
面对微服务化、容器化改造,访问链路和部署复杂度的提升,友邦人寿规划落地可观测性,实现更好地观测应用。
友邦保险是香港联合交易所上市的人寿保险集团,覆盖 18 个市场。截至 2021 年 12 月 31 号,总资产 3400 亿美元。友邦保险于 1992 年在上海设立分公司,是改革开放后最早一批获发个人人身保险业务营业执照的非本土保险机构之一,也是第一家将保险营销员制度引进国内的保险公司。2020 年 6 月,友邦获批将友邦保险有限公司上海分公司改建为友邦人寿保险有限公司。2020 年 7 月,友邦人寿正式成为中国内地首家外资独资人寿保险公司。友邦友享 App 在 2021 年荣获最佳保险科技平台。
友邦在上云过程中,对大量应用进行了微服务化改造,并采用了容器化方案部署,以获得更好的弹性、更高的可用性、更好的稳定性。这些改造同时也带来了应用链路复杂度提升的挑战,从而产生较强的对K8S基础设施和微服务应用状态的观测需求。
与此同时,部分外采应用没有源码,不适合做微服务化改造,但仍然对这部分应用进行了容器化改造,将它们部署进 K8s;还有一部分应用由于各种原因,不适合上云改造,无法容器化改造,最终以ECS方式部署,甚至留在云下IDC 机房。服务之间的调用会涉及云上到云下、云下到云上等复杂情况。迁云之后实实在在带来了 SLA 的提升,但也导致了访问链路和部署复杂度的提升,如何更好地观测应用成为了无法回避的挑战。
建设一个优秀的观测系统,会面临以下痛点:
- 观测复杂度提升
云原生微服务化虽然带来了很高的 HA,但也提升了系统的复杂度,加大了可观测的难度。各种业务指标数据散落在各个业务模块里,业务需要提供全局视角,以观察整个保单生命周期里重要业务节点的运行情况,并获取研发态的具体情况。
- 技术选型困难
由于历史原因,友邦内部应用技术选型不一,版本各异,导致可观测技术和调用链追踪面临很大的困难。
- 统一观测困难
根据友邦内部软件开发流程,系统开发和应用运维完全分开,日志也分权限存储和维护,因此很难将以上数据在同一个大盘里呈现。
- 指标治理难
IaaS层、PaaS 层和应用层有很多指标,单数据库方面就可能有超过 200 多个指标。如果希望指标达到比较容易理解与追踪的数量,则需要不断地进行回顾、删减。
- 快速故障定位难
虽然已经有商业 APM 工具,但其价格高昂,不属于经济有效的方式。问题发生时,因为只有部分应用安装了 APM,所以调用链不完整,无法实现快速故障定位。
友邦为了满足业务发展需求,在技术层面需要做云原生技术架构的升级和改造。因此阿里云与友邦在应用容器化和可观测性上展开了深度合作。结合业务情况和监控痛点,通过几十次的讨论和推演,最终明确了两个重要建设思路:根据业务价值自上而下设计可观测体系并结合业务设计服务的链路追踪、应用性能监控。然后再明确可观测的指标范围:可观测指标不仅是运行态,还需要包含研发态,形成应用全生命周期的监控指标体系。
系统经过云原生改造后,友邦的 CICD 流水线通过 Jenkins 进行自动化。为了提升软件的研发效率,需要抽象出可衡量的指标,比如应用每天的构建次数、构建时长、构建成功率、部署频率或部署成功率,以及形成这些指标的基础元数据信息等。运行态分为系统层监控、应用层监控和业务层监控三层,监控重要性等级依次升高。资源监控层主要聚焦在 K8s 集群的 node 节点、磁盘网络、运行 Pod 监控、核心云产品等监控指标;应用层主要聚焦于应用的健康度、状态码、性能监控、JVM、GC 等性能指标上;业务层主要监控业务的核心指标,如 PV、UV、投保人数、投保金额、签单数等,它直接影响着监控系统设计的成败,因为这是最能够体现业务价值的部分。
友邦人寿可观测性体系的架构总体设计思路分为三层:
第一层为采集层。为了符合友邦的技术架构和建设需求,选择用 Java 编写流水线的 CICD 数据采集器。研发人员在使用 Jenkins 时,该采集器能将应用构建的数据和部署的数据全部存到数据库里。另外,采集数据时加上了相关联的 tag ,实现了元数据的共享。比如流水线构建的应用名称必须与 K8s 的服务名称一致,构建失败时即可快速找到出错的应用。针对应用的 APM 探针,社区一般使用字节码增强的无侵入技术。但是由于友邦架构的复杂度,Skywalking 探针无法完全覆盖友邦的场景。同时,友邦对于深度性能的诊断也有较高要求,希望能够集成阿里开源的 Arthas、 Memory dump 等能力。最终选择经过双 11 大规模检验的 ARMS Agent。各类云产品中间件、集群的监控指标采集主要通过 Prometheus;应用日志主要使用 DaemonSet 的方式进行采集,相比于 Sidecar,其占用资源更少,工程上也更为简单。
第二层为存储层。研发态的元数据和 pipeline 的构建数据因其数据量不大,而且是结构化形态,因此存储在 MySQL 里。Metrics 监控指标的数据存储在阿里云的 Prometheus 产品上,日志和调用链 Tracing 数据存储在阿里云的 SLS 产品上。考虑到业务的增长,未来会产生大量的数据,这两款产品能够保证监控系统的稳定性、可扩展性和高可用性。同时,两款产品都是 Serverless 化持续按量付费,不存在磁盘或空间浪费。
第三层为统一展示层。通过 Grafana 进行汇聚和展示。当时阿里还未推出托管版的 Grafana,因此友邦选择自建。为了保证运行的高可用,需要多实例部署,并将配置的数据统一传到数据库里,然后根据此前设计的监控指标,选择对应的数据源编写查询语句,最终结合 Grafana 丰富的图表进行统一展示。业务监控的实现是通过将采集到 SLS 里的业务日志和应用日志做统计分析。SLS 的 SQL 查询功能非常丰富,语句编写也非常方便。再通过 SLS Grafana 插件集成到 Grafana 里,最终业务统计数据即可在 Grafana 大盘进行展示。
整体架构图如下所示:

通过大屏、中屏和小屏的方式形成指挥决策、研发仪表盘和应用性能展示以及告警推送、多维度的监控能力。大屏展示核心指标,比如容器集群的资源利用率、service Pod 健康度以及联通性等通用指标,为公司决策提供支持。中屏主要展示流水线的研发效率指标、应用性能的指标以及全局调用链,帮助研发人员提升效率和问题定位的速度。小屏通过历史数据的对比,设置了报警阈值。出现异常时,通过钉钉或短信报警的方式推送到电脑、手机终端,帮助运维人员及时发现和处理问题。
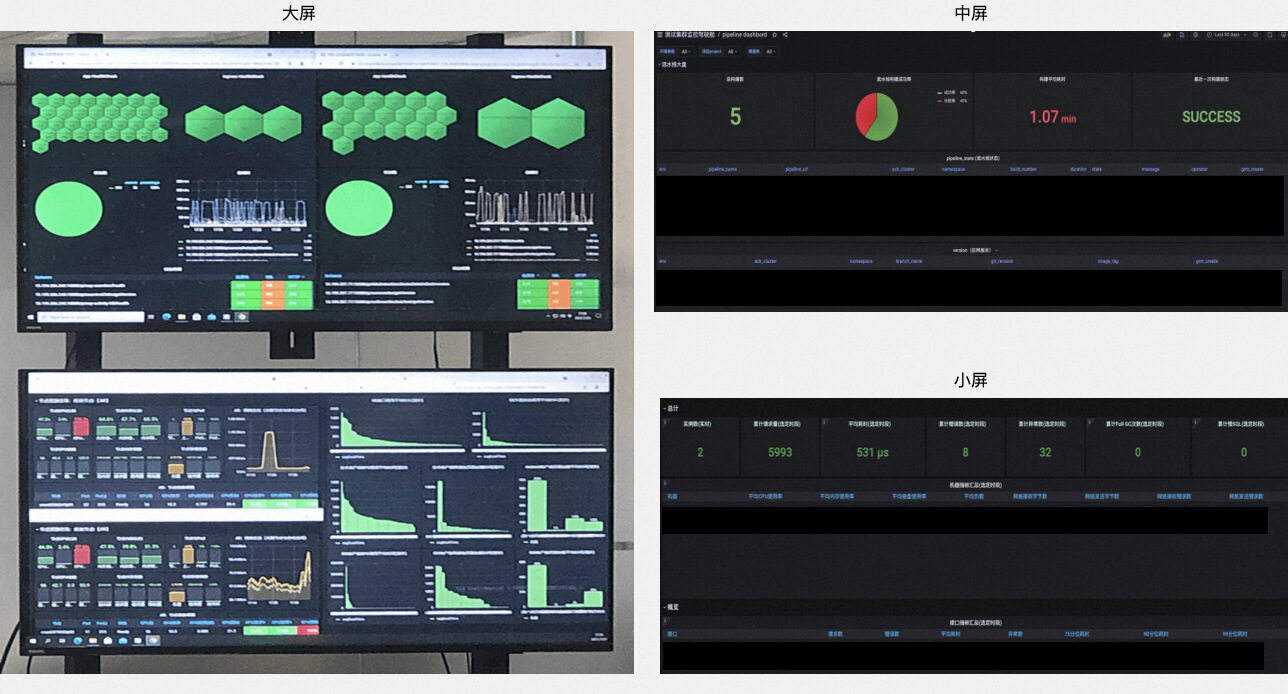
友邦人寿通过阿里云可观测服务和相关产品建设了一个优秀的观测系统,完成对系统层监控、应用层监控和业务层监控的核心指标实时掌控,辅助业务决策的同时提升了研发效率。