
D001.6 Docker搭建Hadoop集群(资源篇)
0x01 Dockerfile的编写1. Dockerfile文件FROM ubuntu MAINTAINER shaonaiyi shaonaiyi@163.com ENV BUILD_ON 2017-10-12 RUN apt-get update -qqy RUN apt-get -qqy i...
基于Docker一键部署大规模Hadoop集群及设计思路
一、背景:随着互联网的发展、互联网用户的增加,互联网中的数据也急剧膨胀。每天产生的数据量数以万计,本地文件系统和单机CPU已无法满足存储和计算要求。Hadoop分布式文件系统(HDFS)是海量数据存储的重要技术,它将数据存储在多个从节点上,对这些节点的硬件资源进行统一管理与分配,并向客户端提供文件系...

Docker一键部署Hadoop心得(一)
最近一直在折腾使用docker一键部署全分布式hadoop集群,虽然一键部署的脚本写好了并且可以成功运行出各个节点,但在运行一个wordcount实例时出现了错误,错误如下:java.io.IOException: org.apache.hadoop.yarn.exceptions.InvalidR...
使用阿里云服务器通过Docker环境搭建Hadoop集群常见的问题
使用云服务器利用Docker环境搭建Hadoop集群常见的问题通过同学介绍了解到了阿里云服务器,由于在虚拟机上搭建Hadoop占用太多的内存,且运行速度较慢,所以尝试使用服务器进行搭建。我选择的是Linux的centos7,使用xshell工具连接服务器,操作更加方便。在此,我主要是描述一下,在使用...
BigData:大数据开发的简介、核心知识(linux基础+Java/Python编程语言+Hadoop{HDFS、HBase、Hive}+Docker)、经典场景应用之详细攻略
大数据简介 大数据(big data),IT行业术语,是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。Gartn...
Hadoop Spark docker swarm其中pyspark给出BlockMissingException但文件很好
基于https://github.com/gotthardsen/docker-hadoop-spark-workbench/tree/master/swarm我有一个带有hadoop,spark,hue和jupyter笔记本设置的docker swarm设置。使用Hue我将文件上传到hdfs,我没...
Docker生态会重蹈Hadoop的覆辙吗?
今晨在微信组中大家讨论了一篇文章,刚好和第三期云栖说《Hadoop是否已经过时》立意相似。不完全认同作者观点,发出共享以及思考。目测微信组从中午一直吵到现在了,果然是理越辩越明。文章来自科技头条微信号,作者是品刀客。原文链接见此处。目录一、Docker的兴起和Hadoop何其相似二、大数据从狂热走向...
Hadoop HDFS分布式文件系统Docker版
一、Hadoop文件系统HDFS 构建单节点的伪分布式HDFS 构建4个节点的HDFS分布式系统 nameNode secondnameNode datanode1 datanode2 其中 datanode2动态节点,在HDFS系统运行时,==动态加入==。 二、Mac docker环境 通常...
基于Docker快速搭建多节点Hadoop集群
基于Docker快速搭建多节点Hadoop集群 【编者的话】Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中。这篇教程介绍了利用Docker在单机上快速搭建多节点Hadoop集群的详细步骤。作者在发现目前的Hadoop on Docker项目所存在的问题之后,...
docker一键部署hadoop心得(二)
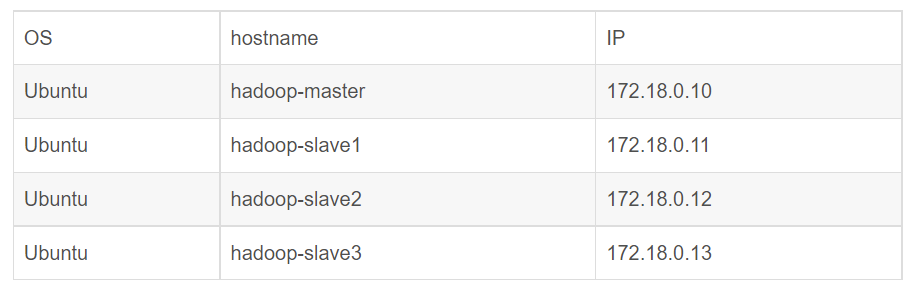
今天在运行MapReduce程序时,虽然wordcount实例运行成功了,但后面出现了重新使用历史服务器失败的错误 17/12/22 13:33:19 INFO ipc.Client: Retrying connect to server: hadoop-slave1/172.18.0.11:454...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








