[帮助文档] SparkonMaxCompute访问云数据库HBase的配置方法_云原生大数据计算服务 MaxCompute(MaxCompute)
本文为您介绍Spark on MaxCompute访问云数据库HBase的配置方法。
Spark + HBase 架构是什么样的?
Spark + HBase 架构是什么样的?

hbase预分区个数和spark过程中的reduce个数相同吗?
hbase预分区个数和spark过程中的reduce个数相同吗?
Maxcompute Spark 访问 阿里云 Hbase
引子 本来这个东西是没啥好写的,但是在帮客户解决问题的时候,发现链路太长,不能怪客户弄不出来,记录一下 需求列表 MaxCompute Spark包 (写文章时刻为版本 0.32.1, 请自行更新,本文不是文档) Spark 配置 spark.hadoop.odps.project.name = &...
如何使用MaxCompute Spark读写阿里云Hbase
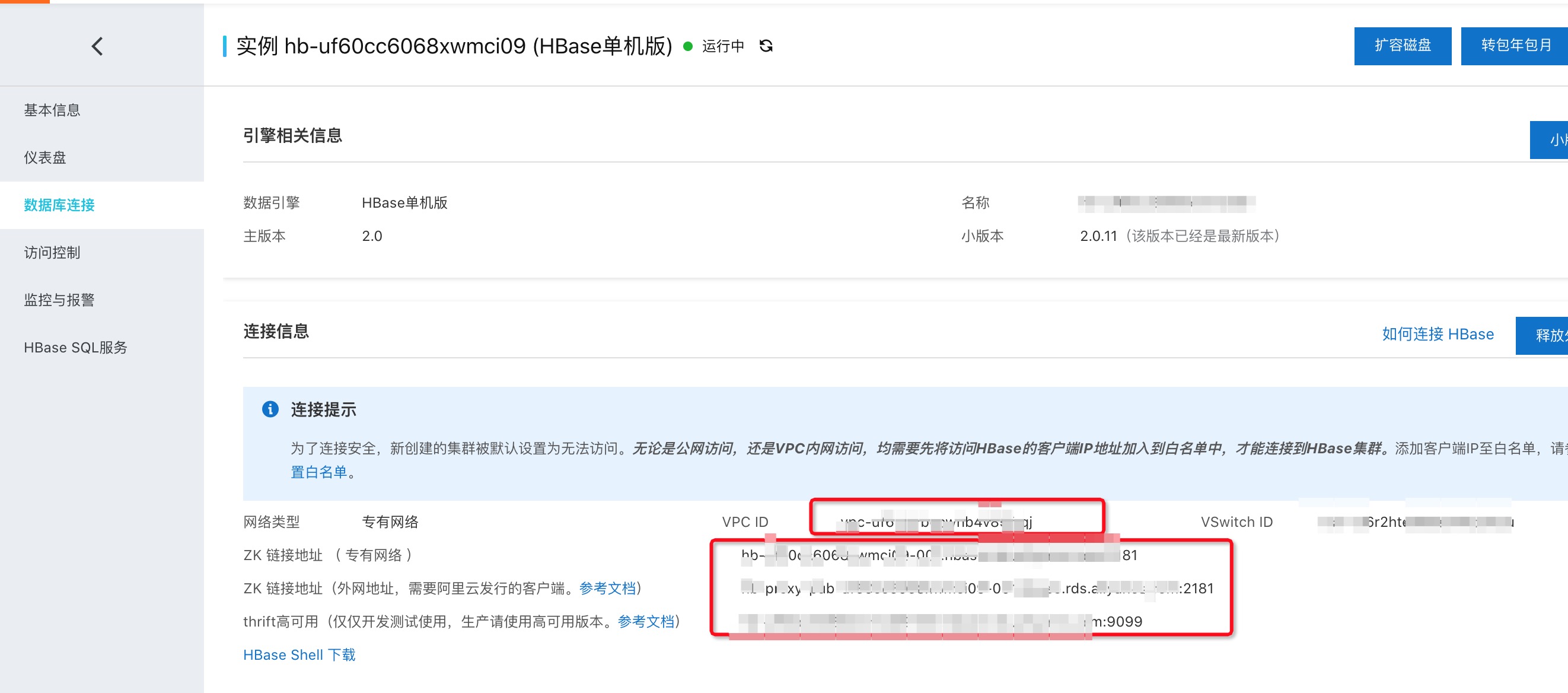
背景 Spark on MaxCompute可以访问位于阿里云VPC内的实例(例如ECS、HBase、RDS),默认MaxCompute底层网络和外网是隔离的,Spark on MaxCompute提供了一种方案通过配置spark.hadoop.odps.cupid.vpc.domain.list来...
spark streaming 流式计算-----容错(hbase幂等性修改)
在做流式计算过程中,最复杂最难做的莫过于数据幂等性修改操作的设计。先解释一下概念【幂等性操作】,幂等性概念来源于数学专业表示对一个表达式做多次相同的操作,表达式不会改变。例如:逻辑回归中的Sigmod函数,n次求导之后依然坚挺。在流式计算中容错设计也要求工程设计有数据幂等性设计,特别针对流式计算中对...
HBase实操:Spark-Read-HBase-Snapshot-Demo 分享
前言:之前给大家分享了Spark通过接口直接读取HBase的一个小demo:HBase-Spark-Read-Demo,但如果在数据量非常大的情况下,Spark直接扫描HBase表必然会对HBase集群造成不小的压力。基于此,今天再给大家分享一下Spark通过Snapshot直接读取HBase HF...
hbase预分区个数和spark过程中的reduce个数相同么
hbase预分区个数和spark过程中的reduce个数相同么
请问一下 spark 可以直接读取hbase 数据嘛? 不通过 hive中间层
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。点击链接欢迎加入感兴趣的技术领域群。
请教各位大神,hbase2.0 spark批量导入时报这个,有人碰到过么
请教各位大神,hbase2.0 spark批量导入时报这个,有人碰到过么。已经按rowkey排过序了 本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。 https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。






云数据库HBase版您可能感兴趣
- 云数据库HBase版表
- 云数据库HBase版dataworks
- 云数据库HBase版方法
- 云数据库HBase版安装
- 云数据库HBase版linux
- 云数据库HBase版教程
- 云数据库HBase版集群部署
- 云数据库HBase版配置
- 云数据库HBase版分布式
- 云数据库HBase版hdfs
- 云数据库HBase版数据
- 云数据库HBase版shell
- 云数据库HBase版hadoop
- 云数据库HBase版集群
- 云数据库HBase版hive
- 云数据库HBase版flink
- 云数据库HBase版报错
- 云数据库HBase版操作
- 云数据库HBase版数据库
- 云数据库HBase版设计
- 云数据库HBase版存储
- 云数据库HBase版大数据
- 云数据库HBase版phoenix
- 云数据库HBase版查询
- 云数据库HBase版学习笔记
- 云数据库HBase版技术