产品
解决方案
文档与社区
权益中心
定价
云市场
合作伙伴
支持与服务
了解阿里云
备案
控制台
< 查看全部产品
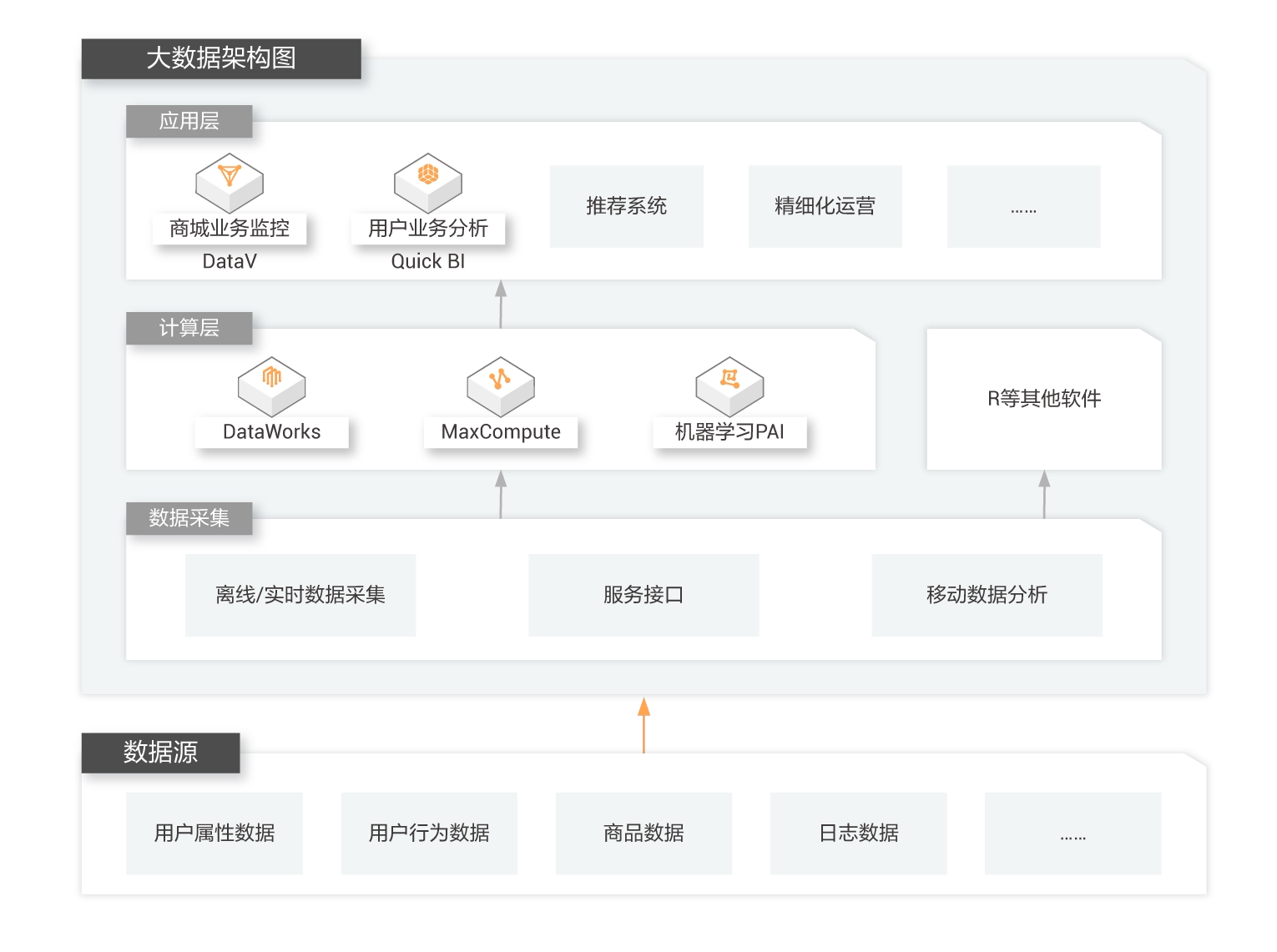
云原生大数据计算服务 MaxCompute
播放视频
MaxCompute 是面向分析的企业级 SaaS 模式云数据仓库,以 Serverless 架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您可以经济并高效的分析处理海量数据。数以万计的企业正基于 MaxCompute 进行数据计算与分析,将数据高效转换为业务洞察。
MaxCompute 资源抵扣包套餐(500CU*H+100GB存储)仅售 59元/年
立即开通
立即购买
产品优势
产品功能
产品规格
产品动态
迁移
应用场景
解决方案与最佳实践
客户案例
文档与工具
近期新功能
邀测
分布式计算框架MaxFrame发布,高效、一站式完成Data+AI开发
新版本
MaxCompute发布按量付费闲时版,计算成本至高节省66.66%
新功能
MaxCompute 物化视图智能推荐发布,CU算力节省14%
新功能
MaxCompute 跨地域灾备邀测发布,提升数据安全性
近期资讯
云栖大会
MaxCompute 架构升级及开放性解读
互联网大会
阿里云大数据智能计算平台ODPS入选2022世界互联网领先科技成果
TPC
TPCx-BB官宣2022最新成绩,MaxCompute六连冠全球冠军
Forrester
以MaxCompute为核心代表的阿里云数仓挺进全球卓越表现者象限
产品优势
为业务敏捷而生的简单、易用、全托管的 SaaS 模式云数据仓库服务 >
简单、易用
面向数仓优化高性能存储、计算;多服务预集成、标准SQL开发简单;内建完善的管理和安全能力;免运维,按量付费、不用不花钱。
匹配业务发展的弹性扩展
存储和计算独立扩展,动态扩缩容,按需弹性,无需提前容量规划,满足突发业务增长。
支持多种分析场景
支持开放数据生态,以统一平台满足数据仓库、BI、近实时分析、数据湖分析、机器学习等多种场景需要。
开放的平台
支持开放接口和生态,为数据、应用迁移、二次开发提供灵活性;支持与AirFlow、Tableau等开源和商业产品灵活组合,构建丰富的数据应用。
产品功能
全托管的 Serverless 在线服务
对外以API方式访问的在线服务,开箱即用;预铺设的大规模集群资源,按需使用和付费;无需平台运维,最小化运维投入。
弹性能力与扩展性
存储和计算独立扩展,支持企业将全部数据资产在一个平台上进行联动分析,消除数据孤岛;实时根据业务峰谷变化来分配资源。
统一丰富的计算和存储能力
多计算模型(MR,DAG,SQL,ML)和丰富的UDF,采用列压缩存储格式,通常情况下具备5倍压缩能力,大幅节省存储成本。
与 DataWorks 原生集成
一站式数据开发与治理平台DataWorks,可实现全域数据汇聚、融合加工和治理,支持对MaxCompute项目进行管理以及web端查询编辑。
集成 AI 能力
与机器学习平台PAI无缝集成,提供强大的机器学习处理能力;用户可使用熟悉的Spark-ML开展智能分析;使用Python机器学习三方库。
深度集成 Spark 引擎
内建Apache Spark引擎,提供完整的Spark功能;与MaxCompute计算资源、数据和权限体系深度集成。
湖仓一体
集成对数据湖(OSS或Hadoop HDFS)的访问分析,支持外表映射、Spark直接访问方式开展数据湖分析;在一套数仓服务和用户接口下,实现湖与仓的关联分析。
支持流式采集和近实时分析
支持流式数据实时写入并在数据仓库中开展分析;与云上主要流式服务深度集成,轻松接入各种来源流式数据;高性能秒级弹性并发查询,满足近实时分析场景需求。
提供持续的SaaS化云上数据保护
为云上企业提供从基础设施、数据中心、网络、供电到平台安全能力,再到用户权限管理、隐私保护等三级超20项安全功能,兼具开源大数据与托管数据库的安全能力。
产品规格
满足企业现实需求的 Serverless 算力方案,兼顾成本与性能的需要。
资源规划管理及评估 >
产品动态
2021-07-29 新功能/规格
MaxCompute项目删除新功能发布
查看详情
2021-07-29 新功能/规格
MaxCompute SQL 子查询支持多列运算的语法
查看详情
2021-07-30 新功能/规格
MaxCompute SQL 支持对部分聚合函数输入预排序
查看详情
2021-07-30 新功能/规格
MaxCompute SQL 内建函数增强对复杂数据类型数据的处理能力
查看详情
2021-08-06 新功能/规格
MaxCompute SQL 支持物化视图
查看详情
2021-08-09 新功能/规格
MaxCompute流式数据通道服务功能商业化发布
查看详情
2021-08-10 价格调整
MaxCompute SQL UPDATE、DELETE和MERGE INTO功能商业化
查看详情
2021-08-31 新功能/规格
MaxCompute SQL 新增编码转换等16个内置函数
查看详情
2021-09-01 新功能/规格
MaxCompute 支持读取 OSS 上 Hudi、Delta Lake 格式文件
查看详情
2021-09-01 新功能/规格
MaxCompute 支持访问开启 Kerberos 认证授权机制的 Hadoop 集群
查看详情
2021-09-14 新地域/新可用区
MaxCompute 产品在华南1金融云(深圳)正式开服
查看详情
2021-10-11 新功能/规格
MaxCompute集成观远数据(GuanData)BI工具(商业化)发布
查看详情
2021-10-28 新功能/规格
MCQA(MaxCompute Query Acceleration)查询缓存机制商业化发布
查看详情
2021-10-29 新功能/规格
MaxCompute外表支持Hbase增强版和云原生多模数据库 Lindorm
查看详情
2021-11-18 新功能/规格
MaxCompute集成网易有数BI工具(商业化)发布
查看详情
2021-11-23 新功能/规格
MaxCompute支持清空分区表中指定分区的数据
查看详情
2021-11-29 新功能/规格
MaxCompute专有网络连接管理产品化发布
查看详情
2021-12-01 新功能/规格
MaxCompute物化视图功能增强
查看详情
2021-12-03 新功能/规格
MaxCompute支持渐进式计算
查看详情
2021-12-30 新功能/规格
湖仓一体自助开通流程
查看详情
2022-01-06 新功能/规格
MaxCompute 管控台外部数据源管理
查看详情
2022-01-10 新功能/规格
MaxCompute Hadoop/DLF+OSS 外部项目元数据在DataWorks数据地图透出
查看详情
2022-02-23 新功能/规格
MaxCompute支持表结构变更邀测版本发布
查看详情
2022-02-25 新功能/规格
MaxCompute Logview新增数据安全管理功能
查看详情
2022-03-01 新功能/规格
MaxCompute 兼容开源 Spark 的计算服务全新支持 3.1 版本
查看详情
2022-03-01 新功能/规格
MaxCompute 支持压缩TEXTFILE 格式文件的 Skip header/ footer
查看详情
2022-03-17 新功能/规格
MaxCompute增加半结构化数据(Json)新解析方式
查看详情
2022-03-17 新功能/规格
MaxCompute增强物化视图自动改写能力
查看详情
2022-03-17 新功能/规格
MaxCompute增强OSS外表能力
查看详情
2022-03-17 新功能/规格
MaxCompute增强TRIM/LTRIM/RTRIM函数能力
查看详情
2022-03-17 新功能/规格
MaxCompute新增DISTRIBUTED MAP JOIN功能发布
查看详情
2022-05-17 新功能/规格
按外表类型对外表计算独立计费
查看详情
2022-06-23 新功能/规格
查询加速(MCQA)包年包月产品规格支持发布
查看详情
2022-06-27 新功能/规格
包年包月Quota支持单作业CU并发上限
查看详情
2022-06-27 新功能/规格
包年包月支持独占Quota
查看详情
2022-06-28 新功能/规格
支持在 DataWorks 公共表中查看外部数据源的元数据信息
查看详情
2022-07-14 新功能/规格
新增6个聚合函数
查看详情
2022-07-14 新功能/规格
新增3个窗口函数以及性能优化
查看详情
2022-07-14 新功能/规格
新增支持在表级别设置split size参数
查看详情
2022-07-14 新功能/规格
支持Unload函数导出数据时自定义导出文件名的前后缀
查看详情
2022-07-14 新功能/规格
新增一个正则函数
查看详情
2022-08-22 新功能/规格
Use Quota(作业级别指定计算资源)功能发布
查看详情
2022-08-26 新功能/规格
物化视图支持生成空分区
查看详情
2022-08-26 新功能/规格
新增物化视图状态查看函数
查看详情
2022-08-26 新功能/规格
创建内表时支持用like复制外部表的表结构
查看详情
2022-08-26 新功能/规格
新增三个聚合函数
查看详情
2022-08-26 新功能/规格
支持分区表到期后自动删除表
查看详情
2022-08-31 新功能/规格
MaxCompute Spark 支持访问 OSS 外部表
查看详情
2022-09-23 新功能/规格
MaxCompute 通过 Create table like 方式创建与外部数据源中表结构相同的表
查看详情
2022-09-24 新功能/规格
Hologres外表新增双签名鉴权模式
查看详情
2022-10-13 新功能/规格
Schema 功能正式开放公测
查看详情
2022-11-01 新功能/规格
计算抵扣包和存储抵扣包发布
查看详情
2022-11-15 新功能/规格
新版控制台发布
查看详情
2022-11-15 新功能/规格
新售卖规格弹性预留CU发布
查看详情
2022-11-15 新功能/规格
支持自定义项目管理类角色
查看详情
2022-12-14 新功能/规格
优化增强字符串函数和聚合函数能力并新增字符串函数
查看详情
2022-12-14 新功能/规格
Update语法支持From子句
查看详情
2022-12-14 新功能/规格
增加SQL Window关键字
查看详情
2023-01-12 新功能/规格
Quota使用规则发布
查看详情
2023-01-21 新功能/规格
支持Hologres外部表存储直读
查看详情
2023-02-01 新功能/规格
支持标签分账
查看详情
2023-02-25 新功能/规格
增强显示数据对象SHOW命令
查看详情
2023-03-30 新功能/规格
支持External Volume非结构化数据存储能力
查看详情
2023-03-30 新功能/规格
推出向量计算引擎Proxima CE
查看详情
2023-03-30 新功能/规格
支持使用Spark和MapReduce任务处理External Volume中的非结构化数据
查看详情
2023-04-06 新功能/规格
新版作业运维发布
查看详情
2023-04-11 新功能/规格
新人特惠规格发布
查看详情
2023-04-23 新功能/规格
物化视图加速
查看详情
2023-04-25 新功能/规格
支持更改表结构功能正式发布
查看详情
2023-05-06 新功能/规格
支持PIVOT和UNPIVOT关键字
查看详情
2023-05-06 新功能/规格
支持通过TABLESAMPLE对表数据进行采样
查看详情
2023-05-06 新功能/规格
支持使用QUALIFY过滤窗口函数的结果
查看详情
2023-05-06 新功能/规格
SQL提供内建加密函数和解密函数
查看详情
2023-05-06 新功能/规格
物化视图支持定时刷新数据
查看详情
2023-05-06 新功能/规格
新增多个内建函数
查看详情
2023-05-06 新功能/规格
支持将数据带表头写入OSS的CSV文件
查看详情
2023-05-06 新功能/规格
支持TableStore外表指定PutRow方式写入
查看详情
2023-05-24 新功能/规格
包年包月二级配额(Quota)调度策略管理功能发布
查看详情
2023-06-08 新功能/规格
计算资源优化推荐功能发布
查看详情
2023-06-27 新功能/规格
新增7个内建复杂类型函数
查看详情
2023-06-27 新功能/规格
新增Transaction Table2.0表类型
查看详情
2023-06-27 新功能/规格
新增列数据清空功能
查看详情
2023-06-27 新功能/规格
增强数据写入时Zorder功能
查看详情
2023-06-27 新功能/规格
新增Json数据类型
查看详情
2023-08-01 新功能/规格
按量付费闲时版发布
查看详情
2023-08-08 新功能/规格
租户级别Information Schema
查看详情
2023-08-18 新功能/规格
控制台成本分析功能发布
查看详情
2023-09-21 新功能/规格
作业分析功能发布
查看详情
2023-09-25 新功能/规格
MapReduce支持SQL运行时执行模式
查看详情
2023-11-21 新功能/规格
项目超级管理员设置支持通过RAM权限管控
查看详情
2023-11-22 新功能/规格
支持列级别数据加密
查看详情
2023-11-22 新功能/规格
支持PAIMON外部表
查看详情
2023-11-22 新功能/规格
支持增加TableStore外表脏数据处理配置
查看详情
2023-12-20 新功能/规格
支持通过控制台编辑外部网络地址
查看详情
2023-12-26 新功能/规格
控制台上线迁移服务
查看详情
2023-12-28 新地域/新可用区
按量付费闲时版新增中国站国际地域及国际站发布
查看详情
2024-01-02 功能优化
控制台资源观测支持修改指标聚合算法
查看详情
2024-01-25 新功能/规格
计算成本优化功能发布
查看详情
2024-02-29 新功能/规格
跨地域灾备邀测发布
查看详情
2024-03-21 新功能/规格
ECS资源复用版发布
查看详情
查看全部日志
迁移到 MaxCompute
为什么要迁移到 MaxCompute >
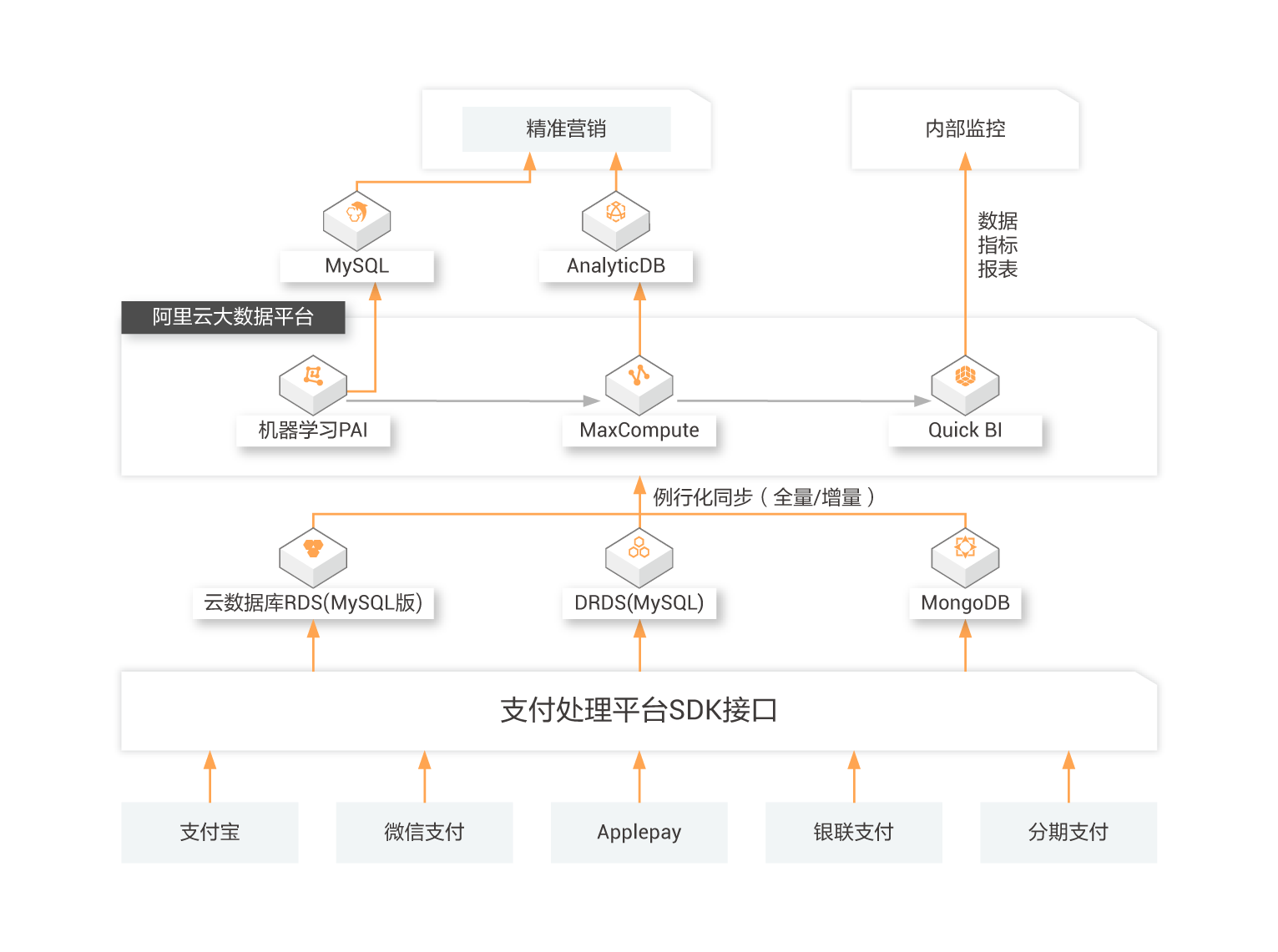
阿里云某金融行业客户:“利用阿里云 MaxCompute Migration Assistant (MMA) 与 DataWorks 迁移助手等工具,帮助我们实现了 PB 级数据、 上万张表2周内从云下Hadoop集群迁移上云,并在5个工作日内协助完成了上千核心作业改造。迁移后任务基线提前3小时,性能提升 30%”。
从Hadoop 迁移到 MaxCompute
阿里云某游戏行业客户:“在我们自建集群网络出口极度受限的情况下,阿里云打破了基于网络传输的搬站模式,结合 MMA 在三个工作日内帮助我们完成了数据迁移这一看似不可能的任务,也让我们得到了内部业务方团队的认可”。
从其它云迁移到 MaxCompute
阿里云某母婴社区平台客户:“我们迁移的数据量超过了1PB,单表规模超过了80TB。在这样的极端场景下,阿里云 MMA 以三倍于其它工具的性能优势,打消了我们最初的顾虑, 最终高效,稳定,准确地帮我们完成了数据迁移,实现了业务在云上的落地”。
从传统数仓迁移到 MaxCompute
应用场景
智能物流
云数据仓库
日志大数据分析
精细化运营
搜索推荐
海量营销数据分析
智能物流
成本低,数据处理时间显著提升 菜鸟智能物流分析引擎是基于搜索架构建设的物流查询平台,日均处理包裹事件几十亿,承载了菜鸟物流数据的大部分处理任务。
查看详情
能够解决
更低成本的整体硬件资源
现有数据规模的处理需求,整体硬件资源成本下降60%+
更快的全链路处理速度
全量数据处理时间极大被压缩,2亿的记录,端到端只需要3分钟
更高效便捷的数据查询操作
一个系统满足多种场景查询,没有数据冗余,还有查询报错功能
推荐搭配使用
Hologres
实时计算Flink版
云数据仓库
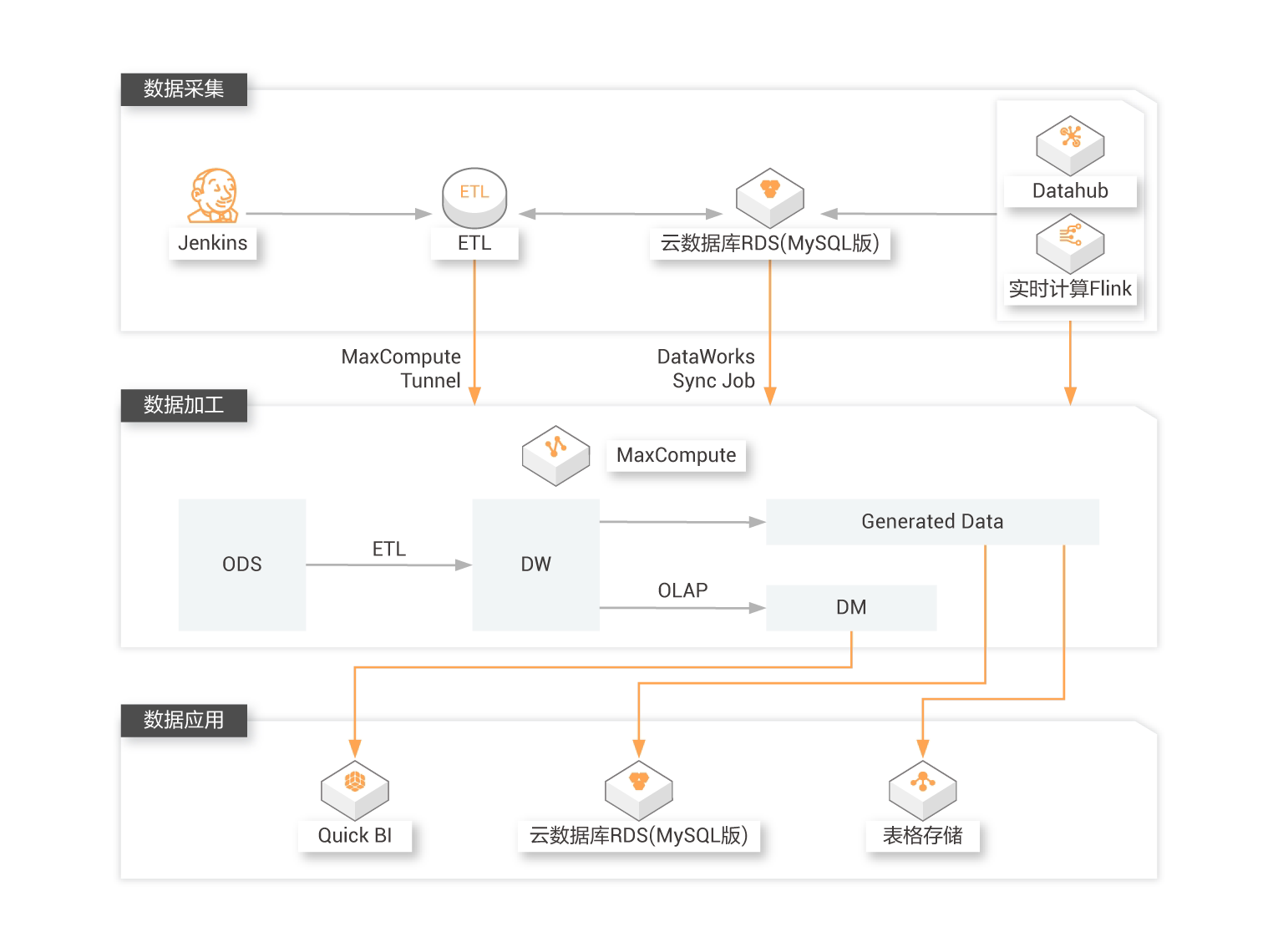
在云计算、大数据时代,数据仓库的重要性毋庸置疑,其建设也在不断的进化中。某知名新零售客户在横向对比之后,毅然决定基于MaxCompute强大的计算能力进行数据仓库的建设。
查看详情
能够解决
数据上云
第一阶段通过DataX和Tunnel向MaxCompute同步数据
数据清洗
第二阶段通过内部产品打通在DataWorks进行同步和数据清洗
数据展现
DataWorks进行ETL和OLAP的数据通过Quick BI产出报表
推荐搭配使用
MaxCompute
DataWorks
Quick BI
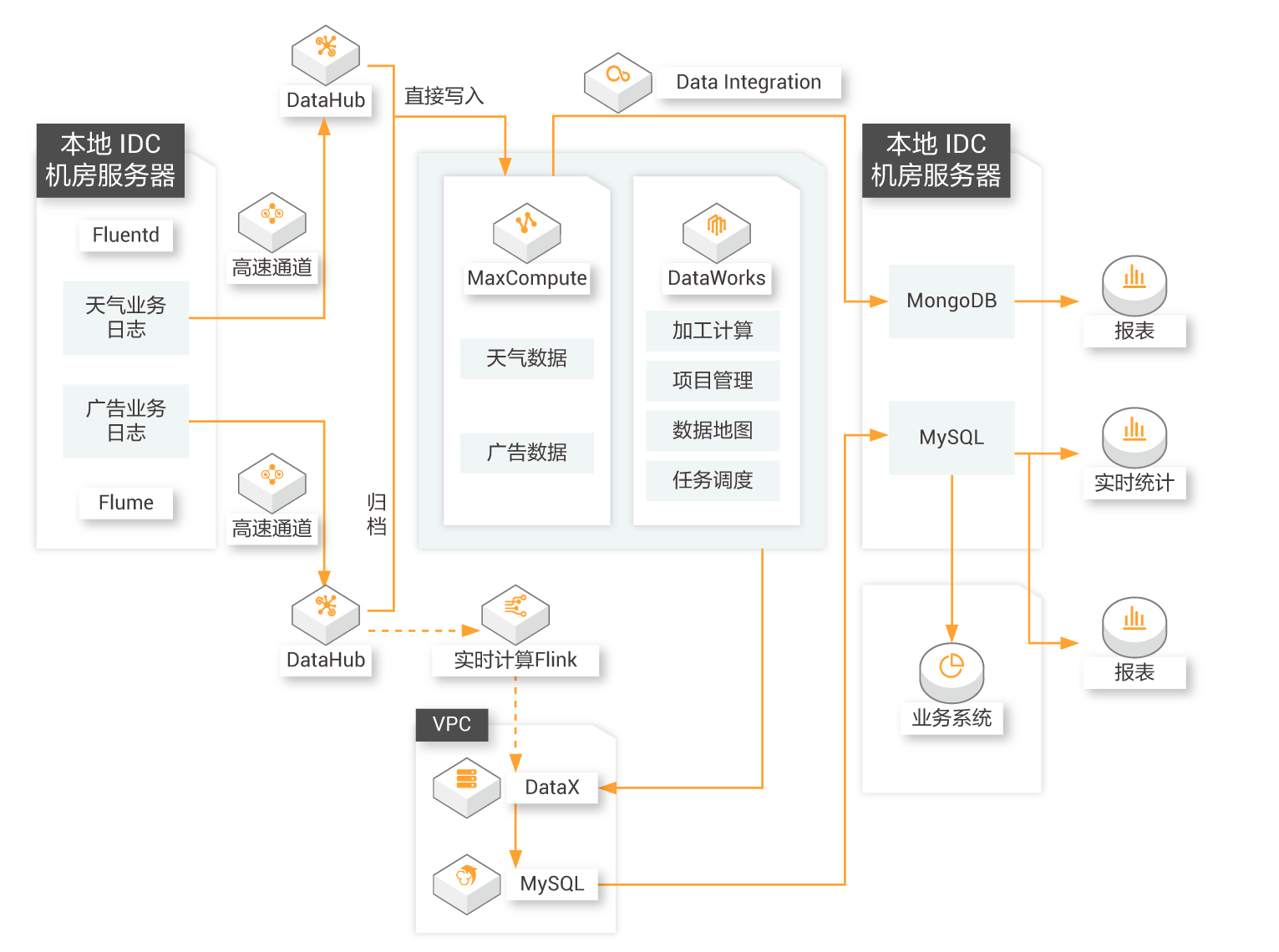
日志大数据分析
某天气信息查询软件客户将日志分析业务从云下Hadoop集群迁移到阿里云MaxCompute后,开发效率提升超过5倍,存储和计算费用节省了70%,更高效的赋能其个性化运营策略。
查看详情
能够解决
提高工作效率
日志数据全部通过SQL进行分析,工作效率提升了5倍以上
提升存储利用率
整体存储和计算的费用比之前节省70%,性能和稳定性也有提升
降低大数据使用门槛
MaxCompute提供多种开源软件的插件,轻松完成数据上云
推荐搭配使用
DataWorks
Quick BI
日志服务(SLS)
精细化运营
某知名电商客户截至目前已经拥有百万级别的用户,积累了大量的数据,如何更好的服务用户并提升客户体验是其进行大数据探索的出发点。
查看详情
能够解决
提升业务洞察能力
通过MaxCompute计算能力实现了针对百万用户的精细化运营
业务数据化
对业务数据分析能力提升并有效监控,更好的业务赋能
快速响应业务需求
阿里云大数据生态满足新业务数据分析需求的“随机应变”能力
推荐搭配使用
DataWorks
Quick BI
搜索推荐
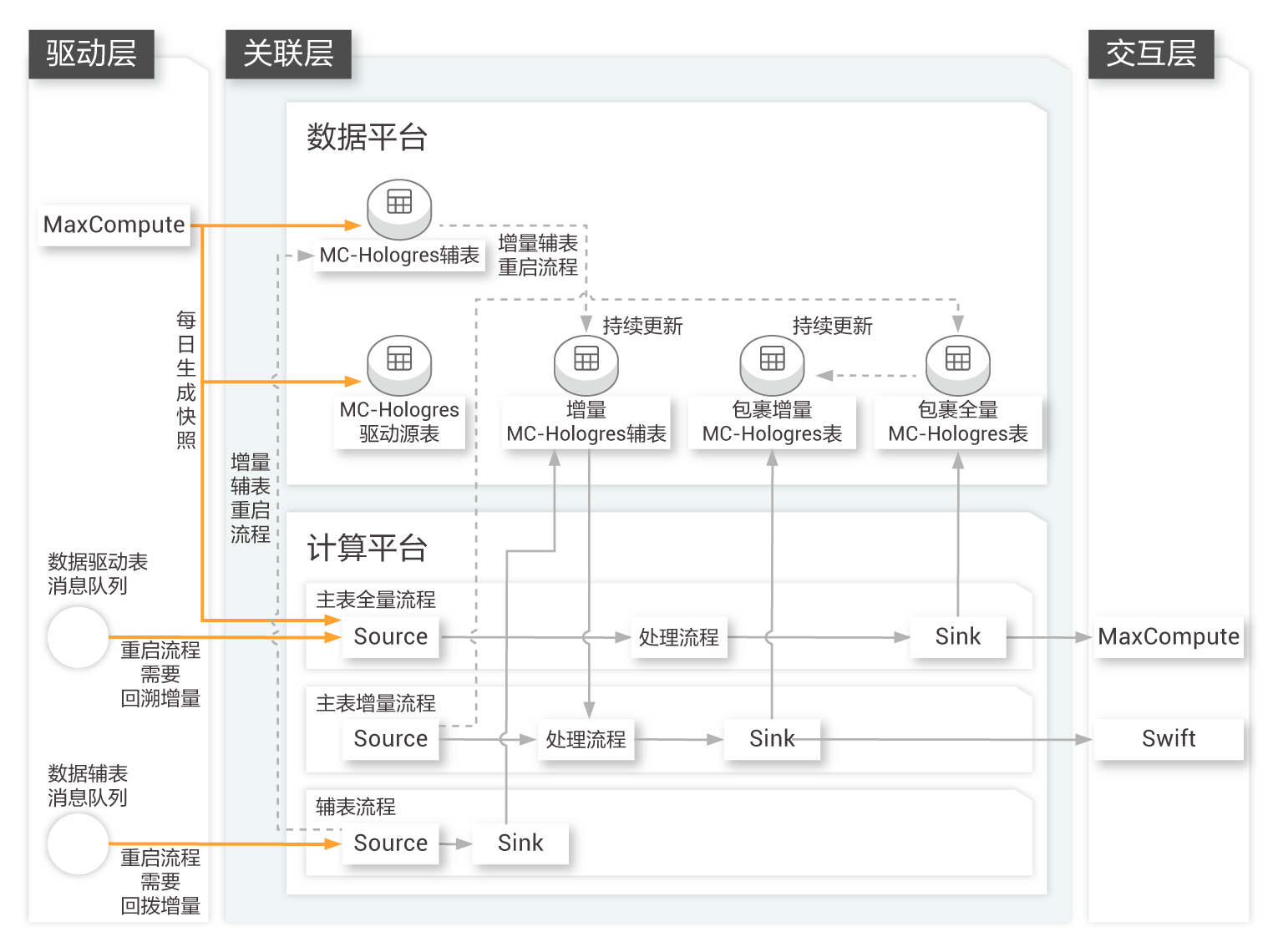
目前阿里巴巴淘系已能通过平台自助打标后,在报表中做自助即席多维分析,涵盖1000+自定义维度信息,无需开发同学额外支持,解放人力,减少沟通成本。
查看详情
能够解决
更快速更精准地获取用户数据
无需更改blink作业,整体链路1小时内完成维表数据切换
更快的查询响应
数据量大,资源有限,数据生产基本无延迟,且查询秒级内响应
实现数据输出的交互式、个性化、高扩展性
几十亿商品的特征信息仅耗时5分钟完成数据切换
推荐搭配使用
Hologres
实时计算Flink版
海量营销数据分析
某知名聚合支付客户日交易笔数在百万级别,目前已经积累了海量交易数据。如何对海量数据进行分析与业务创新从而提高用户黏性,亟需搭建安全、可靠、稳定的大数据平台。
查看详情
能够解决
数据创新
一站式大数据平台同时满足存储、计算、BI和机器学习等功能
快速、高效、低成本
作为互联网创业公司,需尽可能以最低的成本去实现
安全、稳定、可靠
需要严格的数据隐私保护机制,商户的数据只用于自身分析
推荐搭配使用
机器学习平台PAI
Quick BI
更多产品与服务
ODPS-DataWorks
ODPS统一开发与治理平台
ODPS-Hologres
ODPS实时交互式计算引擎
机器学习平台 PAI
可基于PAI的算法组件进行模型训练等操作
消息队列 Kafka 版
便捷地对离线数据进行分析加工
Quick BI
实现MaxCompute表数据的可视化分析
Tableau
与MaxCompute集成,实现可视化分析
帆软 FineBI
联合发布企业级BI分析解决方案
Kettle
基于Kettle的MaxC插件数据上云
解决方案与最佳实践
更多行业与通用解决方案 >
行业解决方案
查看更多 >
通用解决方案
查看更多 >
精选最佳实践
查看更多 >
精选客户案例
各行业客户案例与最佳实践 >
小打卡
基于 MaxCompute 构建数仓,在初期只有一名开发人员的情况下,也能快速地搭建起数仓系统,且费用成本极低。
查看详情
天弘基金
MaxCompute 将原本需要清算8小时的用户交易数据缩短至1个半小时完成,更减少了本地服务器部署压力以及开发人力成本。
查看详情
玩物得志
玩物得志基于DataWorks + MaxCompute 框架,使用其核心存储、计算等组件快速搭建起自己的大数据平台。
查看详情
高德地图
MaxCompute为高德带来一键资源扩容能力,使得集群扩容在小时级别内完成,并实现了核心数据“3点产出”的骄人成果。
查看详情
优酷
优酷从Hadoop迁到MaxCompute后,我们最大的体会是不用半夜起来去维护集群了,之前排几周的需求,现在可以马上跑出来。
查看详情
友盟+
友盟+将采集的数据与客户数据进行融合,通过与MaxCompute进行云端无缝对接,支持更大力度的开放返还。
查看详情
刊物与直播
汇集 MaxCompute 电子书、月刊、新品发布会与系列公开课 >
爆款电子书
产品月刊
MaxCompute 发布会
文档与工具
免费试用 MaxCompute
帮助文档
MaxCompute 产品文档
产品社区
MaxCompute 官方技术圈
视频中心
客户案例、新品发布与系列公开课
Java SDK
常用 MaxCompute 核心接口
快速入门
通过查询编辑器使用MaxCompute
MaxCompute Studio
基于 IntelliJ IDEA 的开发插件
MaxCompute Spark
兼容开源 Spark 的计算服务
MaxCompute 百问集锦
常见问题供开发者查阅参考