
爬虫系统的核心:如何创建高质量的HTML文件?
在网页抓取或爬虫系统中,HTML文件的创建是一项重要的任务。HTML文件是网页的基础,包含了网页的所有内容和结构。在爬虫系统中,我们需要生成一个HTML文件,以便于保存和处理网页的内容。在这种情况下,可以使用Java函数来实现将爬取到的网页内容保存为HTML文件的功能。具体来说,当爬虫系统获取到需要...

爬虫数据存储技术比较:数据库 vs. 文件 vs. NoSQL
事件描述:在进行网络爬虫开发时,数据存储是一个关键的环节。不同的数据存储技术有着各自的特点和适用场景。本文将比较常用的数据库、文件和NoSQL三种数据存储技术,以帮助开发者选择合适的存储方式。亮点介绍:1.数据库:提供结构化数据存储和能查询的效高力。2.文件:简单易用,适合小规模数据存储和快速读写。...

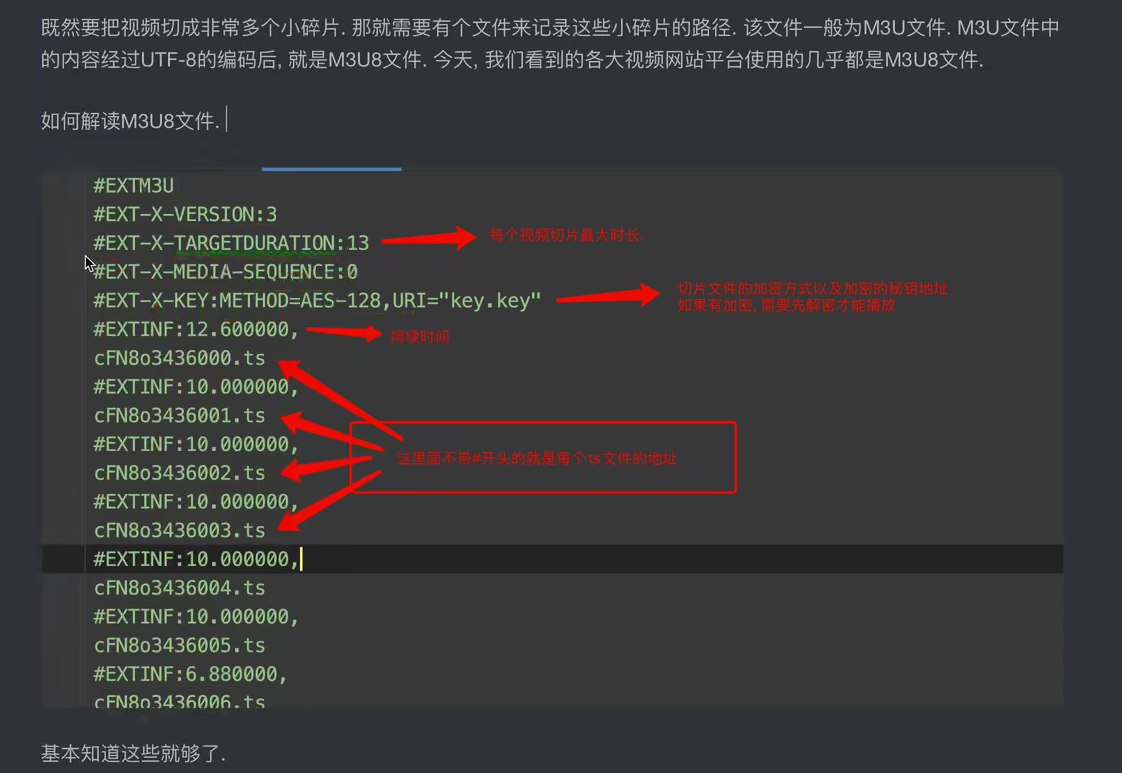
「Python」爬虫-5.m3u8(视频)文件的处理
持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第18天, 点击查看活动详情前言本文主要讲解了如何下载m3u8的视频文件到本地,加密解密,将ts文件合并为一个mp4文件三个知识点。关于爬虫,欢迎先阅读一下我的前几篇文章️️️:「Python」爬虫-1.入门知识简...
Python爬虫:使用requests库下载大文件
当使用requests的get下载大文件/数据时,建议使用使用stream模式。当把get函数的stream参数设置成False时,它会立即开始下载文件并放到内存中,如果文件过大,有可能导致内存不足。当把get函数的stream参数设置成True时,它不会立即开始下载,当你使用iter_conten...

爬虫系列:存储 CSV 文件
上一期:爬虫系列:存储媒体文件,讲解了如果通过爬虫下载媒体文件,以及下载媒体文件相关代码讲解。本期将讲解如果将数据保存到 CSV 文件。逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号)是存储表格数据常用文件格式。Microsoft ...
Dataset之MNIST:MNIST(手写数字图片识别+ubyte.gz文件)数据集的下载(基于python语言根据爬虫技术自动下载MNIST数据集)
数据集下载的所有代码代码打包地址:mnist数据集下载的完整代码https://download.csdn.net/download/qq_41185868/114497551、主文件 mnist_download_main.py文件#1、读取数据集# MNIST数据集大约12MB,如果没在指定的路...
在scrapy中,如何在一个爬虫文件中对不同的url进行爬取?
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
23、 Python快速开发分布式搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
转: http://www.bdyss.cn http://www.swpan.cn 用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templat...
20、 Python快速开发分布式搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
编写spiders爬虫文件循环抓取内容 Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url='url' callback=页面处理函数 使用时需要yield Request() parse.urljoin()方法,是urllib库下的方法,是自动u...
Python爬虫爬数据写入到文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #coding=utf-8 import requests from bs4 import...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


