
Spark学习---SparkSQL(概述、编程、数据的加载和保存、自定义UDFA、项目实战)
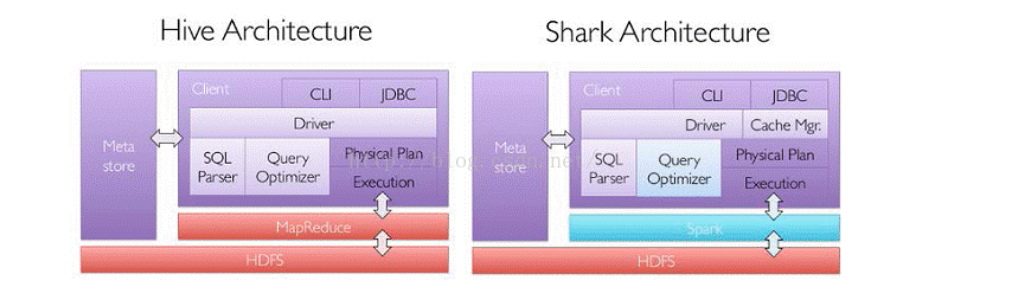
一、SparkSQL概述 1.1 什么是SparkSQL Spark是用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,SparkSQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,SparkSQL使用这些额外的信息来执行额外的优化。与Spar...
adb spark的lakehouse api访问内表数据,还支持算子下推吗
adb spark的lakehouse api访问内表数据,还支持算子下推吗?adb spark访问内表数据应该只会直接粗糙读取OSS,而不会再经过存储节点了,所以spark通过lakehouse api访问内表数据是不是就不会有过滤算子下推了? 对于你的问题,我理解你想了解使用ADB (Apach...

Flink CDC同步到hudi 可以直接读取hudi 的数据吗 例如用hive 或者spark?
Flink CDC同步到hudi 可以直接读取hudi 的数据吗 例如用hive 或者spark?
通过spark-sql客户端往hive的一个表随便插入一条数据,然后在hive中查询这个表报错.
通过spark-sql客户端往hive的一个表随便插入一条数据,然后在hive中查询这个表报错:SQL 错误: java.lang.NoClassDefFoundError: Could not initialize class org.xerial.snappy.Snappy。我在spark-sq...
在表格存储中spark写入ots程序没有报错,但是为什么查询ots的时候,发现没有数据?
在表格存储中dataworks的数据开发下面的spark节点,使用spark读取maxcompute数据,并且写入tablestore。我是对于tablestore建立了maxcompute外表,spark写入ots程序没有报错,但是为什么查询ots的时候,发现没有数据?
通过spark-sql往hive的一个表随便插入一条数据,然后在hive中查询这个表报错
通过spark-sql客户端往hive的一个表随便插入一条数据,然后在hive中查询这个表报错:SQL 错误: java.lang.NoClassDefFoundError: Could not initialize class org.xerial.snappy.Snappy。我在spark-sq...
ADB MySQL湖仓版数据都在oss,如果想跑spark作业,这个数据库合适吗?
ADB MySQL湖仓版数据都在oss,如果想跑spark作业,这个数据库合适吗?我看maxcompute,EMR等好几个服务都支持spark,不知道哪个合适,主要场景是oss做离线计算后,再放入oss
大数据计算MaxCompute中Spark跑oss数据,这几个有啥区别?
大数据计算MaxCompute中Spark跑oss数据,用MC 合适还是AnalysDB, 我看EMR,mc, ADB好几个产品都支持,不知道哪个合适,成本低点?请教下,这几个有啥区别?
在dataworks的数据开发下面的spark节点,为什么查询ots的时候,发现没有数据?
在dataworks的数据开发下面的spark节点,使用spark读取maxcompute数据,并且写入tablestore。我是对于tablestore建立了maxcompute外表,spark写入ots程序没有报错,但是为什么查询ots的时候,发现没有数据?
Spark学习------SparkSQL(概述、编程、数据的加载和保存)
这是本人的学习过程,看到的同道中人祝福你们心若有所向往,何惧道阻且长; 但愿每一个人都像星星一样安详而从容的,不断沿着既定的目标走完自己的路程; 最后想说一句君子不隐其短,不知则问,不能则学。 如果大家觉得我写的还不错的话希望可以收获关注、点赞、收藏(谢谢大家) 一、SparkSQL概述 1.1 什...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多数据相关
- apache spark数据加载
- apache spark学习数据
- apache spark学习sparksql编程数据加载
- adb apache spark数据
- apache spark访问数据
- apache spark查询数据
- apache spark程序数据
- apache spark数据报错
- apache spark hive数据
- apache spark streaming数据
- apache spark数据方法
- apache spark east数据
- apache spark kafka数据
- apache spark数据案例
- apache spark summit east数据分析
- apache spark挖掘数据
- apache spark summit east数据
- apache spark mllib数据
- apache spark同步数据
- apache spark hbase数据
- apache spark归档数据
- apache spark数据rdd
- apache spark学习sparksql概述编程数据
- apache spark数据切分
- apache spark数据hologres
- apache spark数据本地性
- apache spark数据位置管理
- apache spark数据hdfs
- apache spark mllib数据图文详解
- apache spark结构化数据
- apache spark odps数据
- apache spark tb数据
- apache spark relational数据预组织查询
- hive apache spark数据
- apache spark数据集中
- apache spark项目数据实现操作
- emr apache spark数据
- apache spark maxcompute数据
- apache spark开发去掉文件数据
- 大数据apache spark分析挖掘数据案例
- e-mapreduce apache spark数据
- apache spark kudu数据
- apache spark存储数据
- apache spark数据调优
- apache spark数据类
- apache spark数据模型
- apache spark数据函数
- apache spark实战数据
- apache spark loghub数据
- apache spark数据切分原则
apache spark您可能感兴趣
- apache spark streaming
- apache spark分布式
- apache spark Hadoop
- apache spark Python
- apache spark大数据技术
- apache spark算子
- apache spark动作
- apache spark hudi
- apache spark集成
- apache spark cdc
- apache spark SQL
- apache spark Apache
- apache spark rdd
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作