
Spark面试题(五)——数据倾斜调优
1、数据倾斜数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。数据倾斜俩大直接致命后果。1、数据倾斜直接会导致一种情况:Out Of Memory。2、运行速度慢。主要是发生在Sh...
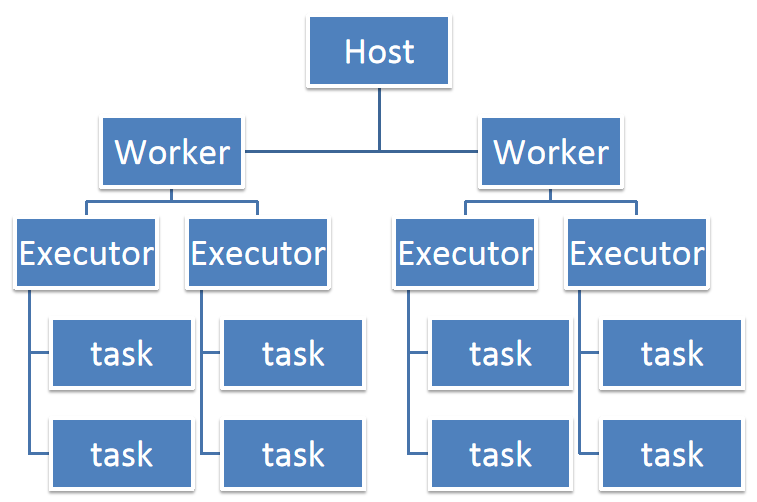
Spark面试题(六)——Spark资源调优
1、资源运行情况2、资源运行中的集中情况(1)实践中跑的Spark job,有的特别慢,查看CPU利用率很低,可以尝试减少每个executor占用CPU core的数量,增加并行的executor数量,同时配合增加分片,整体上增加了CPU的利用率,加快数据处理速度。&#x...

Spark面试题(七)——Spark程序开发调优
1、程序开发调优 :避免创建重复的RDD需要对名为“hello.txt”的HDFS文件进行一次map操作,再进行一次reduce操作。也就是说,需要对一份数据执行两次算子操作。错误的做法:对于同一份数据执行多次算子操作时,创建多个RDD。//这里执行了两次textFile方法,针对同一个HDFS文件...
Spark面试题(八)——Spark的Shuffle配置调优
1、Shuffle优化配置 -spark.shuffle.file.buffer默认值:32k参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark Hadoop
- apache spark Python
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作