Hadoop:驭服数据洪流的利器
引言随着互联网的迅猛发展和智能设备的普及,数据量呈几何级数增长。如何高效地存储、处理和分析这些海量数据,成为了现代企业面临的重要挑战。而Hadoop作为一种领先的大规模数据处理框架,以其分布式计算、高可靠性和扩展性等特点,成为解决大数据问题的关键工具。一、Hadoop的概念与原理1.1 Hadoop...

使用Sqoop将数据从Hadoop导出到关系型数据库
当将数据从Hadoop导出到关系型数据库时,Apache Sqoop是一个非常有用的工具。Sqoop可以轻松地将大数据存储中的数据导出到常见的关系型数据库,如MySQL、Oracle、SQL Server等。本文将深入介绍如何使用Sqoop进行数据导出,并提供详细的示例代码,以帮助大家更全面地理解和...

[hadoop3.x]HDFS之银行海量转账数据分层案例(八)
银行每一天都有大量的转账、交易需要保存、处理。用户每进行一笔交易或者转账,银行都需要将用户转账的所有相关信息保存下来。四大银行:银行有非常多的用户,四大银行拥有数10亿的用户。要保存的数据量可想而知。如果说有的数据,都同等对待,为了保证使用数据的性能,采用的是高性能存储,这将是一笔不小的资源浪费。实...
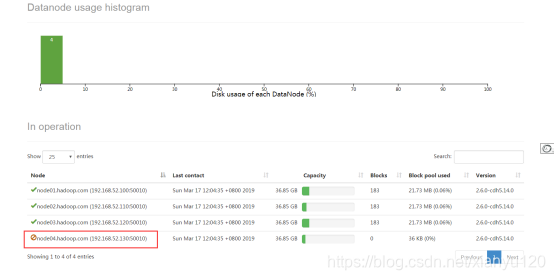
大数据成长之路-- hadoop集群的部署(4)退役旧数据节点
退役旧数据节点目标:掌握HDFS在集群中删除掉无效节点的步骤第一步:创建dfs.hosts.exclude配置文件在namenod的cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目录下创建dfs.hosts.exclude文件,并添加需要退役...
Hadoop怎么处理数据
一、引言Hadoop是一个流行的分布式计算框架,它允许处理大规模数据集。在本文中,我们将探讨Hadoop任务提交的步骤以及对数据处理的基本过程。二、Hadoop任务提交编写MapReduce代码:首先,需要编写MapReduce代码。MapReduce程序通常由一个Mapper类和一个Reducer...
阿里云E-MapReduceJindo DistCp是否支持将数据从Hadoop同步至aws的s3?
阿里云E-MapReduce我们自建了一个带有kerberos的hadoop集群,Jindo DistCp是否支持将数据从Hadoop同步至aws的s3?
[帮助文档] 如何通过ES-Hadoop实现Hive读写阿里云Elasticsearch数据_检索分析服务 Elasticsearch版(ES)
ES-Hadoop是Elasticsearch推出的专门用于对接Hadoop生态的工具,可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。本...
你好 用机器学习PAI的emr上的ds集群读hive可以读取我现有hadoop集群的hive数据吗?
你好 用机器学习PAI的emr上的ds集群读hive可以读取我现有hadoop集群的hive数据吗?另外,训练也是在pai-dls上进行吗?(还是ds上训练)
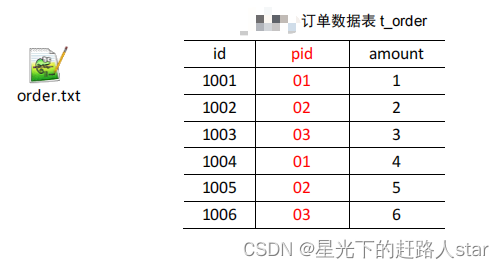
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(二)
3、Join应用3.1 Reduce Join(1)Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。(2)Reduce端的主要工作:在Reduce端以连接...
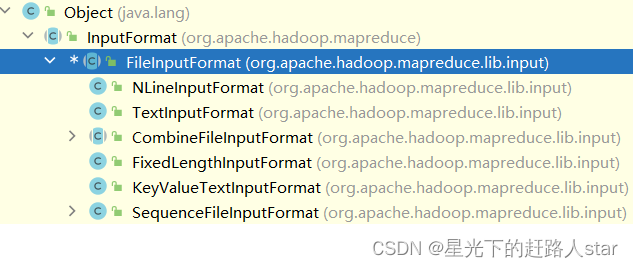
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(一)
1、OutputFormat数据输出1.1 OutputFormat接口实现类OutputFormat是MapReduce输出的基类,所以实现MapReduce输出都实现了OutputFormat接口。1、MapReduce默认的输出格式是TextOutputFormat2、也可以自定义Output...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








