[帮助文档] 如何创建Spark类型任务
SPARK任务类型用于执行Spark应用。本文为您介绍创建SPARK类型任务时涉及的参数。
[帮助文档] Paimon与Spark集成
E-MapReduce支持通过Spark SQL对Paimon进行读写操作。本文通过示例为您介绍如何通过Spark SQL对Paimon进行读写操作。

[帮助文档] 如何使用Arm节点运行Spark作业
EMR on ACK默认部署在X86架构的节点上,您也可以通过配置,将Spark作业运行在Arm类型的弹性容器实例(ECI)上。本文为您介绍如何使用Arm节点运行Spark作业。
[帮助文档] 如何在Spark3服务中开启Native引擎,有哪些限制
本文为您介绍Spark Native引擎在使用过程中的限制,以及如何在Spark3服务中开启Native引擎。
[帮助文档] Spark如何读取Hologres表数据
本文为您介绍Spark如何读取Hologres表数据。
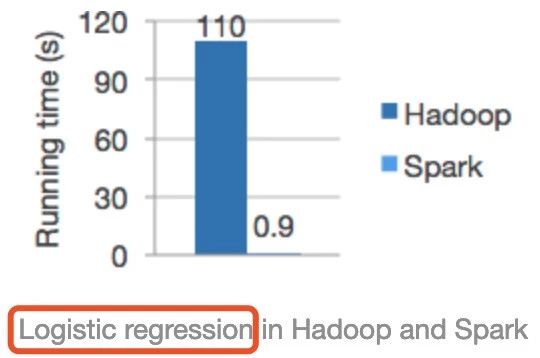
重要 | Spark和MapReduce的对比
【前言:笔者将分两篇文章进行阐述Spark和MapReduce的对比,首篇侧重于"宏观"上的对比,更多的是笔者总结的针对"相对于MapReduce我们为什么选择Spark"之类的问题的几个核心归纳点;次篇则从任务处理级别运用的并行机制方面上对比,更多的是让大家对Spark为什么比MapReduce快...
spark 和 mapreduce 的对比
spark 和 mapreduce 的对比
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark分布式
- apache spark Hadoop
- apache spark Python
- apache spark大数据技术
- apache spark算子
- apache spark动作
- apache spark hudi
- apache spark集成
- apache spark cdc
- apache spark flink
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark程序
- apache spark操作