产品系列
适用场景包含离线处理场景(数据清洗、数据规整等预处理操作)、多源聚合分析和拉宽场景、预测洞察(机器学习和AI)等业务场景。数仓版(3.0)弹性模式 数仓版(3.0)是基于计算存储分离架构打造的,支持海量数据实时写入可见及高性能在线...
引擎简介
云原生多模数据库 Lindorm 流引擎面向实时数据处理场景,支持使用标准的SQL及熟悉的数据库概念完成一站式的实时数据处理,适用于车联网、物联网和互联网中常见的ETL、实时异常检测和实时报表统计等场景。本文介绍Lindorm流引擎的应用场景和...
应用场景
访问频度极高业务 如社交网络、电子商务、游戏、广告等。...实现对大数据的分布式分析处理,适用于商业分析、挖掘等大数据处理场景。通过数据集成服务可自助实现数据在云数据库 Memcache 版与 MaxCompute 间的同步,简化数据操作流程。
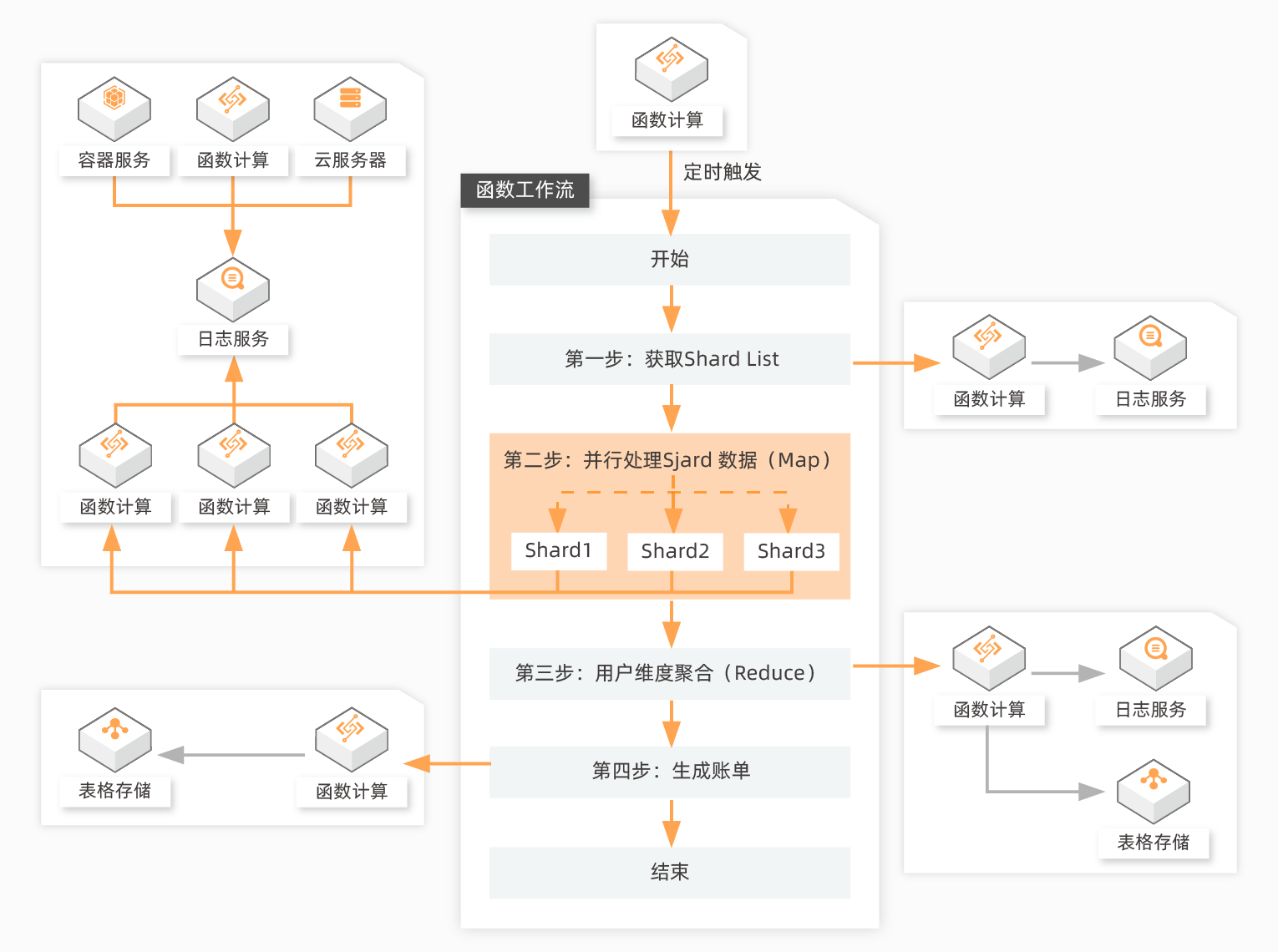
近实时增量导入
实际业务数据处理场景中,涉及的数据源丰富多样,可能存在数据库、日志系统或者其他消息队列等系统,为了方便用户将数据写入MaxCompute的Transactional Table 2.0,MaxCompute深度定制开发了开源 Flink Connector工具,联合DataWorks数据...
流水线自由交付模式
更多流水线功能 云效流水线Flow提供丰富的构建、测试、部署、人工卡点、通知等功能,详见 云效流水线 Flow。运行流水线进行应用发布 在编辑页面点击 保存并运行,或是在 流水线列表 点击 执行按钮 流水线开始执行。如果环境是首次部署,...
环境变量
环境变量来源 内置变量 云效流水线提供流水线基本信息、代码源相关内置变量,帮助定制化流程,可按需直接使用。功能模块 环境变量名 说明 基本信息 PIPELINE_ID 流水线 ID BUILD_NUMBER 流水线的运行编号,从1开始,按自然数自增 PIPELINE_...
管理流水线
新建流水线 进入 流水线 Flow>我的流水线,点击 新建流水线。根据你的开发语言和部署场景,选择合适的流水线模板,单击 创建 即可完成一条流水线创建,创建完成会自动进入流水线编辑页面。编辑流水线 进入流水线编辑页面,添加流水线源...
流水线简介
Serverless应用中心依托Serverless产品,为所有用户和平台提供平滑易用、灵活、易集成的流水线编辑以及执行能力,帮助用户在Serverless场景以及其他场景下,实现应用的持续集成和持续交付(CI/CD)。功能介绍 与开源产品GitHub Actions类似...
流水线简介
Serverless应用中心依托Serverless产品,为所有用户和平台提供平滑易用、灵活、易集成的流水线编辑以及执行能力,帮助用户在Serverless场景以及其他场景下,实现应用的持续集成和持续交付(CI/CD)。功能介绍 与开源产品GitHub Actions类似...
上手步骤
本文档仅适用于2019年6月13日之前创建并未迁移到新版持续交付流水线的企业,使用新版持续交付的企业(2019年6月13日前创建的企业都已经使用新版本),请参看 快速开始 在不同的使用场景里,配置和使用云效进行软件开发和发布的方法略有不同...