高吞吐量分布式消息系统:深入了解 Apache Kafka
在现代的分布式系统中,消息传递已经成为实现异步通信、日志记录和事件驱动架构的核心。Apache Kafka,作为一款高吞吐量、持久性和分布式的消息系统,正被越来越多的企业和开发者用于构建实时数据流和事件处理平台。本文将为您详细介绍 Apache Kafka 的核心概念、特性以及在分布式架构中的应用。...
Spring Boot与 Kafka实现高吞吐量消息处理大规模数据问题
一、引言 现代数据量越来越庞大对数据处理的效率提出了更高的要求。Apache Kafka是目前流行的分布式消息队列之一。Spring Boot是现代Java应用程序快速开发的首选框架。综合使用Spring Boot和Apache Kafka可以实现高吞吐量消息处理。 二、Apache Kafka技术...

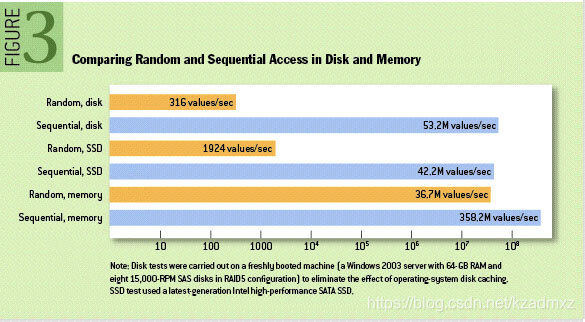
网易二面:Kafka为什么吞吐量大、速度快??
Kafka是大数据领域无处不在的消息中间件,目前广泛使用在企业内部的实时数据管道,并帮助企业构建自己的流计算应用程序。Kafka虽然是基于磁盘做的数据存储,但却具有高性能、高吞吐、低延时的特点,其吞吐量动辄几万、几十上百万。但是很多使用过Kafka的人,经常会被问到这样一个问题,Kafka为什么速度...
【Kafka】(十)Kafka 如何实现高吞吐量
1.顺序读写kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写生产者负责写入数据,Kafka会将消息持久化到磁盘,保证不会丢失数据,Kafka采用了俩个技术提高写入的速度。1.顺序写...
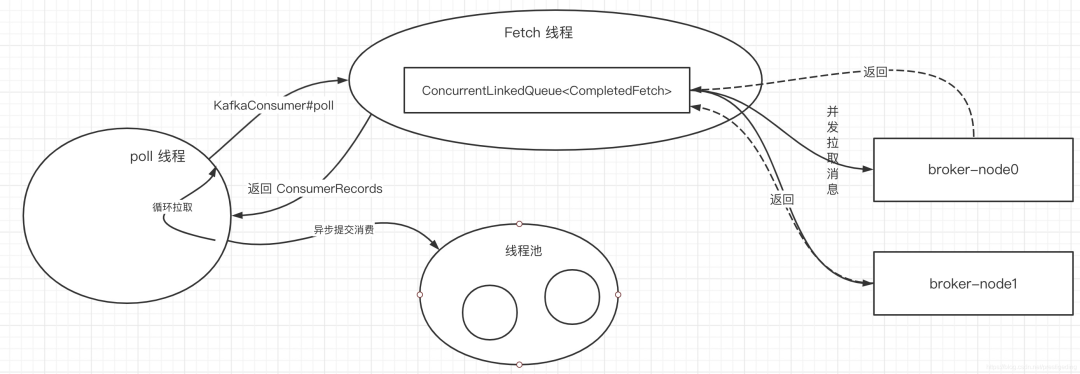
答读者问:Kafka顺序消费吞吐量下降该如何优化?
1、Kafka顺序消费模型在探究Kafka顺序消费模型时,首先我们再来回顾一下Kafka消费端端消息拉取机制,只有真正理解其消息拉取线程模型,才能构建最优的线程模型。1.1 Kafka消息拉取模型kafka消费端的线程拉取模型如下图所示:图画的比较简单,但里面蕴含的精髓不能不讲清楚,涉及到几个核心线...
Kafka中如何提高远程用户吞吐量?
Kafka中如何提高远程用户吞吐量?
Kafka的吞吐量为什么很高?
Kafka的吞吐量为什么很高?
怎么验证kafka的高吞吐量?
怎么验证kafka的高吞吐量?
11月21日云栖精选夜读 | 20条关于Kafka集群应对高吞吐量的避坑指南
Apache Kafka是一款流行的分布式数据流平台,它已经广泛地被诸如New Relic(数据智能平台)、Uber、Square(移动支付公司)等大型公司用来构建可扩展的、高吞吐量的、高可靠的实时数据流系统。 热点热议 20条关于Kafka集群应对高吞吐量的避坑指南 作者:技术小能手 发...
20条关于Kafka集群应对高吞吐量的避坑指南
Apache Kafka是一款流行的分布式数据流平台,它已经广泛地被诸如New Relic(数据智能平台)、Uber、Square(移动支付公司)等大型公司用来构建可扩展的、高吞吐量的、高可靠的实时数据流系统。 例如,在New Relic的生产环境中,Kafka群集每秒能够处理超过1500万条消息,...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







云消息队列 Kafka 版您可能感兴趣
- 云消息队列 Kafka 版数据
- 云消息队列 Kafka 版python
- 云消息队列 Kafka 版hologres
- 云消息队列 Kafka 版java
- 云消息队列 Kafka 版字段
- 云消息队列 Kafka 版flink
- 云消息队列 Kafka 版mysql
- 云消息队列 Kafka 版功能
- 云消息队列 Kafka 版阿里云
- 云消息队列 Kafka 版组件
- 云消息队列 Kafka 版cdc
- 云消息队列 Kafka 版消费
- 云消息队列 Kafka 版分区
- 云消息队列 Kafka 版集群
- 云消息队列 Kafka 版配置
- 云消息队列 Kafka 版报错
- 云消息队列 Kafka 版同步
- 云消息队列 Kafka 版apache
- 云消息队列 Kafka 版安装
- 云消息队列 Kafka 版消息队列
- 云消息队列 Kafka 版topic
- 云消息队列 Kafka 版消息
- 云消息队列 Kafka 版sql
- 云消息队列 Kafka 版入门
- 云消息队列 Kafka 版消费者
- 云消息队列 Kafka 版实战
- 云消息队列 Kafka 版原理