Hadoop和Hive中的数据倾斜问题及其解决方案
Hadoop和Hive中的数据倾斜问题及其解决方案Hadoop 中的数据倾斜问题及其解决方案原因:在 Hadoop 的 MapReduce 中,数据倾斜通常发生在 Reduce 阶段,当某些键值对的数量远多于其他键时。解决方案:Combiner: 在 Map 阶段使用 Combiner 可以减少传输...
Hadoop知识点总结——数据倾斜解决方法
1、提前在map端进行combine,减少传输的数据量在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。2、导致数据倾斜的key,大量分布在不同的mapper2.1 局部聚合...

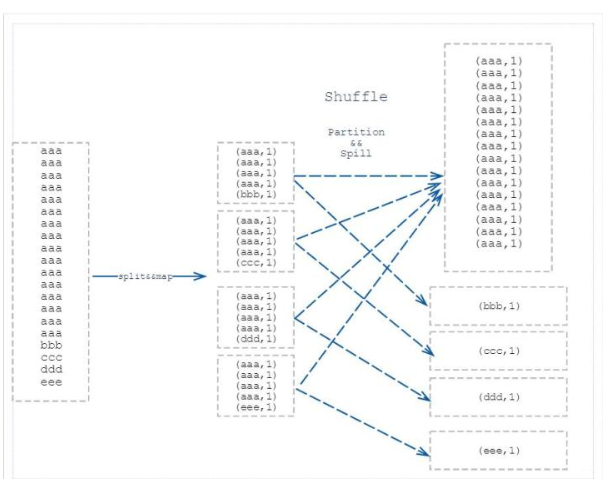
【Hadoop】(五)MapReduce 如何解决数据倾斜问题
文章目录一、什么是数据倾斜以及数据倾斜是怎么产生的?二、为什么说数据倾斜与业务逻辑和数据量有关?三、如何处理数据倾斜问题呢?四、总结一、什么是数据倾斜以及数据倾斜是怎么产生的?简单来说数据倾斜就是数据的key 的分化严重不均,造成一部分数据很多,一部分数据很少的局面。举个 word count 的入...
Hadoop数据倾斜的问题怎么解决?
Hadoop数据倾斜的问题怎么解决?
Hadoop 解决数据倾斜方法是什么?
Hadoop 解决数据倾斜方法是什么?
hadoop中怎么解决数据倾斜问题?
hadoop中怎么解决数据倾斜问题?
hadoop中的全排序造成数据倾斜的原因是什么?
hadoop中的全排序造成数据倾斜的原因是什么?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








