
揭秘YouTube视频世界:利用Python和Beautiful Soup的独特技术
介绍 YouTube作为全球最大的视频分享平台,每天有数以亿计的视频被上传和观看。对于数据分析师、市场营销人员和内容创作者来说,能够获取YouTube视频的相关数据(如标题、观看次数、喜欢和不喜欢的数量等)是非常有价值的。本文将介绍如何使用Python编程语言和Beautiful Soup库来抓取Y...
请解释Python中的BeautifulSoup库以及它的主要用途。
BeautifulSoup是一个Python库,主要用于解析和提取网页中的数据。它能够将复杂的HTML文档转换为树形结构,以便用户可以轻松地查找、访问和修改其中的元素和属性。 BeautifulSoup的主要用途包括: 网页抓取(Web Scraping):BeautifulSoup常用于从网页中提...

Python爬虫实战:利用BeautifulSoup解析网页数据
随着互联网的发展,越来越多的数据被存储在各种网站上,而我们需要从这些网站中提取出有价值的信息。Python作为一种功能强大且易于学习的编程语言,拥有丰富的库来帮助我们实现数据爬取操作。其中,BeautifulSoup库就是一个非常优秀的工具,可以帮助我们轻松解析网页数据。首先,我们需要安装Beaut...

Python爬虫 Beautiful Soup库详解#4
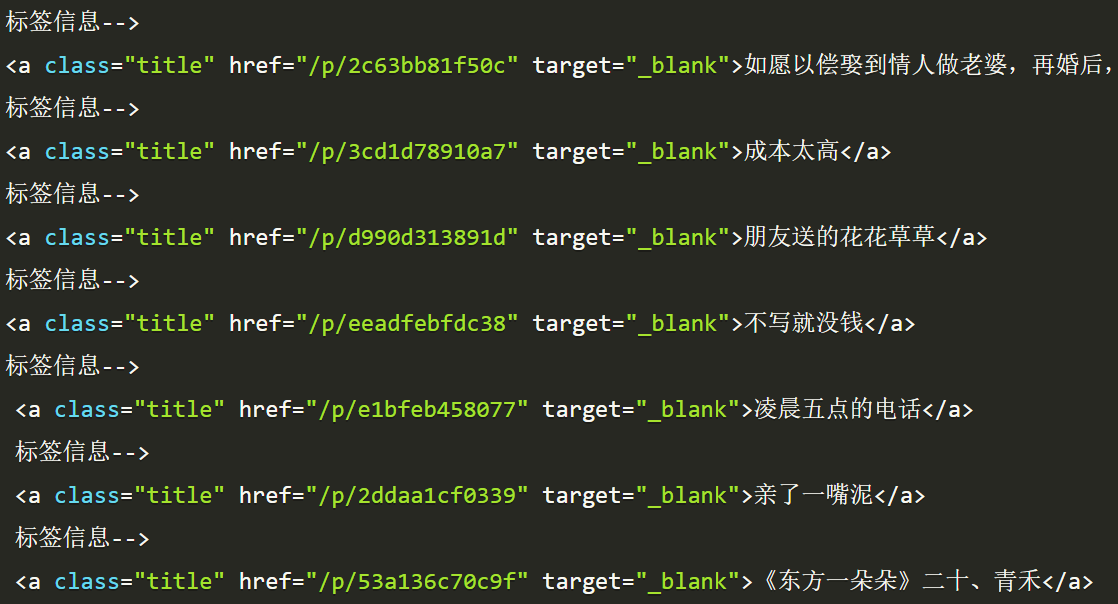
使用 Beautiful Soup 前面介绍了正则表达式的相关用法,但是一旦正则表达式写的有问题,得到的可能就不是我们想要的结果了。而且对于一个网页来说,都有一定的特殊结构和层级关系,而且很多节点都有 id 或 class 来作区分,所以借助它们的结构和属性来提取不也可以吗? 这一节中,我们就来介绍...
Python爬虫实战:利用BeautifulSoup解析网页数据
在网络信息爆炸的时代,获取并处理海量的网络数据成为了许多领域的必备技能。而Python作为一种功能强大且易于学习的编程语言,被广泛运用在数据采集和处理的领域。其中,利用Python开发网络爬虫程序可以帮助我们从互联网上快速、高效地获取所需的数据。Python中有许多优秀的第三方库可以辅助我们进行网络...
Python爬虫实战:利用Beautiful Soup解析网页数据
随着互联网信息的爆炸式增长,网络爬虫成为了获取各类信息的重要途径之一。而在爬虫开发过程中,数据解析则是至关重要的一环。Python作为一门强大的编程语言,其Beautiful Soup库提供了简洁易用的工具,可以帮助开发者轻松解析网页数据。首先,我们需要安装Beautiful Soup库。通过pip...
python中request请求库与BeautifulSoup解析库的用法
python中request请求库与BeautifulSoup解析库的用法request安装打开cmd窗口,检查python环境,需要python3.7版本及以上然后输入,下载requests库pip install requests -i http://pypi.douban.com/simple...
python爬虫入门篇:如何解析爬取到的网页数据?试下最简单的BeautifulSoup库!
一、前言前面笔记解析了如何使用requests模块向网站发送http请求,获取到网页的HTML数据。这篇我们来如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据。二、定义Beautiful Soup,简称bs4,是Python的一个HTML或XML的解析库,一般用它来从网页中...
Python + BeautifulSoup 采集
Python 是一种非常流行的编程语言,也是开发网络爬虫和数据采集工具的首选语言。在 Python 中,有许多第三方库可以用于网络爬虫和数据采集,比如 requests、beautifulsoup4、selenium 等。下面是一个简单的例子,使用 requests 库采集一个网页:import r...
Web爬虫开发指南:使用Python的BeautifulSoup和Requests库
Web爬虫是一种从互联网上获取数据的自动化工具,它可以用于抓取网页内容、提取信息和分析数据。Python提供了一些强大的库,其中BeautifulSoup和Requests是两个常用的工具,用于解析HTML内容和发起HTTP请求。本文将介绍如何使用BeautifulSoup和Requests库构建一...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







