[帮助文档] 调用StartSparkSQLEngine启动SparkSQL引擎
启动Spark SQL引擎。
[帮助文档] 调用GetSparkSQLEngineState查询SparkSQL引擎状态
查询Spark SQL引擎的状态。

[帮助文档] 调用KillSparkSQLEngine关闭SparkSQL引擎
关闭Spark SQL引擎。
[帮助文档] 通过Spark SQL读写Delta外表
Delta是一种可以基于OSS对象存储的数据湖表格式,支持UPDATE、DELETE和INSERT操作。AnalyticDB for MySQL湖仓版(3.0)和Delta表格式进行了整合,您可以通过Spark SQL读写Delta外表。本文主要介绍如何通过Spark SQL读写Delta外表。
[帮助文档] 通过Spark SQL访问JDBC MySQL数据源
AnalyticDB MySQL湖仓版(3.0)支持提交Spark SQL作业,您可以通过View或Catalog两种方式访问自建MySQL数据库或云数据库RDS MySQL、云原生数据库 PolarDB MySQL。本文以RDS MySQL为例,介绍如何通过Spark SQL访问RDS MySQL...
进入大数据 Spark SQL 的世界
1、什么是大数据? 大数据特征:4V 数据量(Volume) PB、EB、ZB &...
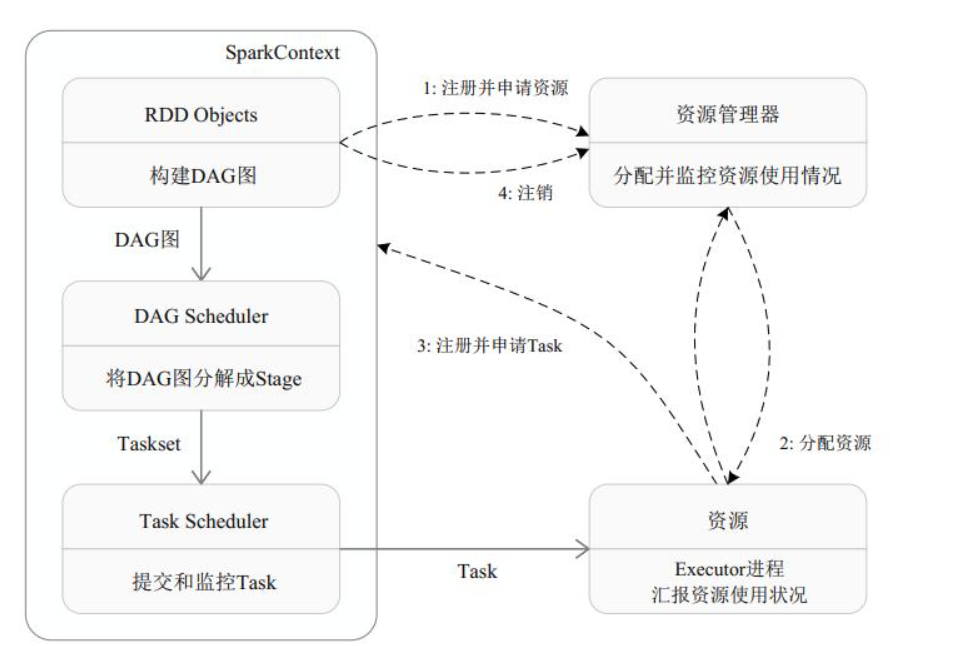
大数据进阶之路——Spark SQL小结
手写 WordCount使用flatMap、reduceByKey 来计算//sc是SparkContext对象,该对象是提交spark程序的入口 sc.textFile("file:///home/hadoop/data/hello.txt") // 读取文件, .flatMap(line =&g...
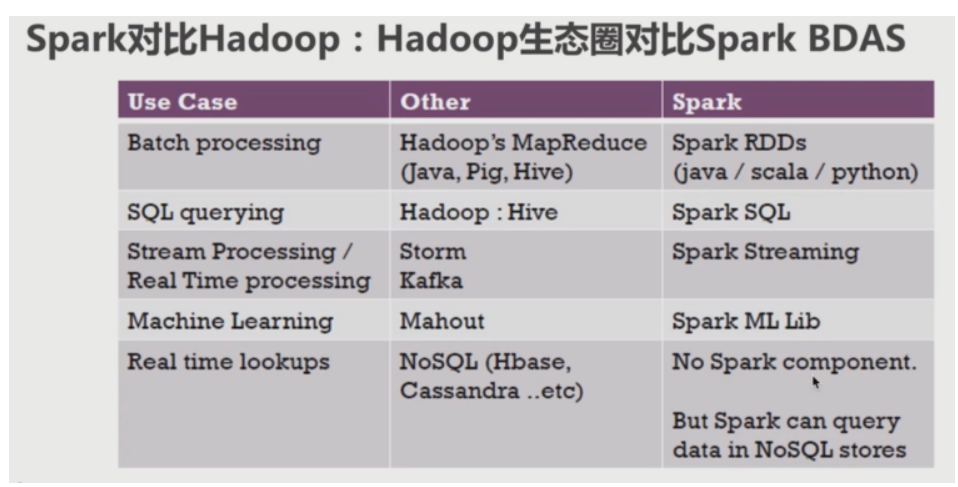
大数据进阶之路——Spark SQL基本配置
文章目录Spark安装编译失败环境搭建Standalone本地IDEHiveContextAPPSparkSessinonSpark ShellSpark Sqlthriftserver/beeline的使用jdbcMapReduce的局限性:1)代码繁琐;2)只能够支持map和reduce方法;3...
大数据为什么那么火?一文带你了解Spark与SQL结合的力量
Spark是一种大规模、快速计算的集群平台,本头条号试图通过学习Spark官网的实战演练笔记提升笔者实操能力以及展现Spark的精彩之处。有关框架介绍和环境配置可以参考以下内容: linux下Hadoop安装与环境配置(附详细步骤和安装包下载) linux下Spark安装与环境配置(附详细步...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子



最佳实践





SQL spark相关内容
- spark SQL分区
- odps spark SQL
- spark SQL简介
- spark SQL数据源
- spark SQL源码
- hadoop spark SQL
- 技术hadoop spark SQL
- spark SQL udf udaf
- pyspark笔记rdd dataframe spark SQL
- spark SQL自定义函数
- spark SQL实战dataframe
- spark SQL实战
- spark SQL编程dataframe
- spark SQL parquet
- spark SQL schema
- spark SQL sparksession
- mapreduce spark SQL
- hudi spark SQL源码学习
- hudi spark SQL源码学习ctas
- hudi spark SQL
- spark SQL执行流程
- spark SQL解析
- spark自定义SQL
- spark SQL jdbc
- spark SQL加载
- spark SQL功能
- spark streaming SQL
- 大数据进阶spark SQL
- spark程序SQL注册
- spark SQL临时表
- spark程序SQL schema
- spark程序SQL
- spark SQL组件
- spark SQL运行
- tablestore spark流批一体SQL实战
- 社区spark streaming SQL流式简介
- spark SQL datasets
- spark SQL概念学习
- spark入门SQL
- spark阅读SQL