「大数据架构」Spark 3.0发布,重大变化,性能提升18倍
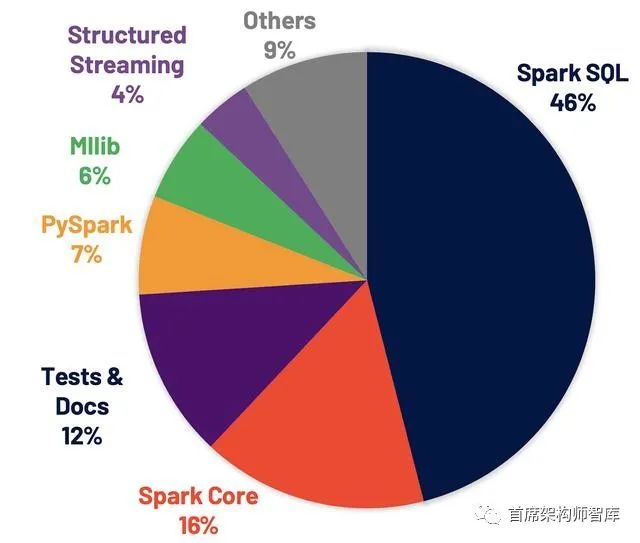
我们激动地宣布,作为Databricks运行时7.0的一部分,可以在Databricks上使用Apache SparkTM 3.0.0版本。3.0.0版本包含超过3400个补丁,是开源社区做出巨大贡献的顶峰,带来了Python和SQL功能方面的重大进步,并关注于开发和生产的易用性。这些举措反映了该项...
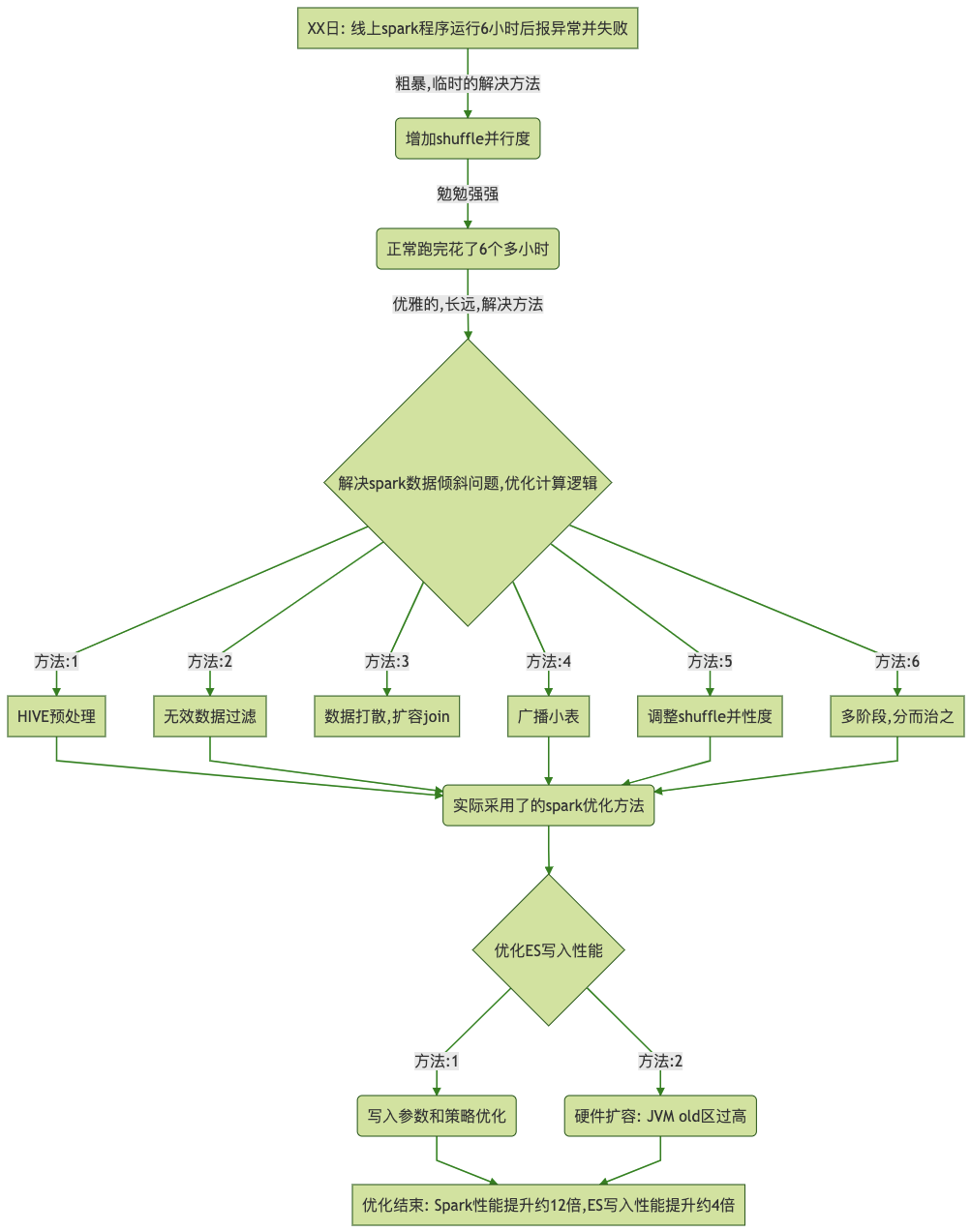
工作经验分享:Spark调优【优化后性能提升1200%】
优化后效果1.业务处理中存在复杂的多表关联和计算逻辑(原始数据达百亿数量级)2.优化后,spark计算性能提升了约12倍(6h-->30min)3.最终,业务的性能瓶颈存在于ES写入(计算结果,ES索引document数约为21亿 pri.store.size约 300gb)1. 背景业务数据...

Spark将Hadoop(主要是指MapReduce)的性能提升了一个量级,主要的得益于那两个方面?
Spark将Hadoop(主要是指MapReduce)的性能提升了一个量级,主要的得益于那两个方面?

个推技术实践 | Spark性能调优看这篇,性能提升60%↑ 成本降低50%↓
Spark是目前主流的大数据计算引擎,功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,应用范围与前景非常广泛。作为一种内存计算框架,Spark运算速度快,并能够满足UDF、大小表Join、多路输出等多样化的数据计算和处理需求。作为国内专业的数...
问一个问题哈,在spark中默认使用java serialization ,但同时也提供了 kryo 序列化借口,今天测试了一下 两个不同的序列号借口,发现并没有性能提升,我用的sparksql跑的测试,设计多个join操作,input量为270G , 这个为什么对性能没有提升呢? 有大佬做过这方面的研究吗
问一个问题哈,在spark中默认使用java serialization ,但同时也提供了 kryo 序列化借口,今天测试了一下 两个不同的序列号借口,发现并没有性能提升,我用的sparksql跑的测试,设计多个join操作,input量为270G , 这个为什么对性能没有提升呢? 有大佬做过这方面...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作