E-MapReduce Hive如何访问Delta Lake和Hudi数据
E-MapReduce Hive如何访问Delta Lake和Hudi数据
E-MapReduce Hive如何访问EMR Phoenix的数据
E-MapReduce Hive如何访问EMR Phoenix的数据
E-MapReduce Doctor都会采集哪些数据
E-MapReduce Doctor都会采集哪些数据
E-MapReduce hdfs上的数据怎么传到OSS的bucket里
E-MapReduce hdfs上的数据怎么传到OSS的bucket里
E-MapReduce旧版控制台中数据开发在新版本中没有
E-MapReduce旧版控制台中数据开发在新版本中没有
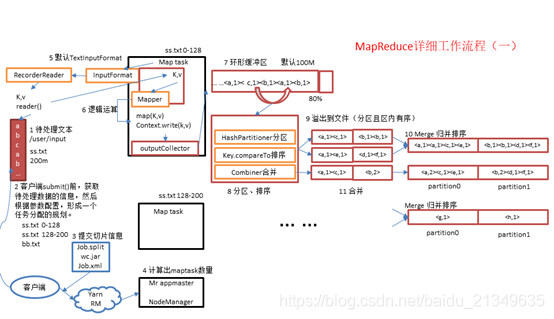
MapReduce框架--InputFormat数据输入--切片优化(11)
MapReduce框架原理这里的原理比较绕,搞了好久。还有点蒙。现在梳理下,防止忘记。1.MapReduce工作流程2)流程详解上面的流程是整个mapreduce最全工作流程,但是shuffle过程只是从第7步开始到第15步结束,具体shuffle过程详解,如下:1)maptask收集...
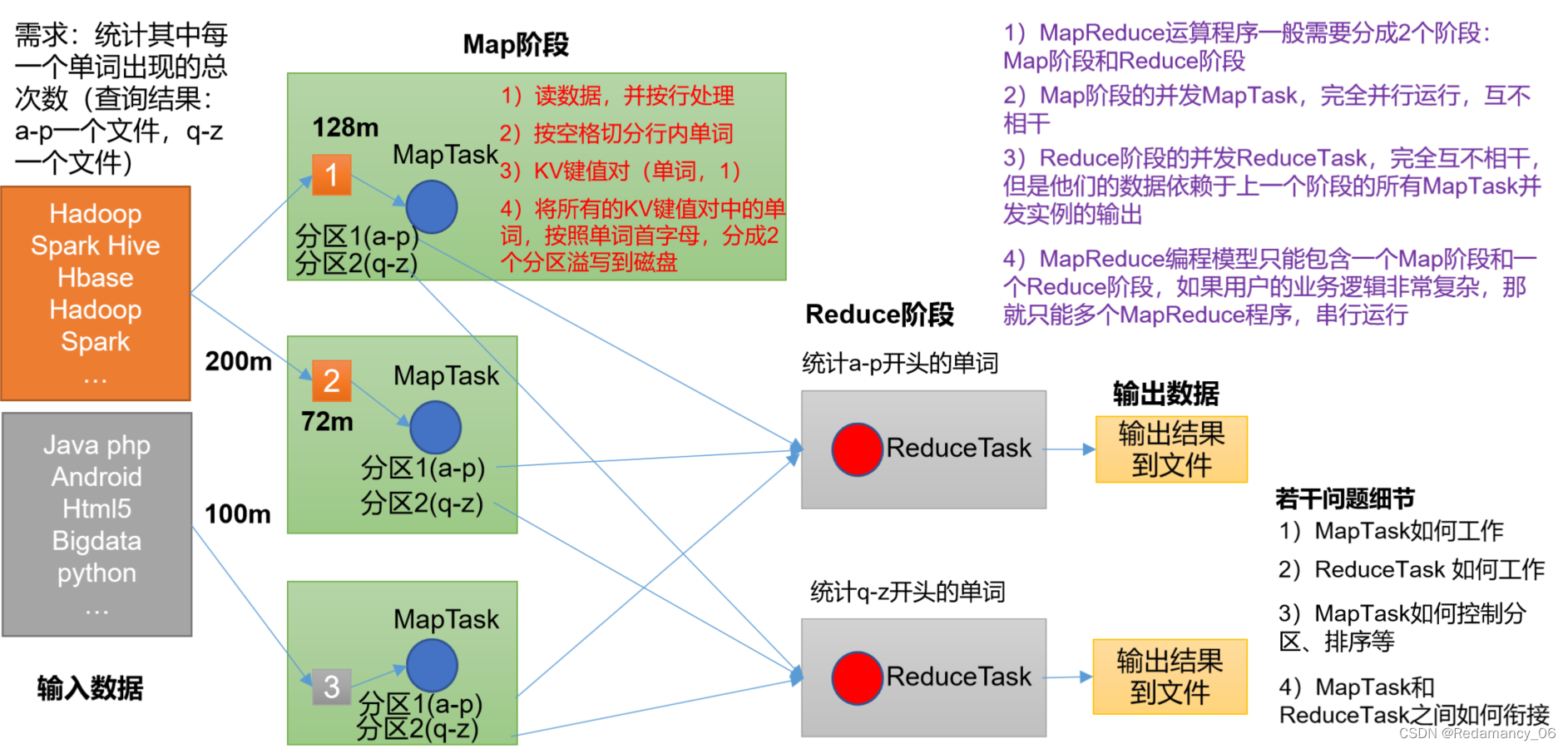
Hadoop中的MapReduce概述、优缺点、核心思想、编程规范、进程、官方WordCount源码、提交到集群测试、常用数据序列化类型、WordCount案例实操
@[toc]11.MapReduce概述11.1MapReduce定义 MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Ha...

【Druid】(九)E-MapReduce Druid 集群集成 Superset(数据探查与可视化平台 )2
四、使用Superset1.登录Superset。在浏览器地址栏中输入http://emr-header-1:18088,按回车,打开Superset登录界面,默认用户名和密码均为admin,请您登录后及时修改密码。2.添加E-MapReduce Druid集群。登录后默认为英文界面,可单击右上角的...
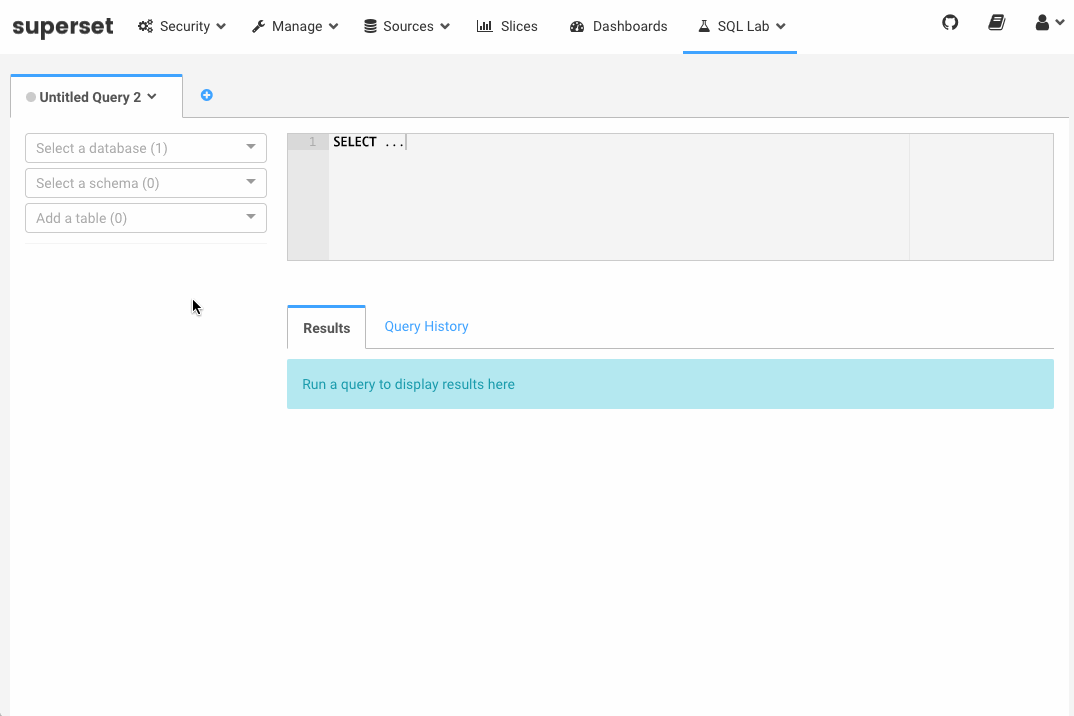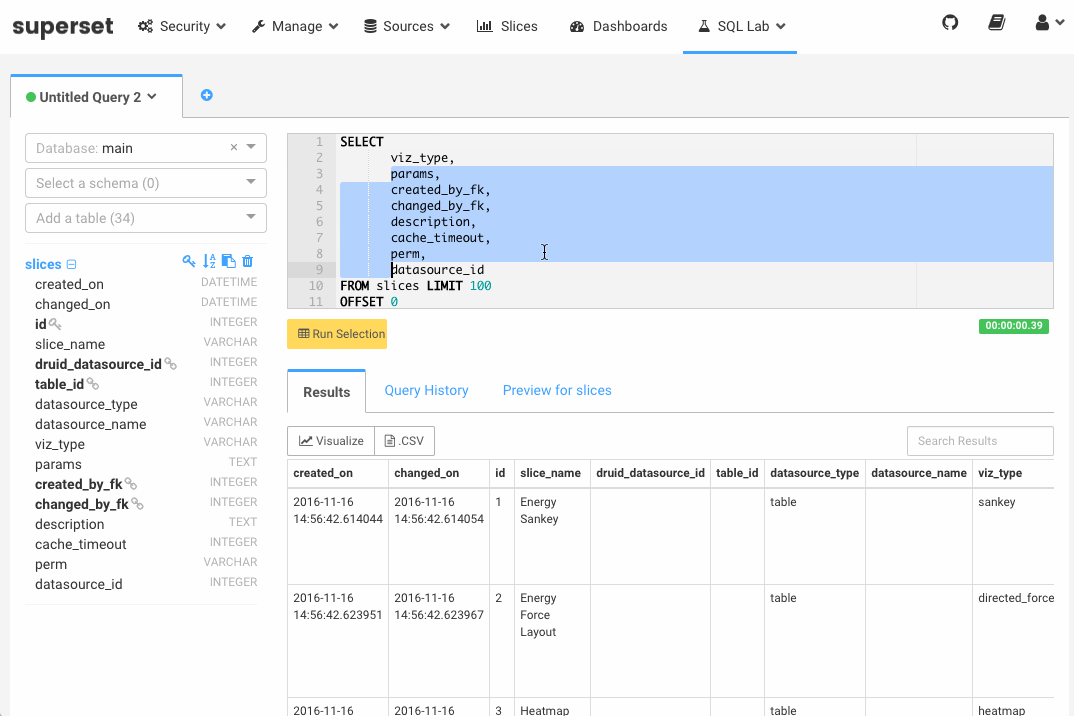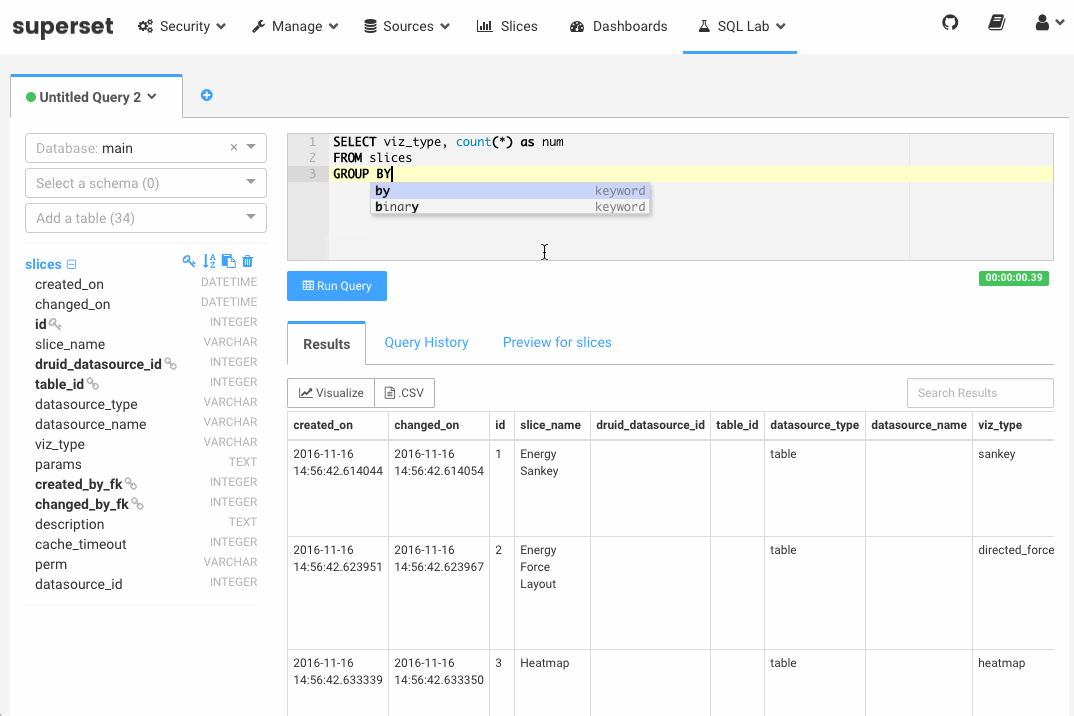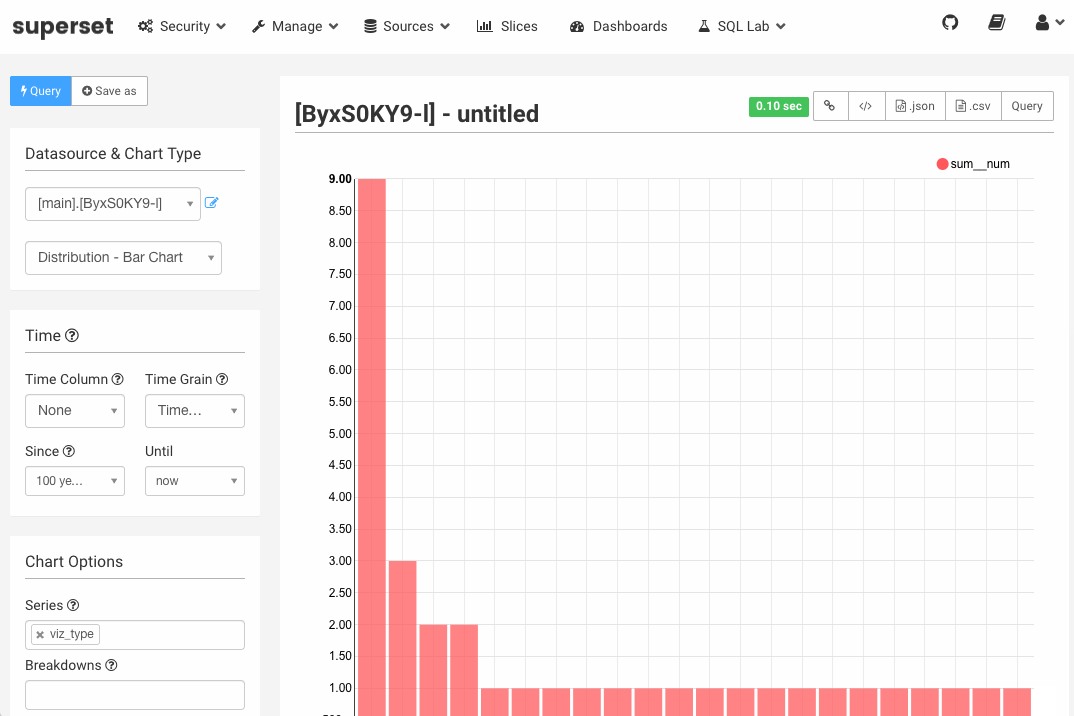
【Druid】(九)E-MapReduce Druid 集群集成 Superset(数据探查与可视化平台 )1
文章目录一、前言二、什么是 Apache Superset?三、前提条件四、使用Superset一、前言E-MapReduce Druid集群集成了Superset工具。Superset对E-MapReduce Druid做了深度集成,同时也支持多种关系型数据库。由于E-MapReduce Drui...
MapReduce的reduce中Iterable<Text> value中数据的排序规则
请求在MR程序中,reduce阶段,reduce方法reduce(Text key, Iterable value,Reducer.Context context),同一个key的velue迭代器列表中value的排序规则,是根据字符串的hash排序吗?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子

开源大数据平台 E-MapReduce数据相关内容
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce实践
- 开源大数据平台 E-MapReduce ecs
- 开源大数据平台 E-MapReduce服务器
- 开源大数据平台 E-MapReduce访问
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce emr
- 开源大数据平台 E-MapReduce机器
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce信息
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce map