[帮助文档] 部署作业
完成作业开发后,您需要将作业部署。部署将开发和生产隔离,部署后不影响运行中的作业,只有(重新)启动后才会正式上线运行。本文为您介绍如何部署SQL作业、JAR作业和Python作业。
[帮助文档] Flink动态扩缩容与参数动态更新
动态更新Flink作业参数可以实现更快的参数配置生效,减少作业启停对业务的中断时间,方便进行TM动态扩缩容和系统检查点的排查。

[帮助文档] 作业资源配置
作业启动前或者作业上线后,您可以配置和修改作业资源,本文为您介绍如何配置和修改基础模式和专家模式的作业资源。
[帮助文档] 作业引擎版本升级
Flink作为当前最活跃的流计算引擎之一,版本更新速度相对较快。及时升级作业到新版本,可以使用新版本的功能和特性。本文将为您介绍如何升级实时计算Fllink版作业的引擎版本。
[帮助文档] 本地运行和调试Flink作业
本文为您介绍如何在开发者本地环境中运行和调试包含阿里云实时计算Flink版连接器的作业,以便快速验证代码的正确性,快速定位和解决问题,并节省云上成本。
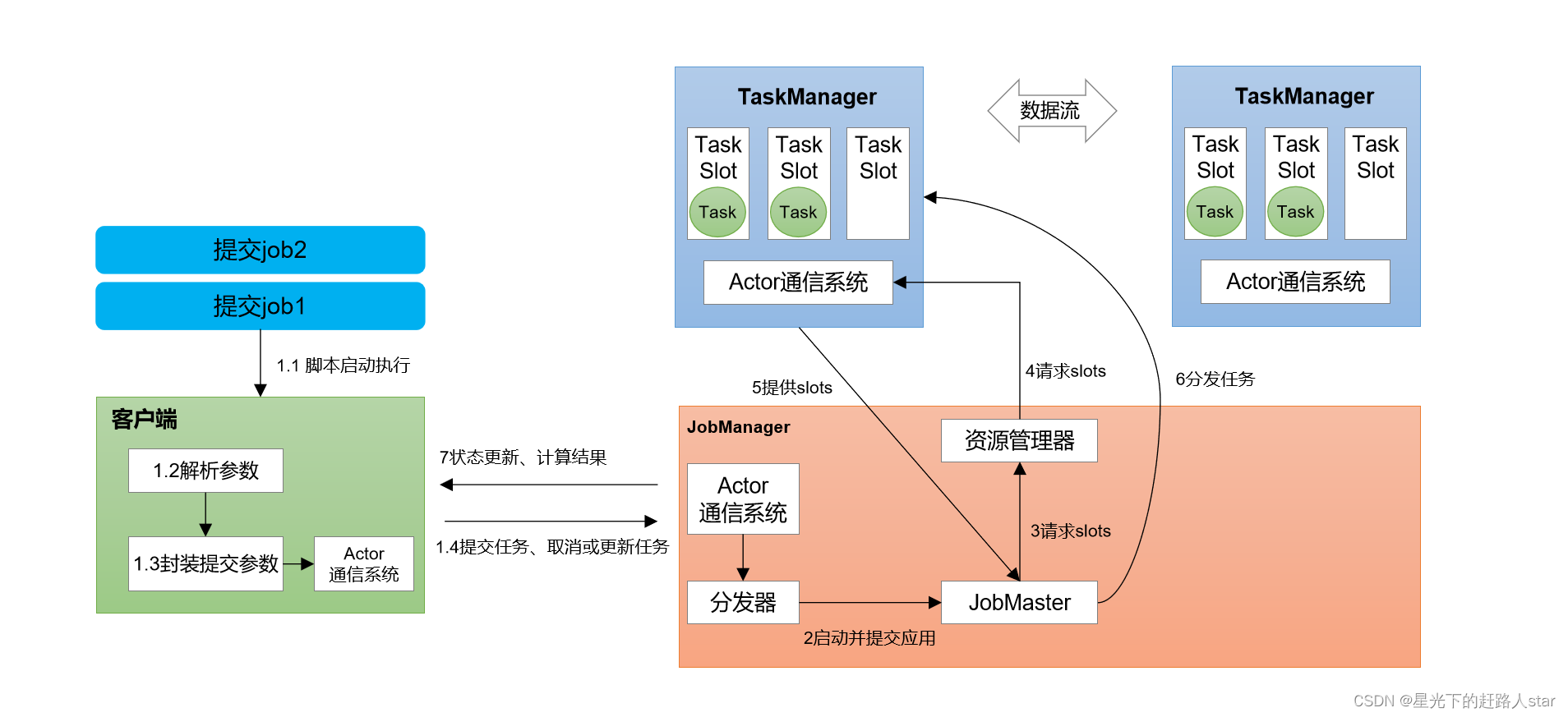
Fink--3、Flink运行时架构(并行度、算子链、任务槽、作业提交流程)
1、系统架构(以Standalone会话模式为例)1、作业管理器(JobManager)JobManager是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。也就是说,每个应用都应该被唯一的JobManager所控制执行。JobManager又包含三个不同的组件(1)...
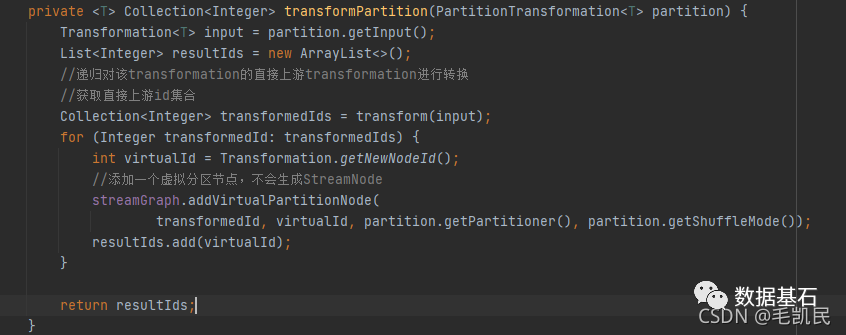
【万字长文】详解Flink作业提交流程(二)
2.1.3 虚拟 Transformation 的转换虚拟的 Transformation 生成的时候不会转换为 SteramNode,而是添加为虚拟节点。private void addEdgeInternal(Integer upStreamVertexID, Integer downStrea...

【万字长文】详解Flink作业提交流程(一)
一、提交流程Flink 作业在开发完毕之后,需要提交到 Flink 集群执行。ClientFronted 是入口,触发用户开发的 Flink 应用 Jar 文件中的 main 方法,然后交给 PipelineExecutor(流水线执行器,在 FlinkClient 升成 JobGraph 之后,将...
Flink作业在正常流程下有几个状态?分别是什么?
Flink作业在正常流程下有几个状态?分别是什么?
Apache Flink流作业提交流程分析
用户编写的程序逻辑需要提交给Flink才能得到执行。本文来探讨一下客户程序如何提交给Flink。鉴于用户将自己利用Flink的API编写的逻辑打成相应的应用程序包(比如Jar)然后提交到一个目标Flink集群上去运行是比较主流的使用场景,因此我们的分析也基于这一场景进行。 Flink的API针对不同...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践
更多




实时计算 Flink版作业相关内容
- 实时计算 Flink版作业重启
- 实时计算 Flink版数据源作业
- 作业实时计算 Flink版
- 实时计算 Flink版分表作业
- 实时计算 Flink版参数作业
- 实时计算 Flink版作业报错
- 实时计算 Flink版办法作业
- 实时计算 Flink版application作业
- 实时计算 Flink版jar作业
- 实时计算 Flink版作业connector
- 实时计算 Flink版作业包依赖
- 实时计算 Flink版作业依赖
- 实时计算 Flink版作业udtf
- 实时计算 Flink版sql作业udtf
- 实时计算 Flink版作业超时
- 实时计算 Flink版作业jm
- 实时计算 Flink版streaming作业如何解决
- 实时计算 Flink版作业异常
- 实时计算 Flink版streaming作业
- 实时计算 Flink版作业如何解决
- 实时计算 Flink版cli作业
- 实时计算 Flink版部署作业
- 实时计算 Flink版作业参考
- 实时计算 Flink版作业job
- 实时计算 Flink版作业延时
- 实时计算 Flink版作业图
- 实时计算 Flink版作业火焰图
- 实时计算 Flink版重启作业
- 实时计算 Flink版命令作业
- 实时计算 Flink版作业怎么解决
- 实时计算 Flink版作业部署
- 实时计算 Flink版作业目标
- 实时计算 Flink版作业running
- 实时计算 Flink版作业包
- 实时计算 Flink版运行时作业
- 实时计算 Flink版算子链作业
- 实时计算 Flink版作业初始化
- 实时计算 Flink版state作业
- 实时计算 Flink版savepoint作业
- 实时计算 Flink版session作业
- 集群实时计算 Flink版作业
- 实时计算 Flink版作业into
- 实时计算 Flink版hudi作业
- 实时计算 Flink版作业tm
- 实时计算 Flink版作业log
- 实时计算 Flink版作业指标
- 实时计算 Flink版作业监控指标
- 实时计算 Flink版作业webui
实时计算 Flink版更多作业相关
实时计算 Flink版您可能感兴趣
- 实时计算 Flink版数据
- 实时计算 Flink版合流
- 实时计算 Flink版窗口
- 实时计算 Flink版算子
- 实时计算 Flink版重跑
- 实时计算 Flink版方案
- 实时计算 Flink版多表
- 实时计算 Flink版es
- 实时计算 Flink版函数
- 实时计算 Flink版同步
- 实时计算 Flink版报错
- 实时计算 Flink版任务
- 实时计算 Flink版oracle
- 实时计算 Flink版版本
- 实时计算 Flink版表
- 实时计算 Flink版配置
- 实时计算 Flink版设置
- 实时计算 Flink版 CDC
- 实时计算 Flink版模式
- 实时计算 Flink版运行
- 实时计算 Flink版数据库
- 实时计算 Flink版连接
- 实时计算 Flink版库
- 实时计算 Flink版全量
- 实时计算 Flink版参数
- 实时计算 Flink版日志
- 实时计算 Flink版集群