Java爬虫:Jsoup解析HTML
官网:https://jsoup.org/依赖<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.13.1<...
Python爬虫:使用newspaper解析新闻页面信息
github: https://github.com/codelucas/newspaper安装pip3 install newspaper3k代码示例# -*- coding: utf-8 -*- from newspaper import Article url = "https://news....

Python爬虫:scrapy利用html5lib解析不规范的html文本
问题当爬取表格(table) 的内容时,发现用 xpath helper 获取正常,程序却解析不到在chrome、火狐测试都有这个情况。出现这种原因是因为浏览器会对html文本进行一定的规范化scrapy 使用的解析器是 lxml ,下面使用lxml解析,只是函数表达不一样,xpath和css选择器...
Python爬虫:使用lxml解析网页内容
安装pip install lxml代码示例from lxml import etree text = """ <html> <head> <title>这是标题</title> </head> <body> <div&g...
Python爬虫:Scrapy链接解析器LinkExtractor返回Link对象
LinkExtractorfrom scrapy.linkextractors import LinkExtractor Linkfrom scrapy.link import LinkLink四个属性url text fragment nofollow 如果需要解析出文本,需要在 LinkExtr...
Python爬虫:chrome网页解析工具-XPath Helper
非常棒的东西介绍:xPath helper是一款Chrome浏览器的开发者插件作用:通过xPath语法轻松获取HTML元素安装:1. chrome应用商店2. chrome插件网(http://www.cnplugins.com/)使用:Ctrl + Shift + X 激活再次按Ctrl-Shif...
Python爬虫:pyquery模块解析网页
pyquery可以解析网页pyquery: a jquery-like library for python代码示例from pyquery import PyQuery # 获取网页文档 doc = PyQuery(url="http://www.baidu.com", encoding="utf...
万创帮逆向解析,让你也能体验技术变现【Python爬虫实战系列之万创帮闲置资源整合逆向】
大家好,我是辣条,这是爬虫系列的32篇。前言爬虫系列太难了,我算了一下这个系列从开始到现在我写了40篇左右了,但是现在这个专栏只显示30篇左右,大概有10篇左右下架了因为版权或者违规的问题,难受...采集目标网址:https://m.wcbchina.com/login/login.html?ser...
爬虫的解析方式是怎样的呢?
爬虫的解析方式是怎样的呢?

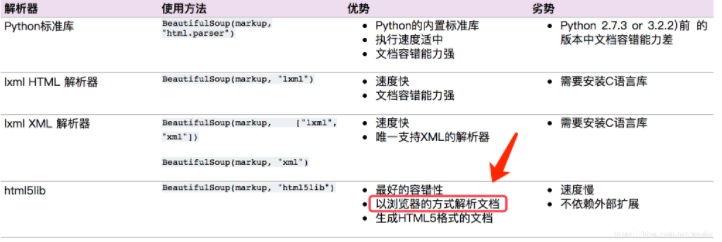
python爬虫——Beautiful Soup库(数据解析)模块讲解
本文转载:https://xiaochuhe.blog.csdn.net/article/details/123368545一、概述Beautiful Soup (简称bs4)是一个可以从HTML或XML文件中提取数据的Python库。提供一些简单的、python式的函数用来处理导航、搜索、修改分析...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


