01部署准备
准备阿里云账号,并开通DashScope。
02部署资源
部署网络资源、云服务器ECS实例、AnalyticDB for PostgreSQL实例,并在ECS实例上,部署RAG应用。
03启动应用
启动RAG应用。
04体验RAG应用
体验智能问答与文搜图。
05完成及清理
体验完成后,如不再使用,可释放资源。
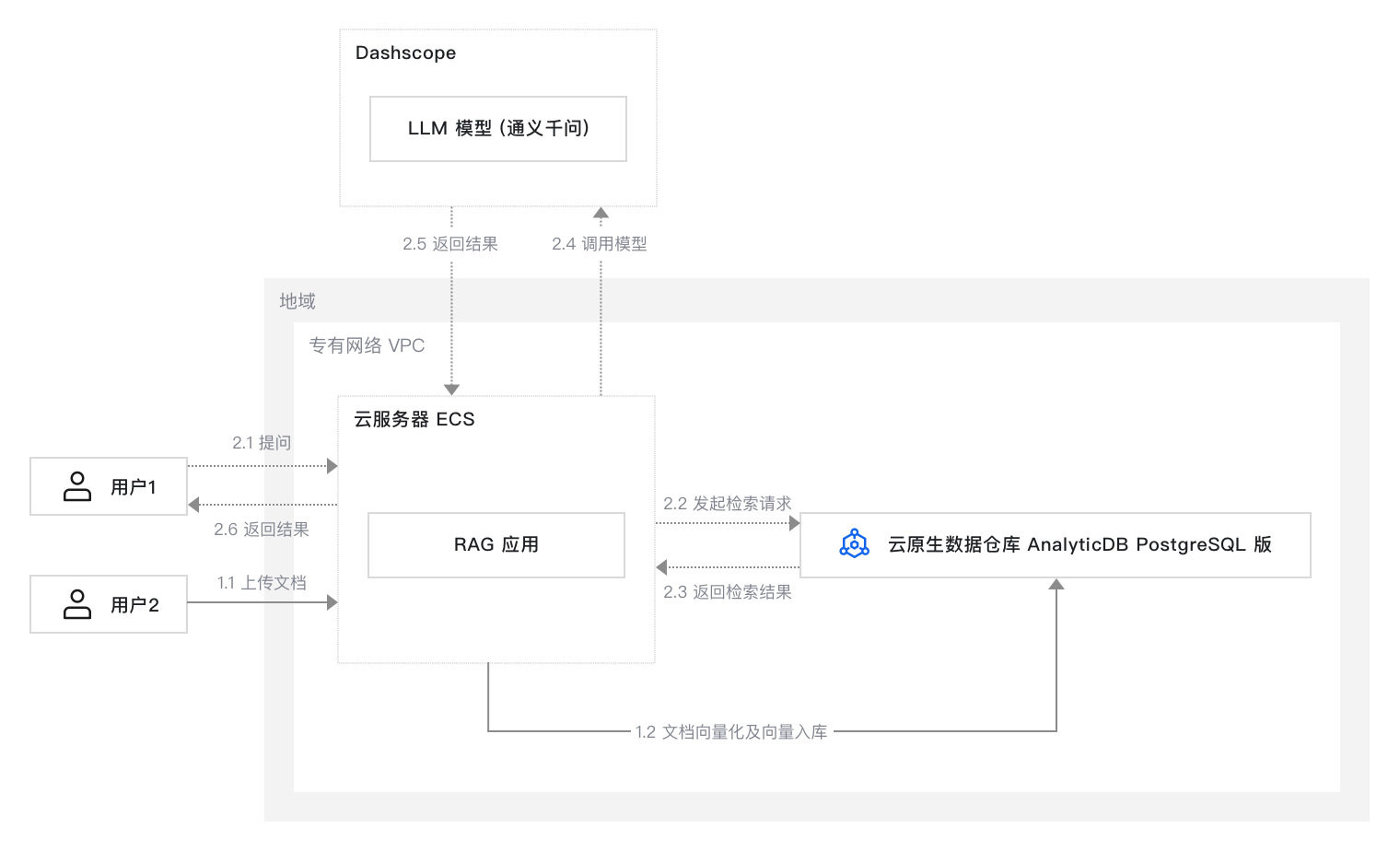
本方案在云服务器ECS上部署RAG应用。企业可以上传自己的私域知识数据,AnalyticDB PostgreSQL对数据进行向量化。当用户在智能问答系统发起提问后,在AnalyticDB PostgreSQL中检索相关数据,并调用DashScope提供的通义千问大语言模型,以自然语言形式生成准确且连贯的回答。
传统模型的知识是基于训练数据集的。对于训练数据集中没有的信息,模型的理解和回答不准确,甚至可能提供“虚假”信息。
传统大模型在训练后不会自动更新其知识库,信息易过时。
对于复杂问题,传统模型可能误解上下文,导致回答偏离主题或不够精确。


