
一日一技:从 Scrapy 学习模块导入技巧
截图:产品经理我们平时导入第三方模块的时候,一般使用的是import关键字,例如:import scrapy from scrapy.spider import Spider但是如果各位同学看过 Scrapy 的settings.py文件,就会发现里面会通过字符串的方式来指定 pipeline 和 ...
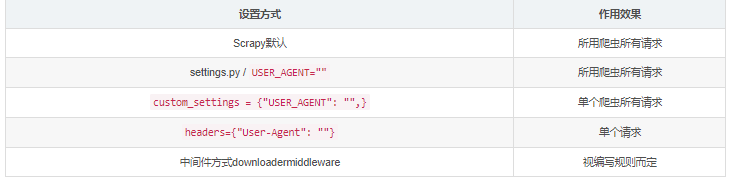
Python爬虫:关于scrapy模块的请求头
内容简介使用scrapy写爬虫的时候,会莫名其妙的被目标网站拒绝,很大部分是浏览器请求头的原因。现在一起来看看scrapy的请求头,并探究设置方式工具准备开发环境python2.7 + scrapy 1.1.2测试请求头网站:https://httpbin.org/get?show_env=1jso...
Scrapy管道mysql连接模块错误
我无法通过管道到本地数据库运行scrapy。我已经安装了mysql-connector-python 8.0.19,并且能够在同一项目中但在Scrapy管道之外将数据写入数据库。有人可以帮忙吗,我不知道为什么它不起作用。 当我尝试通过scrapy管道发送数据时,出现以下错误: [twisted] C...
5、web爬虫,scrapy模块,解决重复ur——自动递归url
【百度云搜索:http://www.lqkweb.com】【搜网盘:http://www.swpan.cn】 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 记录url可以是缓存,或者数据库,如果保存数据库按照以下方式: id ...
4、web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
转载自:https://www.jianshu.com/p/8f22cace85c7 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需要导入模块:from scrapy.selector import HtmlXPathSelec...
3、web爬虫,scrapy模块介绍与使用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services )...
2、web爬虫,scrapy模块以及相关依赖模块安装
当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip install Scrapy 手动源码安装,比较麻烦要自己手动安装scrapy模块以及依赖模块 安装以下模块 1、lxml-3.8.0.tar....
scrapy爬虫加载API,配置自定义加载模块
当我们在scrapy中写了几个爬虫程序之后,他们是怎么被检索出来的,又是怎么被加载的?这就涉及到爬虫加载的API,今天我们就来分享爬虫加载过程及其自定义加载程序。 SpiderLoader API 该API是爬虫实例化API,主要实现一个类SpiderLoader class scrap...
scrapy中数据处理的两个模块:ItemPipeline与Exporter
scrapy提供了如题两个模块来扩展我们的数据处理方式,其中Item Pipeline功能有数据清洗、效验、过滤、存库的作用,Exporter用于扩展scrapy导出数据的格式。 Item Pipeline item pipeline在scrapy项目文件下的pipeline.py文件中,...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子

