Spark-编程进阶(Scala版)
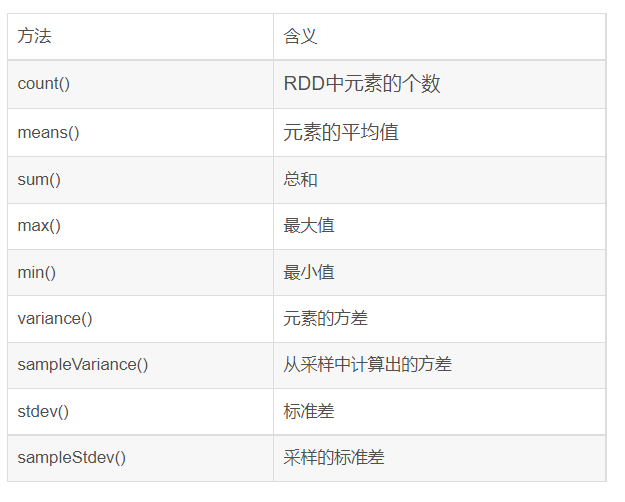
累加器累加器提供了将工作节点中的值聚合到驱动器程序中的简单语法。累加器的一个常见用法是在调测时对作业执行过程中的时间进行计数。例:累加空行val sc = new SparkContext() val file = sc.textFile("file.txt") val blankLines = s...

Spark RDD算子进阶(转换算子、行动算子、缓存、持久化)(下)
3. 持久化持久化,也就是将 RDD 的数据缓存到内存中/磁盘中,以后无论对这个RDD做多少次计算,都是直接取这个RDD的持久化的数据,比如从内存中或者磁盘中,直接提取一份数据。可以使用 persist()函数来进行持久化,一般默认的存储空间是在内存中,如果内存不够就会写入磁盘中。persist 持...

Spark RDD算子进阶(转换算子、行动算子、缓存、持久化)(中)
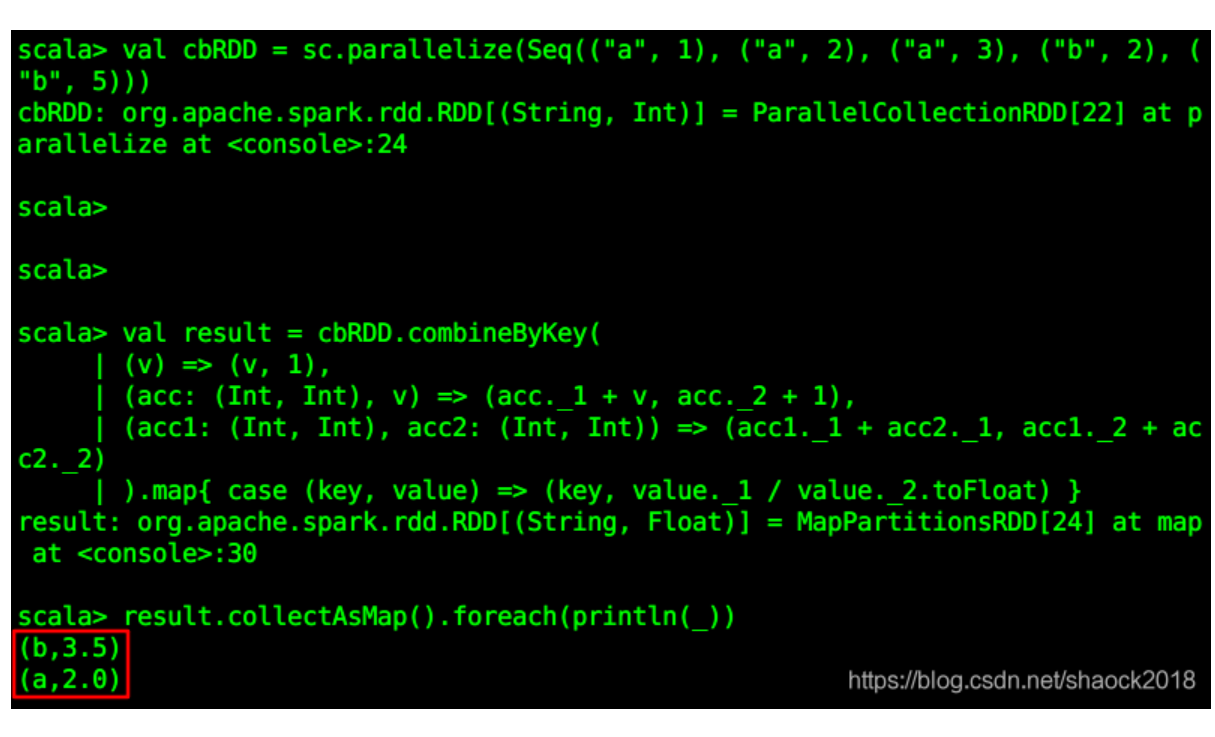
请看下面的例子(根据相同键,计算其所有值的平均值):val cbRDD = sc.parallelize(Seq(("a", 1), ("a", 2), ("a", 3), ("b", 2), ("b", 5)))val result = cbR...

Spark RDD算子进阶(转换算子、行动算子、缓存、持久化)(上)
0x00 教程内容转换算子与行动算子的进阶操作RDD的缓存与持久化0x01 进阶算子操作1. 创建RDDval rdd = sc.parallelize(List((1,1),(2,1),(3,1),(3,4)))2. 转换算子【1】reduceByKey(func)含义:合并具有相同键的值。rdd...
大数据进阶之路——Spark SQL小结
手写 WordCount使用flatMap、reduceByKey 来计算//sc是SparkContext对象,该对象是提交spark程序的入口 sc.textFile("file:///home/hadoop/data/hello.txt") // 读取文件, .flatMap(line =&g...

大数据进阶之路——Spark SQL补充
手写 WordCount使用flatMap、reduceByKey 来计算//sc是SparkContext对象,该对象是提交spark程序的入口 sc.textFile("file:///home/hadoop/data/hello.txt") // 读取文件, .flatMap(line =&g...
大数据进阶之路——Spark SQL日志分析
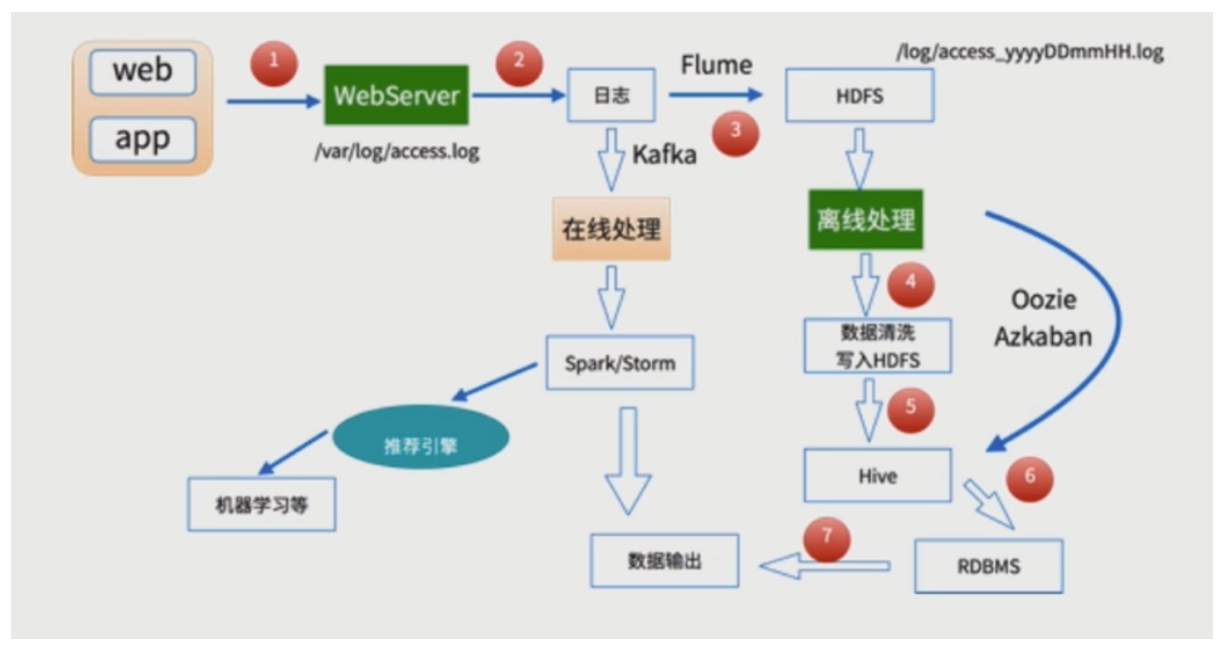
基本方案用户行为日志:用户每次访问网站时所有的行为数据(访问、浏览、搜索、点击…)用户行为轨迹、流量日志日志数据内容:1)访问的系统属性: 操作系统、浏览器等等2)访问特征:点击的url、从哪个url跳转过来的(referer)、页面上的停留时间等3)访问信息...
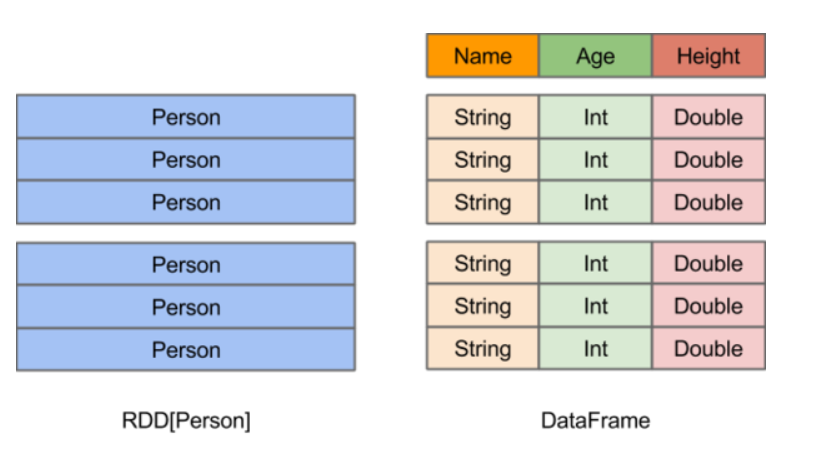
大数据进阶之路——Spark SQL 之 DataFrame&&Dataset
DataFrame它不是Spark SQL提出的,而是早起在R、Pandas语言就已经有了的。A Dataset is a distributed collection of data:分布式的数据集A DataFrame is a Dataset organized into named colu...
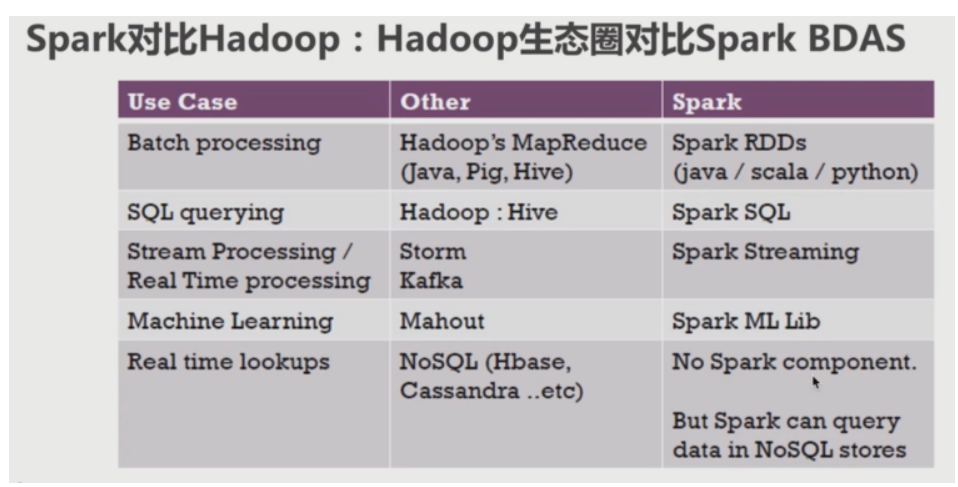
大数据进阶之路——Spark SQL基本配置
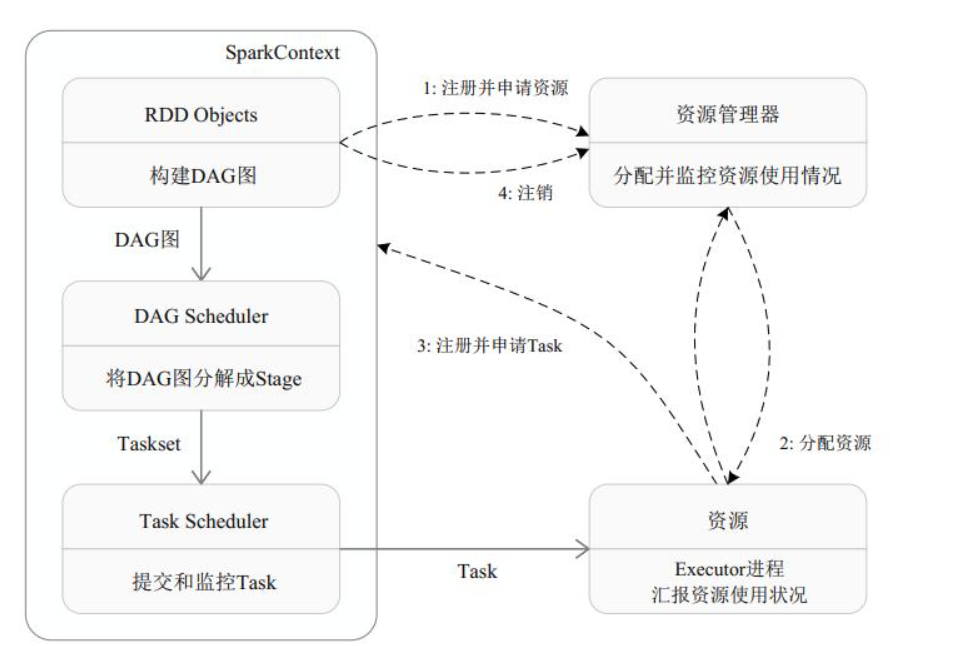
文章目录Spark安装编译失败环境搭建Standalone本地IDEHiveContextAPPSparkSessinonSpark ShellSpark Sqlthriftserver/beeline的使用jdbcMapReduce的局限性:1)代码繁琐;2)只能够支持map和reduce方法;3...
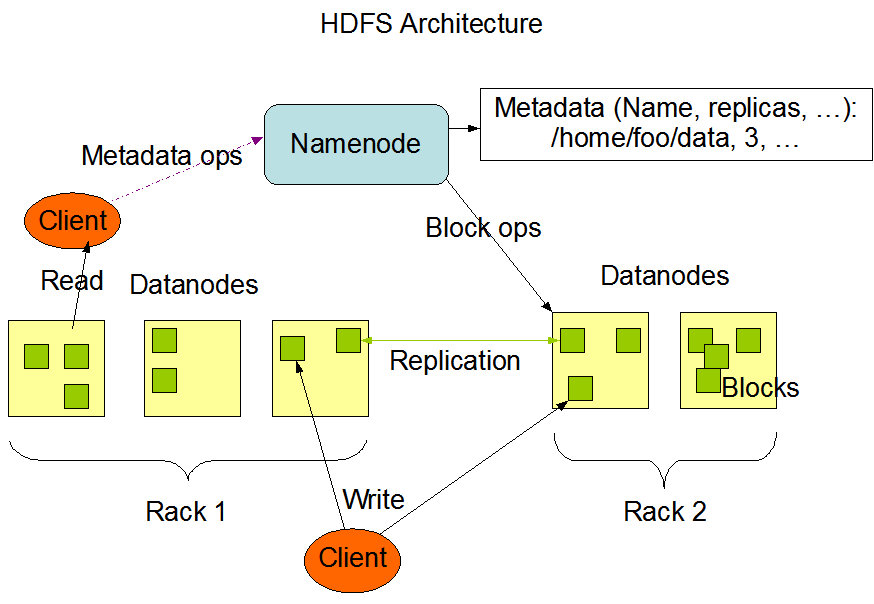
大数据进阶之路——Spark SQL环境搭建
@[toc]大数据概述定义和特征海量的计算大量的用户全体数据分析数据管理4V特征1.Volume(大量) 截至目前,人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级。2.Vel...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark streaming
- apache spark分布式
- apache spark Hadoop
- apache spark Python
- apache spark大数据技术
- apache spark算子
- apache spark动作
- apache spark hudi
- apache spark集成
- apache spark cdc
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作