologres
MaxCompute
Elasticsearch
MongoDB
MySQL
Oracle
OSS
SQL Server
PolarDB
PostgreSQL
Redis
DB2
AnalyticDB for MySQL 2.0
Kafka
抽取(Reader)
DataHub Reader
Holo Reader
MaxCompute Reader
Elasticsearch Reader
MongoDB Reader
MySQL Reader
Oracle Reader
OSS Reader
SQL Server Reader
PolarDB Reader
PostgreSQL Reader
不支持
DB2 Reader
AnalyticDB for MySQL 2.0 Reader
Kafka Reader
导入(Writer)
DataHub Writer
Holo Writer
MaxCompute Writer
Elasticsearch Writer
MongoDB Writer
MySQL Writer
Oracle Writer
OSS Writer
SQL Server Writer
PolarDB Writer
PostgreSQL Writer
Redis Writer
DB2 Writer
AnalyticDB for MySQL 2.0 Writer
Kafka Writer
实时同步支持的数据源
数据集成 (Data Integration) 提供DataX不具备的实时同步能力,支持的输入、输出数据源如下,另外还支持两种数据转换及ETL能力,详细使用方法参见帮助文档。
点击前往查看
输入
MySQL Binlog输入
SQLServer CDC输入
DataHub输入
LogHub输入
Kafka输入
PolarDB输入
输出
MaxCompute输出
Hologres输出
DataHub输出
Kafka输出
转换
数据过滤转换
字符串替换
产品动态
查看详情
查看详情
查看详情
2017-03-23 新功能
数据集成新增更多数据源支持
查看详情
2017-05-11 新功能
数据集成本地数据上云agent
查看详情
2017-06-01 新功能
数据集成数据源迭代
查看详情
2017-06-29 新功能
数据集成新增数据源
查看详情
2017-07-13 体验优化
脚本模式新增数据源
查看详情
2017-07-13 体验优化
数据集成体验优化
查看详情
2017-09-07 新地域/可用区
产品新区域开服
查看详情
2017-09-18 新地域/可用区
产品新区域开服
查看详情
2017-11-01 新地域/可用区
产品新区域开服
查看详情
2017-12-29 新功能
新增支持同步至Elasticsearch
查看详情
2017-12-29 体验优化
提交作业重试优化等体验优化
查看详情
2018-01-12 新功能
数据集成新增日志服务(LOG)数据源
查看详情
2018-01-12 新功能
数据集成支持跨私网传输
查看详情
2018-04-02 新产品
数据集成商业化发布
查看详情
2018-04-25 新功能
数据集成新增Datahub数据源
查看详情
2018-05-23 体验优化
数据集成新购流程优化
查看详情
2018-07-24 体验优化
数据集成新版本发布
查看详情
2018-09-26 新功能
无公网IP的数据源支持元数据探查以及向导模式开发
查看详情
2018-10-20 新功能
支持POLARDB作为数据源
查看详情
2018-10-20 新功能
DRDS反向支持VPC
查看详情
2018-10-31 新功能
整库迁移支持批量操作多库且参数化配置的需求
查看详情
查看全部日志
文档与工具
产品文档
了解数据集成 (Data Integration)
支持的数据源
了解数据集成支持的50+异构数据源
快速开始
创建数据集成的同步任务
常见问题
常见问答和更多技术交流