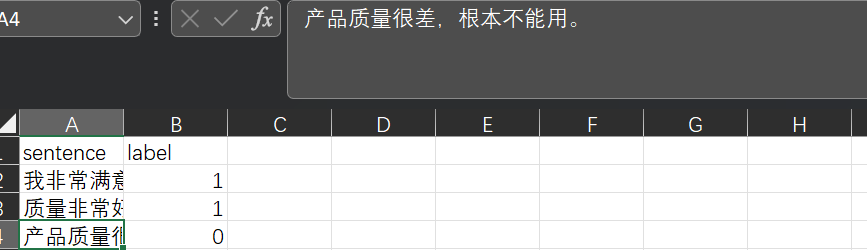
训练你自己的自然语言处理深度学习模型,Bert预训练模型下游任务训练:情感二分类
基础介绍:Bert模型是一个通用backbone,可以简单理解为一个句子的特征提取工具更直观来看:我们的自然语言是用各种文字表示的,经过编码器,以及特征提取就可以变为计算机能理解的语言了下游任务:提取特征后,我们便可以自定义其他自然语言处理任务了,以下是一个简单的示例(效果可能不好,但算是一个基本流...
【深度学习】实验11 使用Keras预训练模型完成猫狗识别
使用Keras预训练模型完成猫狗识别VGG16是一种深度卷积神经网络,由牛津大学计算机视觉研究小组在2014年提出。它是ImageNet图像识别竞赛的冠军,拥有较好的图像识别和分类效果。VGG16架构非常简单,特征提取部分由13个卷积层和5个池化层组成,分类器部分有3个全连接层。VGG16中的卷积层...

人工智能领域:面试常见问题超全(深度学习基础、卷积模型、对抗神经网络、预训练模型、计算机视觉、自然语言处理、推荐系统、模型压缩、强化学习、元学习)
人工智能领域:面试常见问题 1.深度学习基础 为什么归一化能够提高求解最优解的速度?为什么要归一化?归一化与标准化有什么联系和区别?归一化有哪些类型?Min-max归一化一般在什么情况下使用?Z-score归一化在什么情况下使用?学习率过大或过小对网络会有什么影响?batch size...
![深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。](https://ucc.alicdn.com/fnj5anauszhew_20230529_5dfe9e7e0fad4be185d806d649fbe8ab.png)
深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。
深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。 1.ERNIE-Doc: A Retrospective Long-Document Modeling Transformer 1.1. ERNIE-Doc简...
![深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解](https://ucc.alicdn.com/fnj5anauszhew_20230528_47b9af59d4344b79843eaa18a3313d0e.png)
深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解
深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解 后预训练模型时代 1.ERINE 1.1 ERINE简介 ERINE是百度发布一个预训练模型,它通过引入三种级别的Knowledge Masking帮助模型学习语言知识,在多项任务...

深度学习进阶篇-预训练模型4:RoBERTa、SpanBERT、KBERT、ALBERT、ELECTRA算法原理模型结构应用场景区别等详解
深度学习进阶篇-预训练模型[4]:RoBERTa、SpanBERT、KBERT、ALBERT、ELECTRA算法原理模型结构应用场景区别等详解 1.SpanBERT: Improving Pre-training by Representing and Predicting Spans 1.1. S...
![深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解](https://ucc.alicdn.com/fnj5anauszhew_20230526_a8ef174625f448c29fd038a273cbb6e5.png)
深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解
深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解 1.XLNet:Generalized Autoregressive Pretraining for Language Understan...
![深度学习进阶篇-预训练模型[2]:Transformer-XL、Longformer、GPT原理、模型结构、应用场景、改进技巧等详细讲解](https://ucc.alicdn.com/fnj5anauszhew_20230525_c86f2563fe3443868e28afc071677831.png)
深度学习进阶篇-预训练模型[2]:Transformer-XL、Longformer、GPT原理、模型结构、应用场景、改进技巧等详细讲解
深度学习进阶篇-预训练模型[2]:Transformer-XL、Longformer、GPT原理、模型结构、应用场景、改进技巧等详细讲解 1.Transformer-XL: Attentive Language Models Beyonds a Fixed-Length Context 1.1. T...

深度学习进阶篇-预训练模型1:预训练分词Subword、ELMo、Transformer模型原理;结构;技巧以及应用详解
深度学习进阶篇-预训练模型[1]:预训练分词Subword、ELMo、Transformer模型原理;结构;技巧以及应用详解 从字面上看,预训练模型(pre-training model)是先通过一批语料进行训练模型,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。这样的理解基本上是对的,...
深度学习预训练模型下载
'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth', 'densenet121': 'http://data.lip6.fr/cadene/pretrainedmodels/densenet121-fbd...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子



最佳实践


