
Spark集群部署与架构
在大数据时代,处理海量数据需要分布式计算框架。Apache Spark作为一种强大的大数据处理工具,可以在集群中高效运行,处理数十TB甚至PB级别的数据。本文将介绍如何构建和管理Spark集群,以满足大规模数据处理的需求。 Spark集群架构 Spark集群的核心组成部分包括Master节点、Wor...
[帮助文档] Spark的架构及使用场景(新)
Spark是一个通用的大数据分析引擎,具有高性能、易用和普遍性等特点。

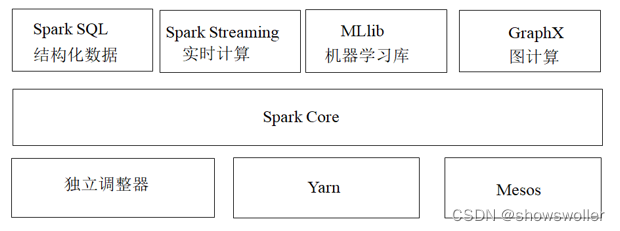
【大数据技术Hadoop+Spark】Spark架构、原理、优势、生态系统等讲解(图文解释)
一、Spark概述Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心...
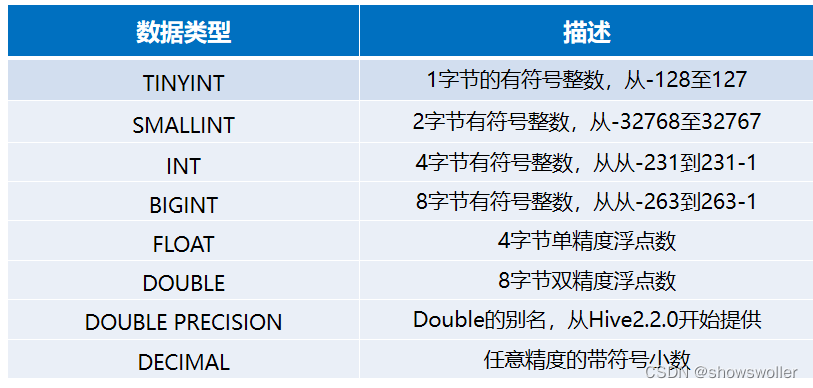
【大数据技术Hadoop+Spark】Hive数据仓库架构、优缺点、数据模型介绍(图文解释 超详细)
一、Hive简介Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但对于其他语言使用者则难度较大。因此Facebook...
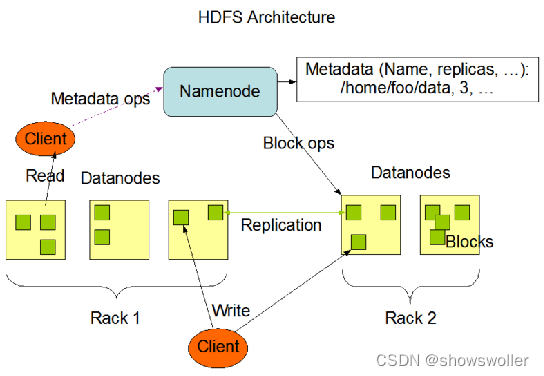
【大数据技术Hadoop+Spark】HDFS概念、架构、原理、优缺点讲解(超详细必看)
一、相关基本概念文件系统。文件系统是操作系统提供的用于解决“如何在磁盘上组织文件”的一系列方法和数据结构。分布式文件系统。分布式文件系统是指利用多台计算机协同作用解决单台计算机所不能解决的存储问题的文件系统。如单机负载高、数据不安全等问题。HDFS。英文全称为Hadoop Distributed F...
【大数据处理框架】Spark大数据处理框架,包括其底层原理、架构、编程模型、生态圈
Spark大数据处理框架是一个开源的大数据处理框架,它可提供高效的内存计算,可在弹性、分布式的集群上运行。Spark框架的优势在于它能够更加高效地利用计算资源,提高数据处理速度,因此在大数据处理领域中广受欢迎。Spark框架的底层原理Spark框架的底层原理基于RDD(Resilient Distr...
程序代码为什么在spark架构中运行的速度快呢?
程序代码为什么在spark架构中运行的速度快呢?
spark 架构在执行时是怎么做并行的?
spark 架构在执行时是怎么做并行的?
spark 的架构是什么样的呢?
spark 的架构是什么样的呢?
企业级应用系统体系架构中的Hadoop,Strom和Spark之间有什么关系吗?
企业级应用系统体系架构中的Hadoop,Strom和Spark之间有什么关系吗?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多架构相关
apache spark您可能感兴趣
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark Hadoop
- apache spark Python
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作