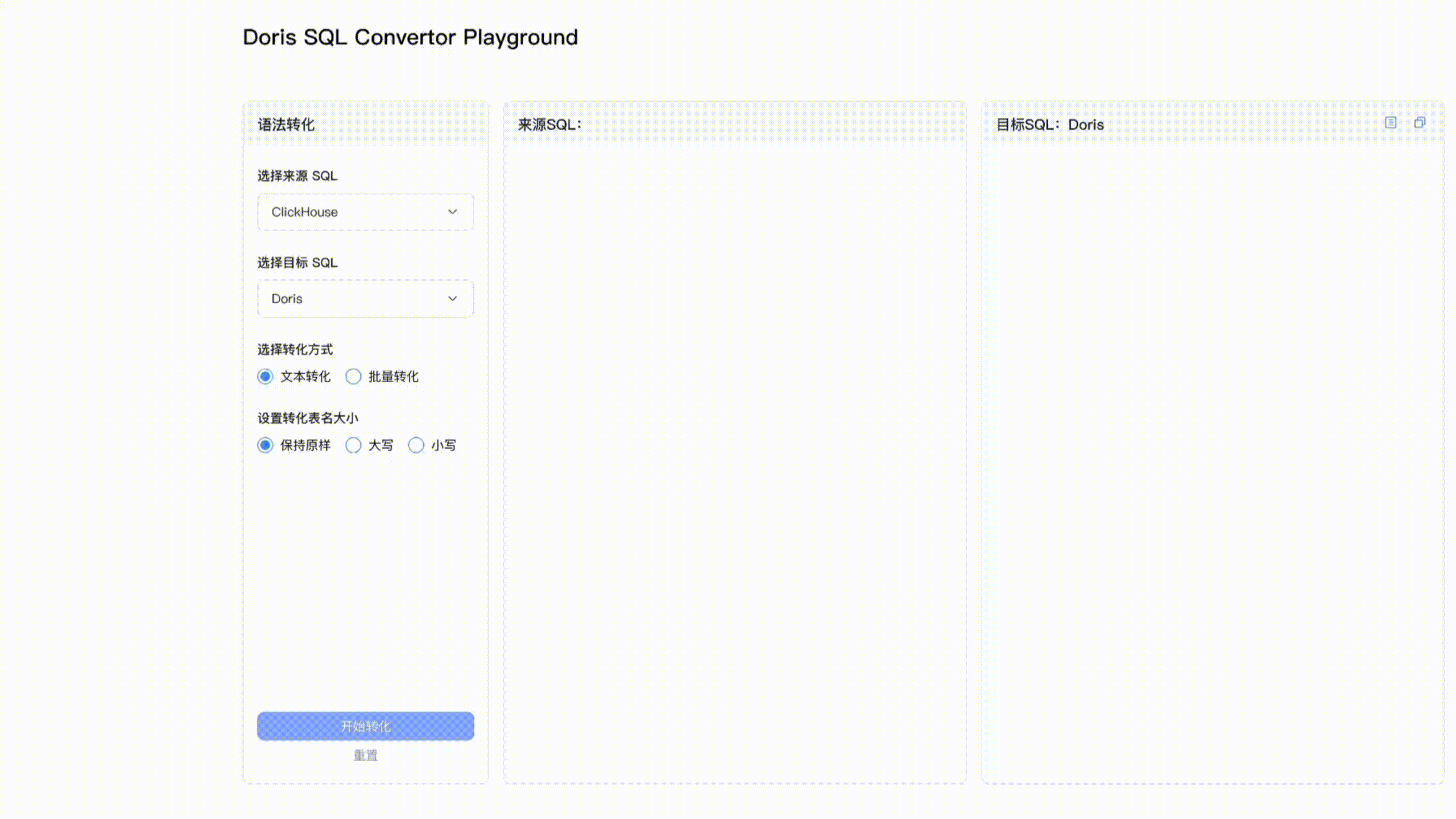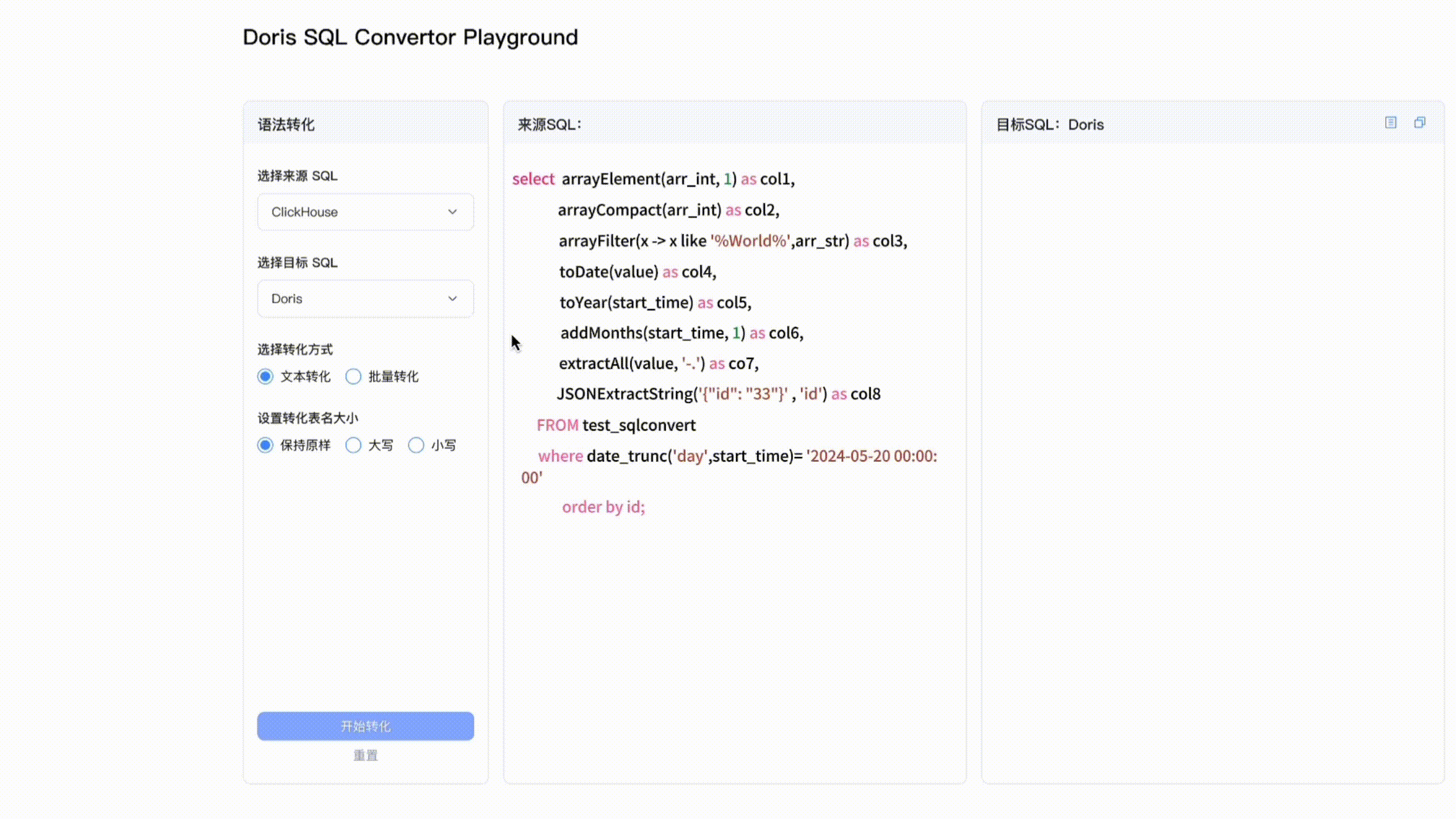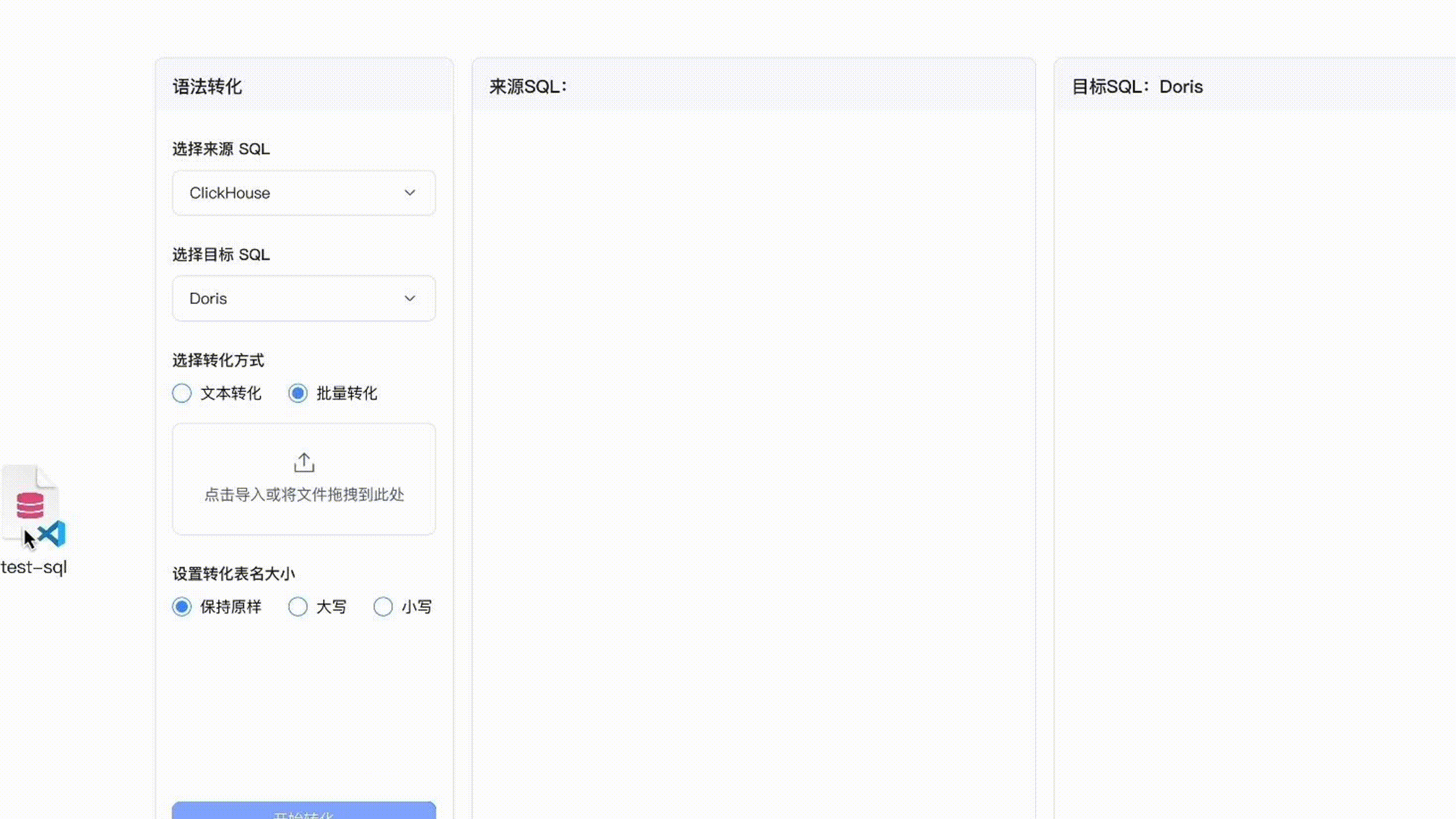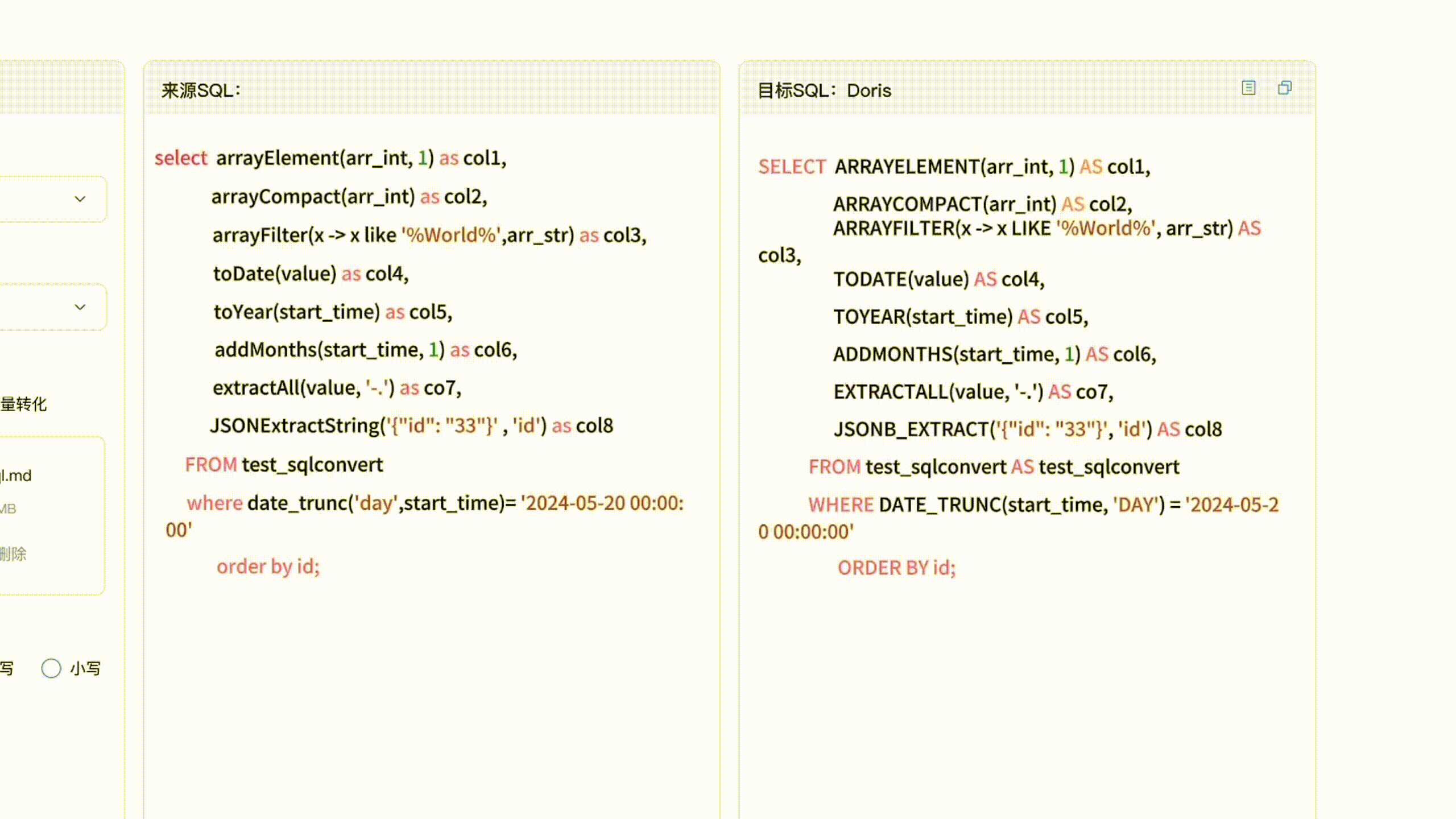
阿里云数据库内核 Apache Doris 兼容 Presto、Trino、ClickHouse、Hive 等近十种 SQL 方言,助力业务平滑迁移
2023 年 3 月,在阿里云瑶池数据库峰会上,阿里云与飞轮科技正式达成战略合作协议,双方旨在共同研发名为“阿里云数据库 SelectDB 版”的新一代实时数据仓库,为用户提供在阿里云上的全托管服务。SelectDB 是飞轮科技基于 Apache Doris 内核打造的聚焦于企业大数据实时分析需求的...
平台上flink sql 写hive表 有模版么?
平台上flink sql 写hive表 有模版么?

通过spark-sql客户端往hive的一个表随便插入一条数据,然后在hive中查询这个表报错.
通过spark-sql客户端往hive的一个表随便插入一条数据,然后在hive中查询这个表报错:SQL 错误: java.lang.NoClassDefFoundError: Could not initialize class org.xerial.snappy.Snappy。我在spark-sq...
通过spark-sql往hive的一个表随便插入一条数据,然后在hive中查询这个表报错
通过spark-sql客户端往hive的一个表随便插入一条数据,然后在hive中查询这个表报错:SQL 错误: java.lang.NoClassDefFoundError: Could not initialize class org.xerial.snappy.Snappy。我在spark-sq...
Flink CDC中有用flink sql连接hive的吗?
Flink CDC中有大佬用flink sql连接hive的吗?
Hive sql 执行原理
1.Group By的执行任务2.distinct的执行任务:尽量用group by3.join 执行任务:从这个实现可以看出,我们在写Hive Join的时候,应该尽可能把小表(分布均匀的表)写在左边,大表(或倾斜表)写在右边。这样可以有效利用内存和硬盘的关系,提高Hive的处理能力。学会用exp...
Hive SQL 优化
1.案例一原sql:select count(case when a.id in (select id from b) then 1 esle 0) from a;结果总共数据:727 耗时:2020-12-28 17:38:31 INFO Cost time is: 568.197s改...
Presto【实践 01】Presto查询性能优化(数据存储+SQL优化+无缝替换Hive表+注意事项)及9个实践问题分享
1.优化1.1 数据存储合理设置分区:与Hive类似,Presto 会根据元信息读取分区数据,合理的分区能减少 Presto 数据读取量,提升查询性能。使用列式存储:Presto 对 ORC 文件读取做了特定优化,因此在 Hive 中创建 Presto 使用的表时,建议采用 ORC 格式存储。相对于...
Flink sql将数组炸开,实现hive的explode函数的效果,还有什么其他好的方式?
Flink sql将数组炸开,实现hive的explode函数的效果,除了用cross join的方式以外,还有什么其他好的方式?
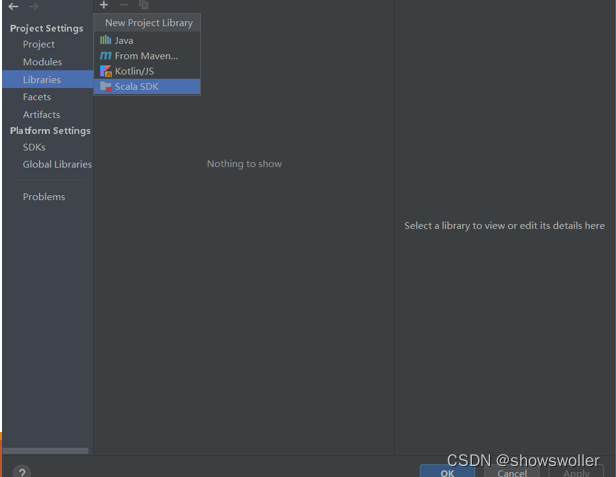
【大数据技术Spark】Spark SQL操作Dataframe、读写MySQL、Hive数据库实战(附源码)
需要源码和依赖请点赞关注收藏后评论区留言私信~~~一、Dataframe操作步骤如下1)利用IntelliJ IDEA新建一个maven工程,界面如下2)修改pom.XML添加相关依赖包3)在工程名处点右键,选择Open Module Settings4)配置Scala Sdk,界面如下5)新建文件...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子




最佳实践




SQL更多hive相关
- apache hive SQL
- SQL客户端hive
- hive SQL优化
- spark SQL hive
- hive ddl dml SQL
- hive SQL练习
- SQL cli hive
- hive SQL解析器
- SQL jdbc hive
- 大数据技术hive SQL题库
- hive数据源yarn集群SQL
- hive etl SQL
- hive SQL开发指南
- hive SQL编译过程
- hive SQL语法
- hive SQL注意事项
- hive SQL任务
- hive SQL底层
- hive SQL命令
- maxcompute SQL hive分析注意事项
- azure SQL hive
- 大数据入门实战hive SQL
- hive SQL mr
- hive SQL实现推荐系统
- 版本SQL hive
- SQL hive is_generic
- hive etl行业SQL
- hive SQL分桶