[帮助文档] Spark访问MaxCompute数据_云原生大数据计算服务 MaxCompute(MaxCompute)
为了更好地融入大数据生态,MaxCompute开放了存储组件(Storage API),通过调用Storage API直接访问MaxCompute底层存储,有助于提高第三方引擎访问MaxCompute数据的速度与效率。本文为您介绍如何使用第三方计算引擎Spark通过Spark Connector调用...
[帮助文档] 通过Spark SQL访问JDBC MySQL数据源
AnalyticDB MySQL湖仓版(3.0)支持提交Spark SQL作业,您可以通过View或Catalog两种方式访问自建MySQL数据库或云数据库RDS MySQL、云原生数据库 PolarDB MySQL。本文以RDS MySQL为例,介绍如何通过Spark SQL访问RDS MySQL...

[帮助文档] 通过Spark SQL读Lindorm数据_云原生数据仓库AnalyticDB MySQL版(AnalyticDB for MySQL)
AnalyticDB MySQL湖仓版(3.0)支持通过Spark SQL访问Lindorm数据库。本文主要介绍如何通过Spark SQL访问Lindorm中的Hive表和宽表的数据。
[帮助文档] 创建EMR集群并使用Spark3读取表格存储数据_表格存储(Tablestore)
本文介绍如何通过开源大数据平台 EMR(E-MapReduce)控制台,快速创建一个EMR集群并使用Spark3读取表格存储的数据。
[帮助文档] 如何使用AnalyticDB MySQL湖仓版(3.0)Spark访问MongoDB数据_云原生数据仓库AnalyticDB MySQL版(AnalyticDB for MySQL)
本文介绍如何使用AnalyticDB MySQL版湖仓版(3.0)Spark访问云数据库MongoDB数据。
Spark On MaxCompute如何访问Phonix数据
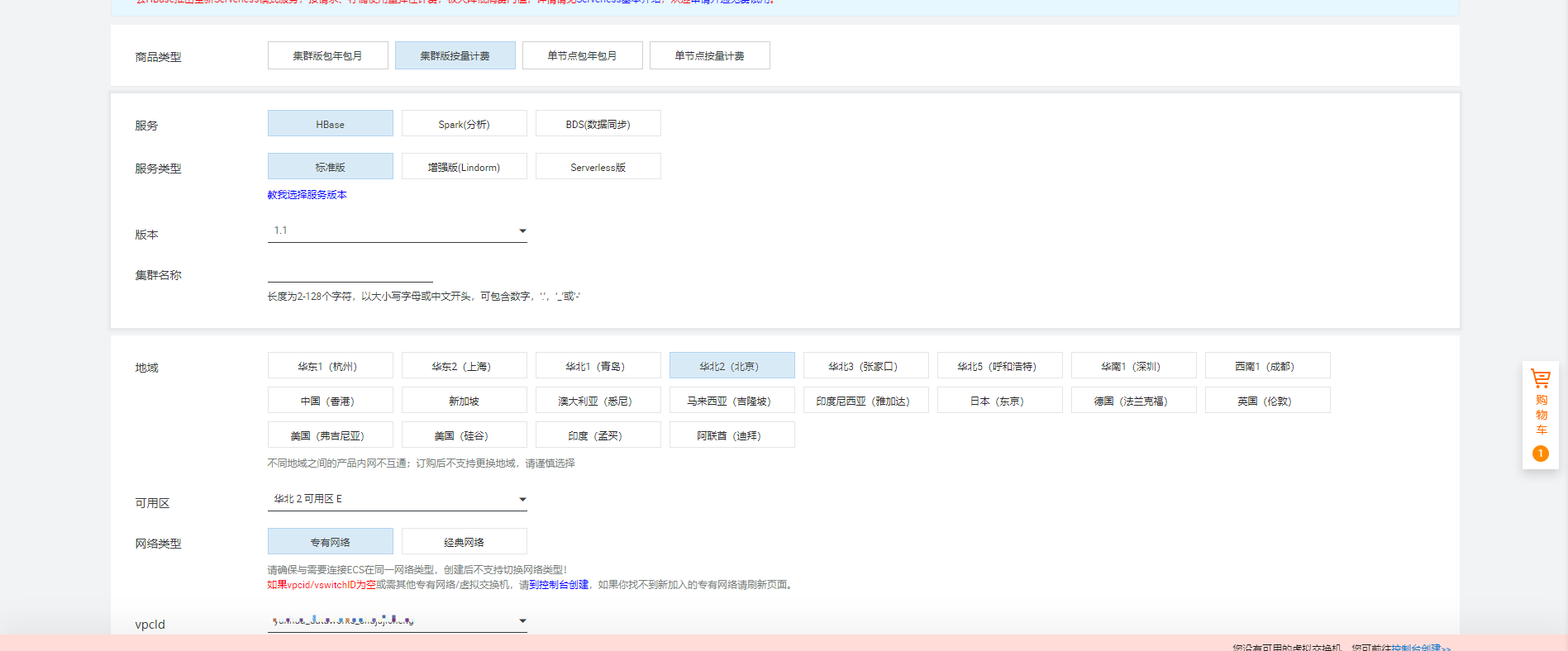
一、购买Hbase1.1并设置对应资源 1.1购买hbase hbase主要版本为2.0与1.1,这边选择对应hbase对应的版本为1.1Hbase与Hbase2.0版本的区别HBase1.1版本1.1版本基于HBase社区1.1.2版本开发。HBase2.0版本2.0版本是基于社区2018年发布的...
E-MapReduce中Spark 2.x读写MaxCompute数据
最新的aliyun-emapreduce-sdk将MaxCompute数据以DataSource的方式接入Spark 2.x,用户可以使用类似Spark 2.x中读写json/parquet/csv的方式来访问MaxCompute. 0. DataSource a) DataSource提供了一种插...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark数据相关内容
- apache spark数据加载
- apache spark学习数据
- apache spark学习sparksql编程数据加载
- adb apache spark数据
- apache spark访问数据
- apache spark查询数据
- apache spark程序数据
- apache spark数据报错
- apache spark hive数据
- apache spark数据区别
- apache spark学习sparksql概述编程数据
- apache spark数据本地性
- apache spark数据调优
- apache spark同步数据
- apache spark数据hologres
- apache spark odps数据
- e-mapreduce apache spark数据
- apache spark数据函数
- apache spark hbase数据
- apache spark开发去掉文件数据
- apache spark数据方法
- apache spark实战数据
- apache spark数据模型
- apache spark数据切分
- apache spark项目数据实现操作
- apache spark数据类
- apache spark挖掘数据
- 大数据apache spark分析挖掘数据案例
- apache spark数据案例
- apache spark数据切分原则
- apache spark数据倾斜造成
- apache spark数据rdd
- apache spark streaming数据
- apache spark数据位置管理
- apache spark kafka数据
- 数据湖apache spark数据
- apache spark数据平台
- hive apache spark数据
- apache spark结构化数据
- emr apache spark数据
- apache spark relational数据预组织查询
- apache spark存储数据
- apache spark归档数据
- apache spark loghub数据
- apache spark kudu数据
- apache spark数据hdfs
- apache spark数据集中
- apache spark mllib数据
apache spark更多数据相关
apache spark您可能感兴趣
- apache spark分布式
- apache spark Hadoop
- apache spark Python
- apache spark大数据技术
- apache spark算子
- apache spark动作
- apache spark hudi
- apache spark集成
- apache spark cdc
- apache spark flink
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark程序
- apache spark操作