Hadoop生态系统深度剖析:面试经验与必备知识点解析
作为一名在大数据领域深耕多年的博主,我深知Hadoop作为大数据处理的基石,其在面试中的重要地位不言而喻。本文将结合丰富的面试经验,深入探讨Hadoop生态系统的必备知识点与常见问题解析,助你在面试中应对自如。 一、Hadoop生态系统概述 1.Hadoop架构 阐述Hadoop的核心组件(HDFS...
在Linux系统上安装Hadoop的详细步骤
以下是在Linux系统上安装Hadoop的详细步骤: 下载Hadoop文件在Hadoop官方网站上下载最新的稳定版本的Hadoop文件。下载地址:https://hadoop.apache.org/releases.html 解压Hadoop文件打开终端,使用以下命令将下载的Hadoop文件解压到指...

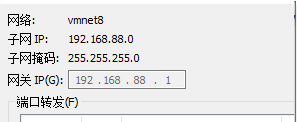
大数据成长之路------hadoop集群的部署 配置系统网络(静态) 新增集群(三台)
hadoop集群的部署配置系统网络(静态)配置系统网络(静态)第一步 查看虚拟机唯一标识(MAC地址)查看虚拟机设置00:0C:29:95:6F:C4MAC地址需要详细记录(很关键)第二步 调整70-persistent-net.rules文件删除掉红色框内的内容将eth1 改为eth0(当前网卡编...
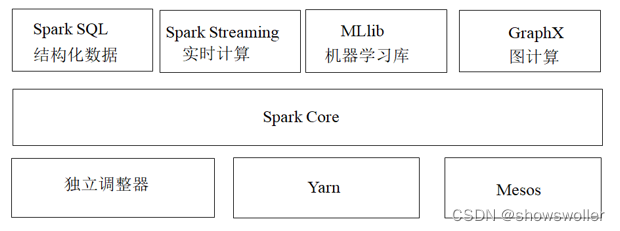
【大数据技术Hadoop+Spark】Spark架构、原理、优势、生态系统等讲解(图文解释)
一、Spark概述Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心...
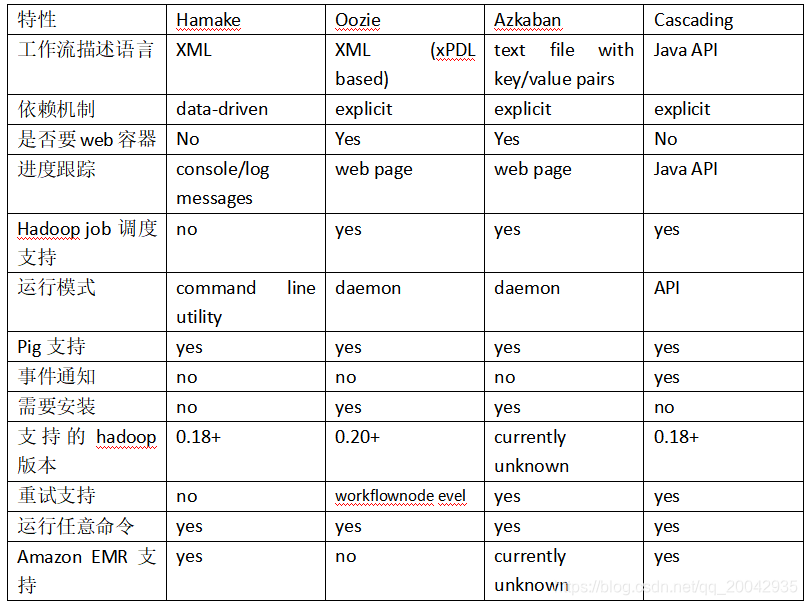
65 Hadoop工作流调度系统
为什么需要工作流调度系统?一个完整的数据分析系统通常都是由大量任务单元组成:shell脚本程序,java程序,mapreduce程序、hive脚本等各任务单元之间存在时间先后及前后依赖关系为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;例如,我们可能有这样一个需求,...
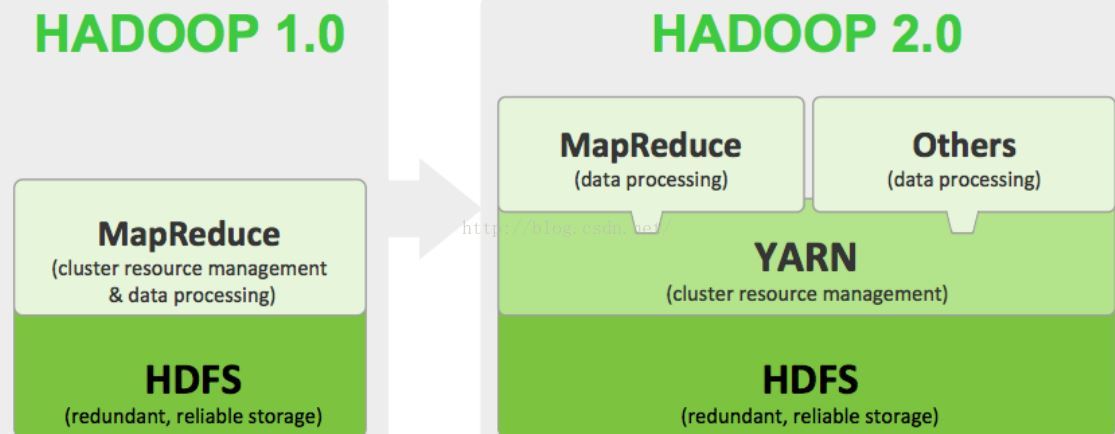
Hadoop生态系统特点
1、源代码开源(免费)2、社区活跃、参与者众多3、涉及分布存储和计算的方方面面4、已得到企业界届认同。HaDoop1.0与HaDoop2.0系统分布式存储系统HDFS( Hadoop Distributed File System)分布式存储系统提供了高可靠性、高扩展性和高吞吐率的数据存储服务资...

win系统hadoop启动时RM uses DefaultResourceCalculator问题解决
在启动hadoop时,使用start-all.cmd命令,只启动了dfs,ResourceManager没有启动 可以打开9870网页 但是无法打开localhost:8088 解决方法: 通过查询日志,找到 Error starting ResourceManager org.apache.had...

hadoop的系统认知
什么是Hadoop我们生活在一个数据大爆炸的时代,数据飞快的增长,急需解决海量数据的存储和计算问题 Hadoop适合海量数据 分布式存储 和 分布式计算Hadoop的作者是Doug Cutting,Hadoop这个名字是作者的孩子给他的毛绒象玩具起的名字Hadoop发行版介绍 目前Hadoop已经演...
Hadoop生态系统中的数据质量与数据治理:Apache Atlas和Apache Falcon的作用
Hadoop生态系统中的数据质量与数据治理:Apache Atlas和Apache Falcon的作用 引言:在大数据时代,数据的质量和治理是企业和组织中的关键问题。随着数据量的不断增加和数据来源的多样性,确保数据的正确性、一致性和可靠性是至关重要的。为了解决这些问题,Hadoop生态系统中涌现了许...
Hadoop生态系统中的数据质量与数据治理:Apache Atlas和Apache Falcon的作用
Hadoop生态系统是一个庞大的数据处理平台,用于存储和处理大规模的数据。然而,随着数据量不断增加,数据质量和数据治理变得越来越重要。为了解决这些问题,Apache Atlas和Apache Falcon成为了Hadoop生态系统中的两个重要组件。 Apache Atlas是一个开源的数据治理和元数...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








