混合云数据库统一管理
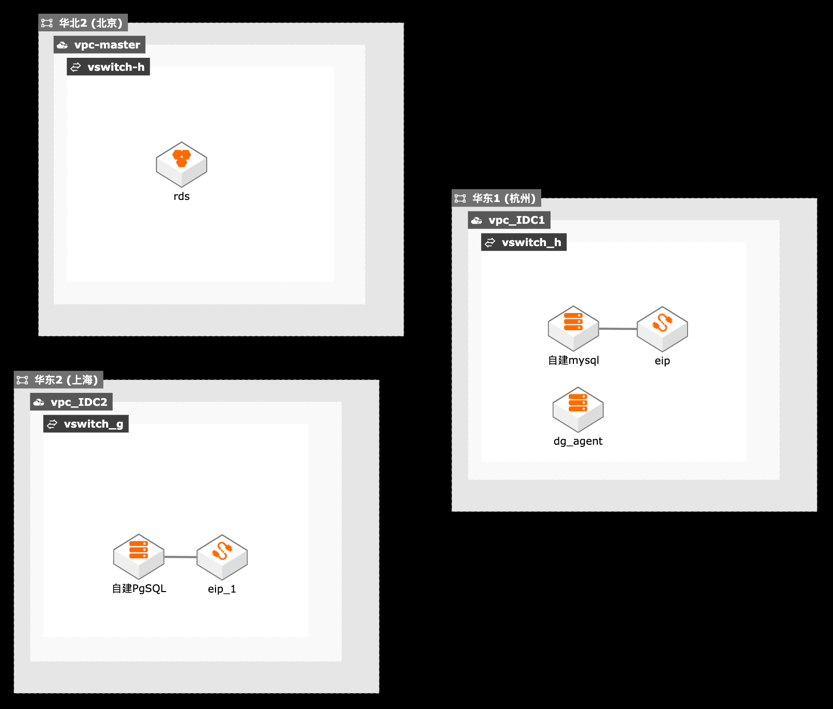
本最佳实践描述在混合云场景下,用户利用数据库网关将IDC自建数据库和云上RDS实例统一管理。通过DMS管理云上RDS实例和IDC自建数据库,并通过DTS实现IDC数据库和云上RDS的数据同步, DBS将数据备份到云上
其中杭州部署 MySQL数据库和数据库网关,上海部署 PgSQL数 据库。注意:上述模板中“自建 MySQL”和“自建 PgSQL”已经和公网 IP绑定,在部署完 数据库软件后,可以解绑公网 IP。模拟仅有内网 IP的数据库服务器。步骤3 部署所有资源。单击部署资源,单击下一步,直到完成资源部署。文档版本:20201224(发布日期)8 混合云...
云速搭部署数据库审计

本实践通过云速搭实现数据库审计的部署。
详 见 https://www.aliyun.com/product/ecs 云数据库 RDS:阿里云提供稳定可靠、可弹性伸缩的关系型云数据库 RDS,支持 MySQL、SQL Server、PostgreSQL、MariaDB和 PPAS引擎,具备容灾、备份、恢复、迁移等方面的全套解决方案。详见 https://help.aliyun.com/product/26090.html 数据库审计:数据库审计服务,可针对数据库 ...
基于MyBase构建自主可控数据库和高弹性应用实践
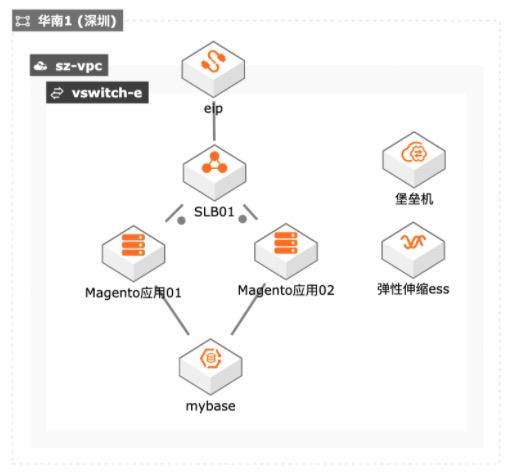
一些企业级客户上云前,会重点关心数据库是否自主可控,包括云资源独享、自主可运维、获取OS 权限等特点,同时又要兼顾数据库合规性、安全性和高性能的要求;并力求在业务弹性下合理利用云产品降低数据和应用成本,弹性地支持业务。本实践为此类用户提供相关实践参考。
云数据库专属集群为 客户独享云资源更加安全,用户既享受到云数据库服务的便捷灵活,又满足企业 对 数 据 库 合 规 性、安 全 性 和 高 性 能 的 要 求。详见:https://www.aliyun.com/product/apsaradb/cddc 堡垒机:集中管理资产权限,全程记录操作数据,实时还原运维场景,助力企业用 户构建云上统一、安全、高效运维...
多账号下企业分账
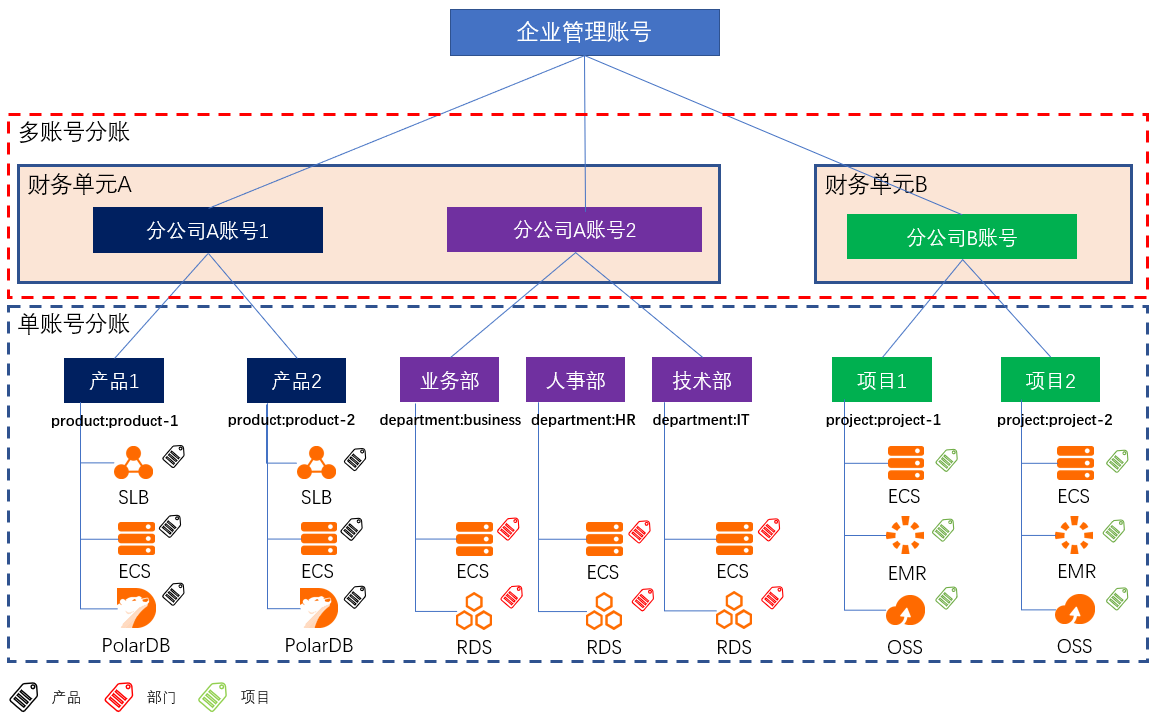
场景描述 财务分账,是根据企业的成本中心,将云上资源的成本划分到给各个项目组/业务部门;助力企业快速梳理云上成本结构,搭建复杂组织架构下的成本关系,便捷地进行财务和云上成本的管理。 大型企业或集团公司,由于组织架构复杂,业务复杂等原因,通常拥有多个阿里云账号来管理规模庞大的云上资源。针对云上资源,如何建立有效的分账方案,是财务关注的重要问题。 解决问题 解决CIO/CTO最关心的云上IT治理,IT成本核算等问题。 弄清楚企业内各部门成本及云上IT成本结构。 让CIO/CTO准确地掌握云上资源成本情况,清楚业务与成本的关系。 让采购/运维轻松搞定每月的IT成本汇报。
实例、集群、分拆项:资源类别 资源名称 分账粒度 弹性计算 云服务器 ECS 实例 存储 对象存储 OSS 分拆项(Bucket)数据库 云数据库RDS MySQL版 实例 数据库 云数据库 PolarDB 集群 网络 负载均衡 SLB 实例 大数据 E-MapReduce(EMR)集群 实例型:如 ECS、SLB、EIP等产品,支持在实例维度进行打标。集群型:如 E-Mapreduce...
基于云拨测的网站用户体验监测最佳实践
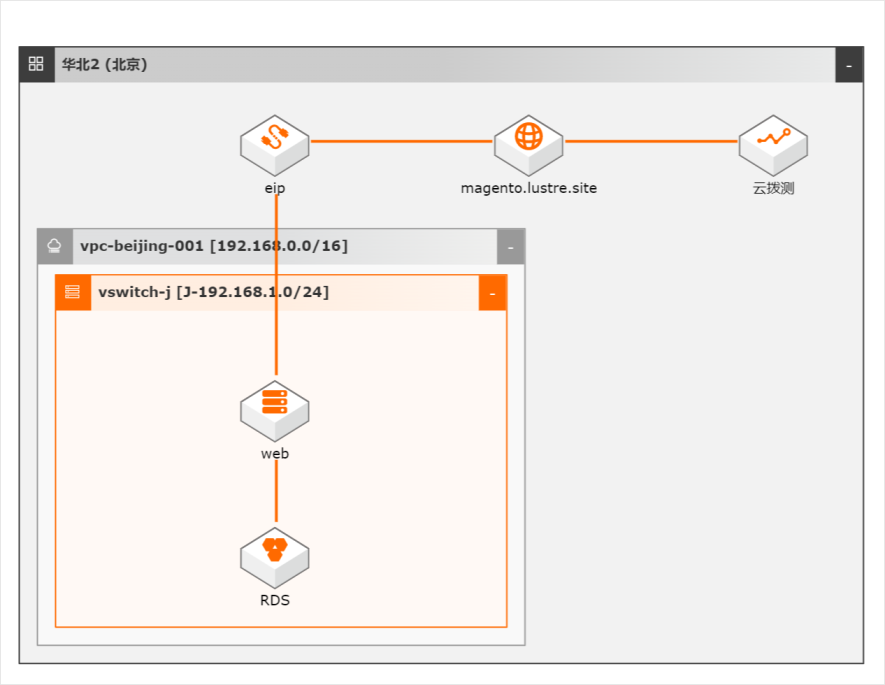
网站作为电商行业开展业务的核心场景,不同区域、不同运营商、不同的终端用户,给网站体验带来了巨大的一致性挑战。打开卡顿、缓慢,甚至无响应,都会影响到运营效果、甚至出现负面影响。阿里云基于多年业务经验,为云上客户提供完整的电商网站运营期间的用户体验监测方案。
更多信息,请参考:https://www.aliyun.com/product/ecs 云数据库 RDS MySQL 版:阿里云关系型数据库 RDS(Relational Database Service)是一种稳定可靠、可弹性伸缩的在线数据库服务。基于阿里云分布式文 件系统和 SSD盘高性能存储,RDS支持 MySQL、SQL Server、PostgreSQL、PPAS(高度兼容 Oracle)和 MariaDB引擎,并且...
Openstack迁移DDH
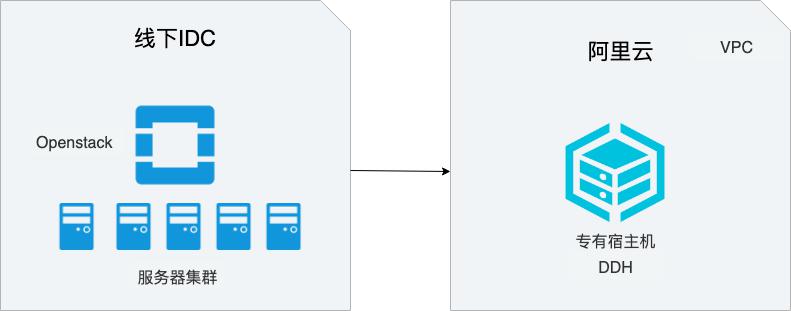
场景描述 在线下IDC中,很多用户使用OpenStack构建云环境,本 文介绍如何将线下IDC中基于OpenStack构建的云服务器 迁移到阿里云专有宿主机(DDH)上,从而实现业务平滑 上云的同时,显著降低成本。 解决问题 1.如何将OpenStack中的云服务器迁移 DDH上。 2.如何使用DDH构建云上环境。 产品列表 专有宿主机DDH 对象存储OSS 服务器迁移中心SMC 专有网络VPC
DatabaseService(Trove)数据库服务 DataProcessing(Sahara)数据处理 余下章节中,本文将构建一个OpenStack的模拟环境,并实际创建一个虚拟机实例,然后将这个虚拟机实例迁移到阿里云的DDH上。由于模拟环境资源限制,本文用于 演示的实例采用cirros操作系统,cirros是一个极简的定制化的云上OS,详见 ...
云上高并发系统改造
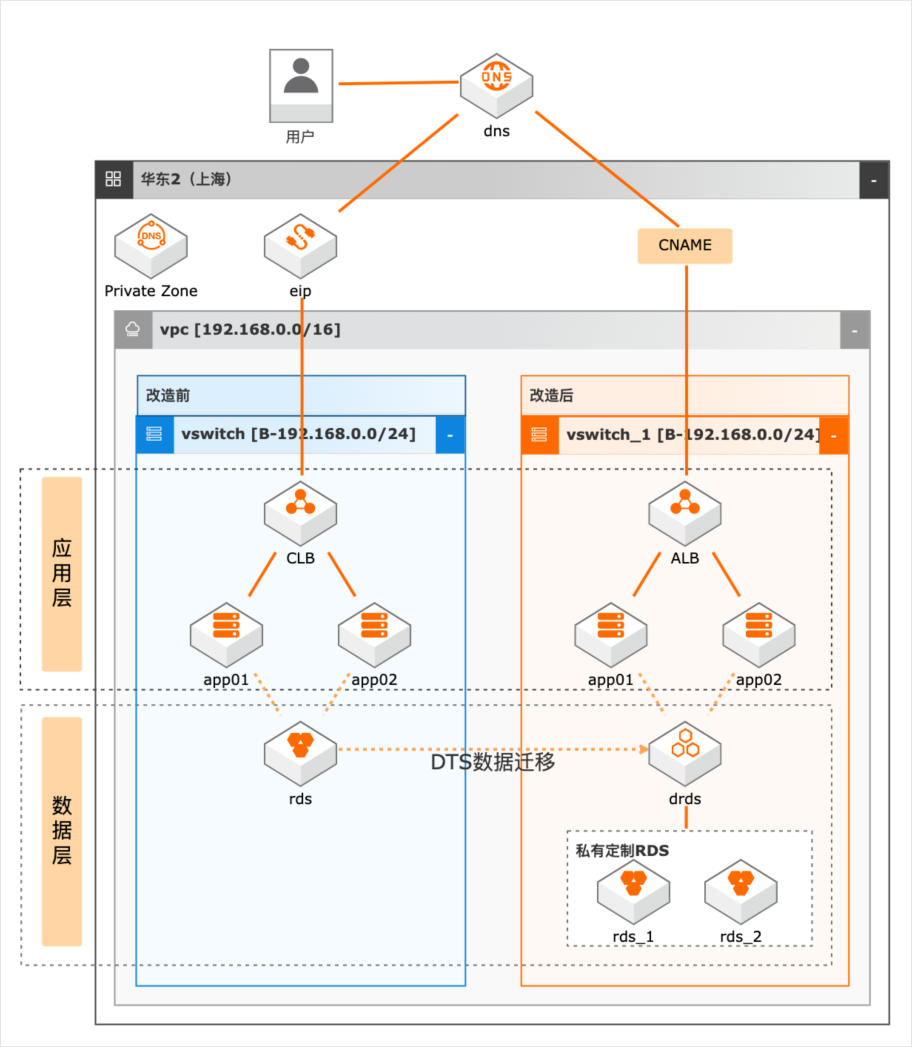
场景描述 随着业务的发展,系统并发压力越来越大,如何 进行系统改造以满足高并发场景的业务需求成 为了一个技术难题。本实践抽象于客户的实际场 景,提供高并发下系统改造的理论指导和部分实 操演示。主要适用于以下场景: 1.系统并发压力大,需要进行系统应用改造。 2.数据层并发压力大,需进行分库分表改造。 3.数据库数据量巨大,亟待分库分表解决查询 和写入瓶颈的场景。 方案优势/解决问题 1.在水平扩展阶段,我们除了通过SLB做负载 均衡外,我们可以通过SLB下挂nginx的方 式,增加负载均衡侧的可扩展性 2.在数据库拆分阶段,在做好数据规划后,我 们借助DTS进行数据迁移,通过DRDS将 RDS MySQL的数据拆分到多个分库和分 表中。 产品列表 专用网络VPC 负载均衡SLB 云服务器ECS 数据库RDSMySQL 数据传输服务DTS PrivateZone 分布式关系型数据库DRDS
云上高并发系统改造 最佳实践 场景描述 部署架构图 ...通常可以预估 1到 2 年的数据增长量,用估算出的总数据量除以总的物理分库数,再除以建议的最大数 据量 500万,即可得出每个物理分库上需要创建的物理分表数:物理分库上的物理分表数=向上取整(估算的总数据量/(RDS 实例数*8)/5,000,000)详细拆分 DEMO 可参考官网文 档:...
云速搭CADT部署PolarDB-X 1.0

通过云速搭 CADT 实现云原生分布式数据库 PolarDB-X 1.0 的部署。
步骤10 在导出价格清单对话框中,CADT会为您计算出应用所含资源的价格,包括原价、优 惠以及最终的实付价格,确认无误,再单击下一步:确认订单。文档版本:20220315 10 云速搭 CADT 部署 PolarDB-X 1.0 步骤11 在确认订单对话框中,勾选《云速搭服务条款》,单击下一步:支付并创建,就会进 入部署流程,这里会进行扣费并...
自建Hive数仓迁移到阿里云EMR
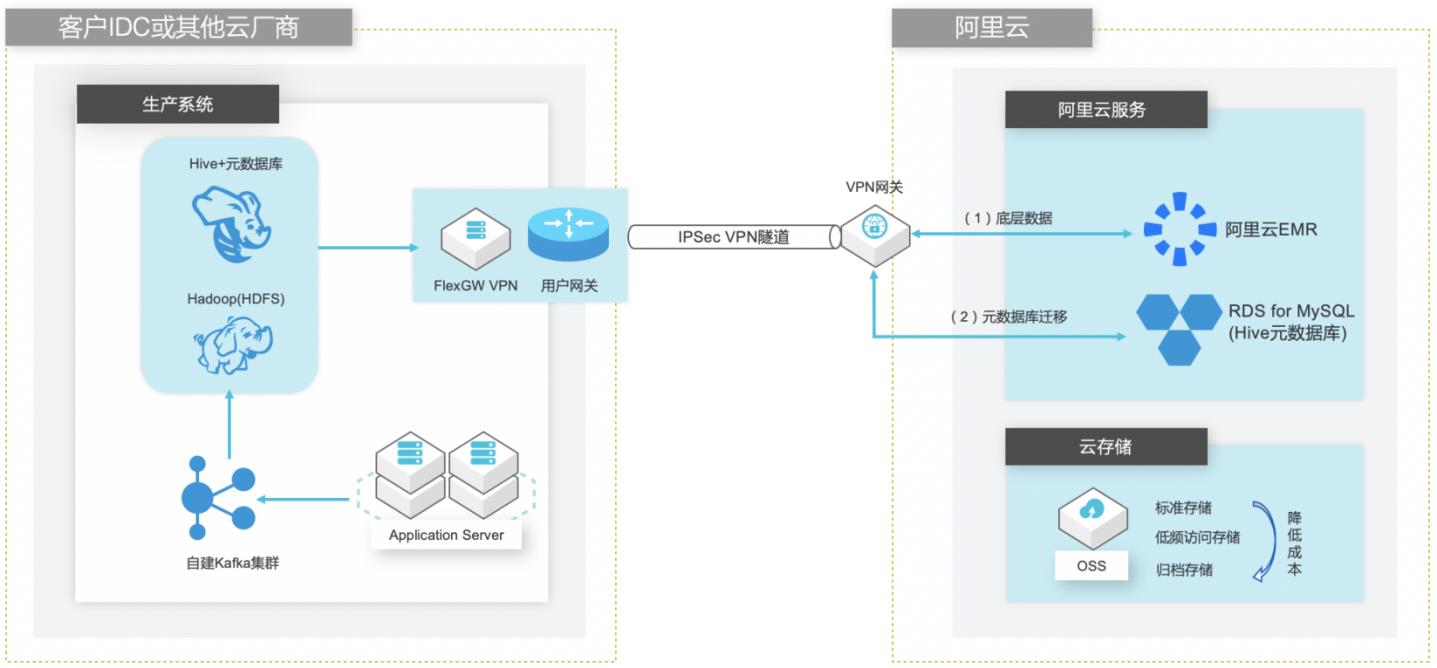
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
步骤2 部署完成后,重启 Hive MetaStore和 HiveServer2 步骤3 由于在创建 EMR集群时我们指定了 RDS for MySQL实例的数据库作为 Hive的元数 据库,但是此时元数据库还未创建,因此在 EMR控制台可以看到 Hive MetaStore服 务异常停止。文档版本:20210721 25 自建Hive数据仓库跨版本迁移到阿里云 EMR 创建 EMR集群 通过查看 ...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
阿里云最佳实践离线大数据workshop

本最佳实践,首先搭建一个简化的电商 demo 系统,然后为此 demo 系统构建一套离 线大数据分析系统。 实践目标 1. 学习搭建一个离线大数据分析系统,学习从数据采集到数据存储和业务分析的业 务流程。 2. 整个离线大数据分析系统全部基于阿里云产品进行搭建,学习掌运用各个服务组 件及各个组件之间如何联动。 背景知识要求 熟练掌握 SQL 语法 对大数据体系系统知识有一定的了解
详见:https://www.aliyun.com/product/ecs 云数据库RDSMySQL版:云数据库RDSMySQL版是全球最受欢迎的开源数据 库之一,作为开源软件组合LAMP(Linux+Apache+MySQL+Perl/PHP/Python)中 的 重 要 一 环,广 泛 应 用 于 各 类 应 用 场 景。详 见:https://www.aliyun.com/product/rds/mysql OSS:海量、安全、低成本...
来自:
最佳实践
相关产品:云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,日志服务(SLS),大数据计算服务 MaxCompute,DataV数据可视化,数据总线,Quick BI,云速搭
游戏数据运营融合分析
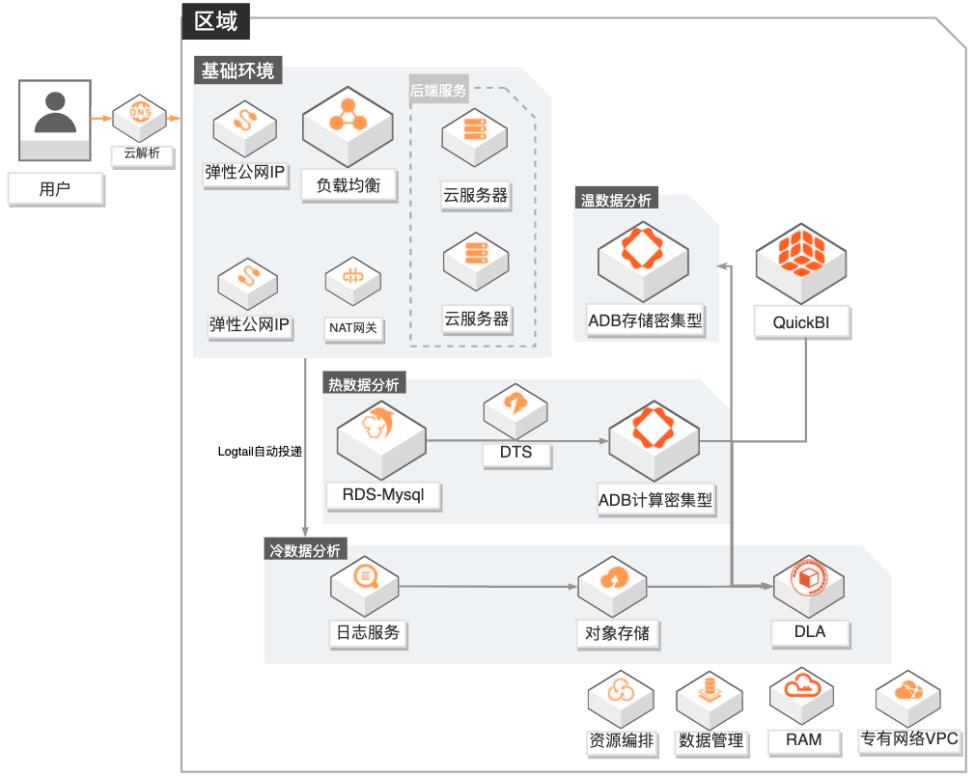
场景描述 1.游戏行业有结构化和非结构化数据融合分 析需求的客户。 2.游戏行业有数据实时分析需求的客户,无法 接受T+1延迟。 3.对数据成本有一定诉求的客户,希望物尽其 用尽量优化成本。 4.其他行业有类似需求的客户。 方案优势/解决问题 1.秒级实时分析:依托ADB计算密集型实例, 秒级监控DAU等数据,为广告投放效果提 供有力的在线决策支撑。 2.高效数据融合分析:打通结构化和非结构化 数据,支撑产品体验分析;广告买量投放效 果实时(分钟级)分析,渠道的评估更准确。 3.低成本:DLA融合冷数据分析+ADB存储密 集型温数据分析+ADB计算密集型热数据分 析,在满足各种分析场景需求的同时,有效 地降低的客户的总体使用成本。 4.学习成本低:DLA和ADB兼容标准SQL语 法,无需额外学习其他技术。 产品列表 专有网络VPC、负载均衡SLB、NAT网关、弹性公网IP 云服务器ECS、日志服务SLS、对象存储OSS 数据库RDSMySQL、数据传输服务DTS、数据管理DMS 分析型数据库MySQL版ADS 数据湖分析DLA、QuickBI
创建 ADB高性能库 步骤1 通过产品与服务导航,定位到分析型数据库 MySQL版,单击进入 AnalyticDB控 制台。步骤2 切换地域为华东 2(上海),在左侧导航栏选择集群列表,并单击新建集群。步骤3 选择按量付费模式,完成以下配置,并单击立即购买。文档版本:20210224 37 游戏数据运营融合分析 部署 RDS-ADB高性能库数据采集 ...
CDH迁移升级CDP最佳实践
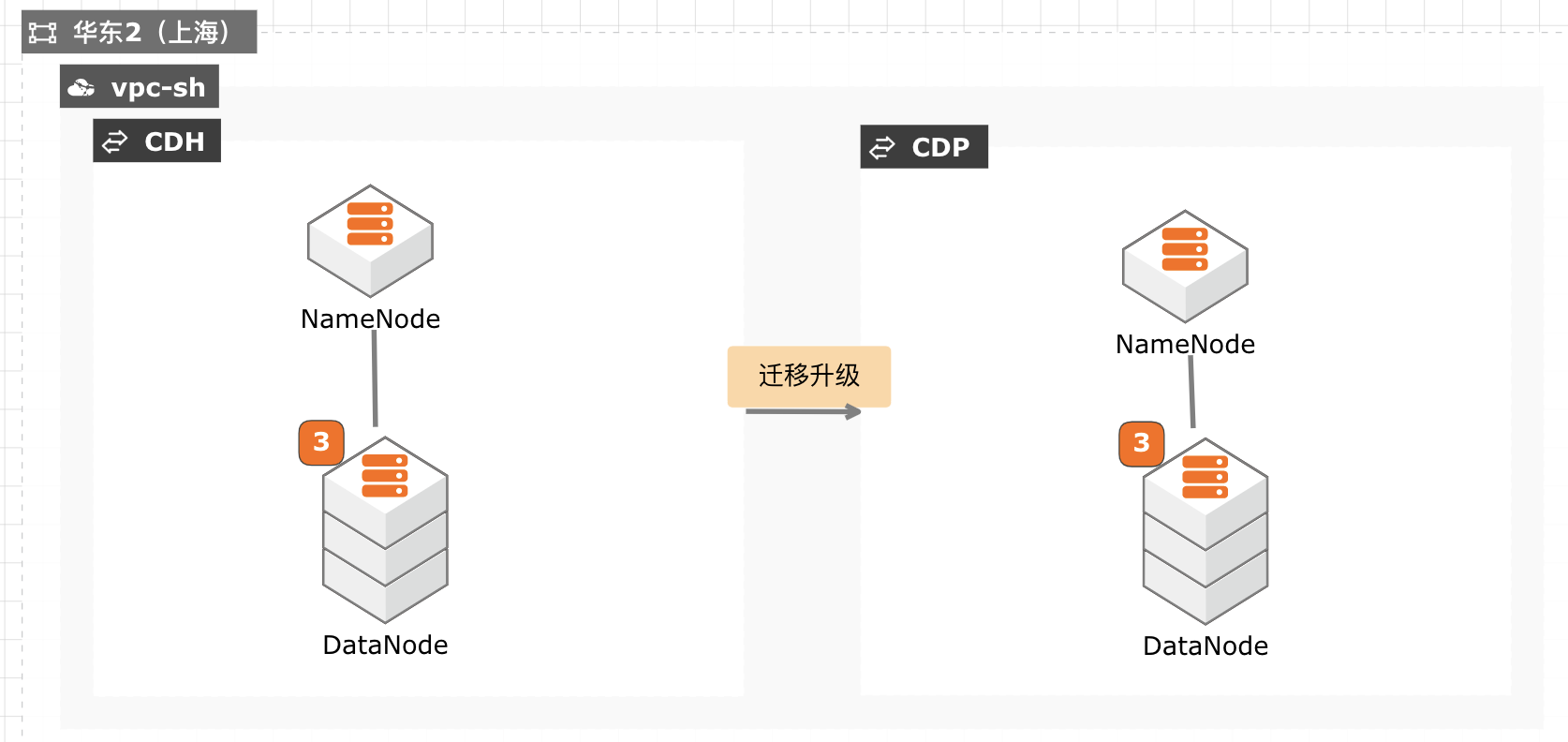
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
CDH迁移升级 CDP 最佳实践 业务架构 场景描述 解决的问题 CDH升级至 CDP 当前 CDH免费版停止下载,终止服务,针对需要企业版 服务能力并且 CDH升级过程对业务影响较小的客户,通 要求升级过程无数据丢失风险 过安装新的 CDP集群,将现有数据拷贝至新集群,然后 要求升级宕机时间及短 将新集群切换为生产集群,升级过程没有...
自建Hadoop迁移MaxCompute
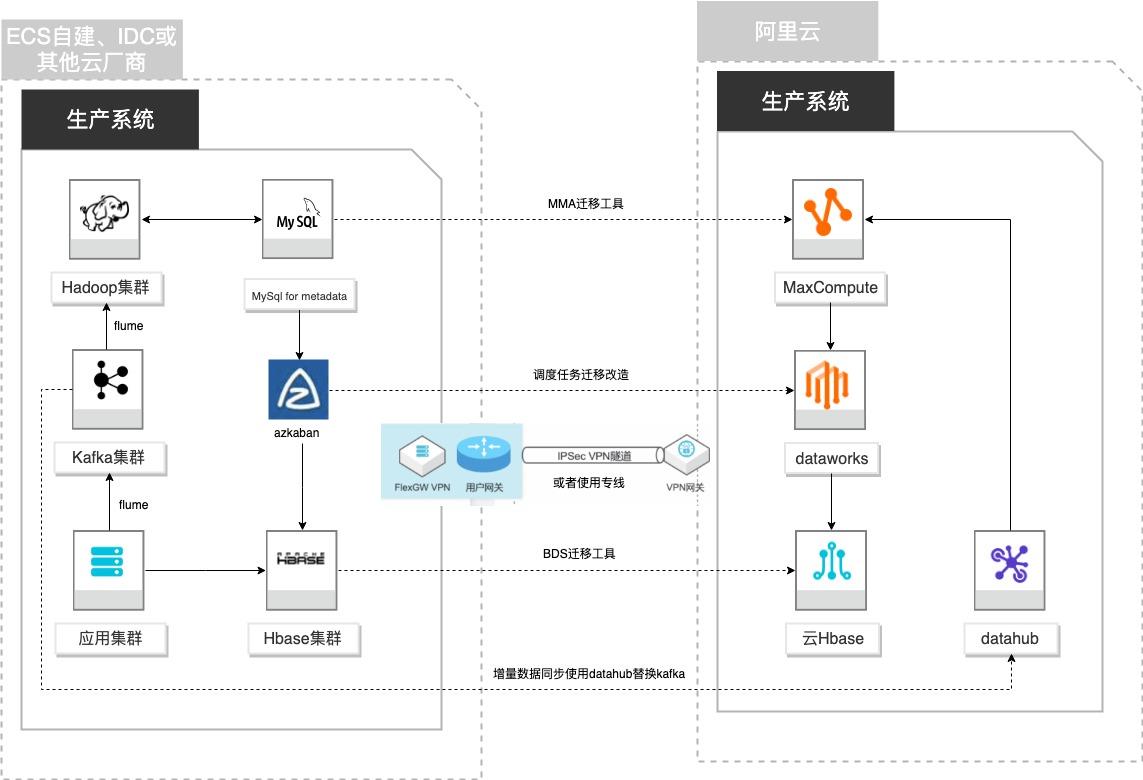
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
文档版本:20210723 30 自建Hadoop迁移MaxCompute Hbase表数据迁移到云数据库 Hbase版 4.Hbase表数据迁移到云数据库 Hbase版 4.1.创建 BDS集群 BDS 是阿里云针对 HBase自主研发的一套迁移同步服务,主要帮助云上的客户进行 自建 HBase、云 HBase集群的数据导入和导出。步骤1 通过连接登录到云数据库 Hbase版控制台 ...
基于Flink+ClickHouse构建实时游戏数据分析
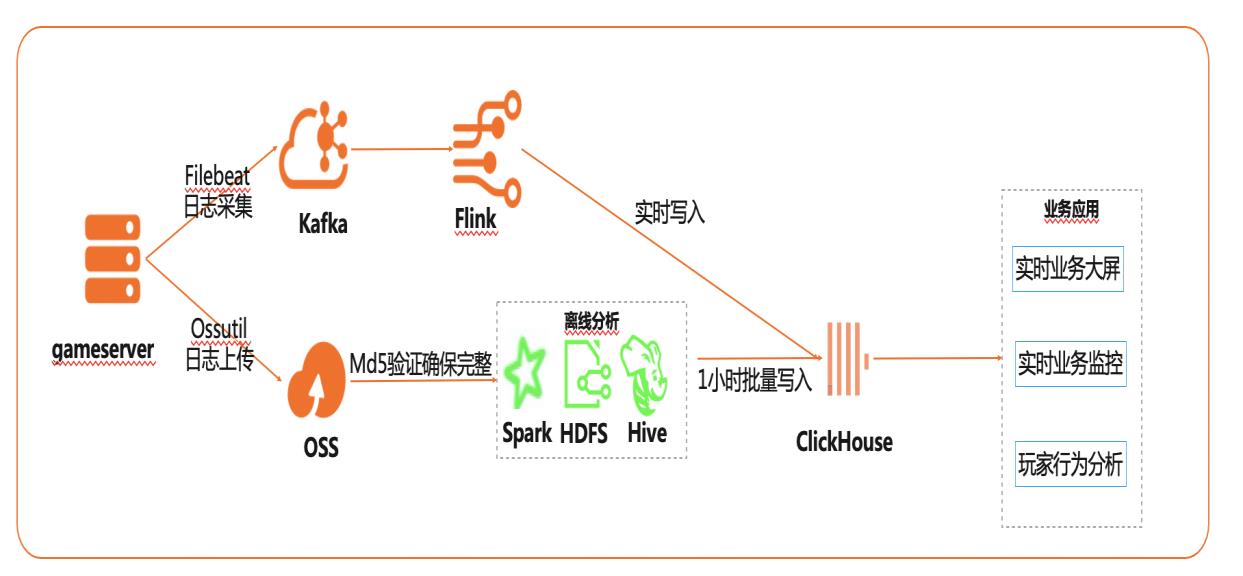
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
关键技术选型 1.1.ClickHouse vs Presto 面对海量的数据,我们如何进行数据库的选项,这里对比了开源的两种常见分析性数 据库。ClickHouse对数据采用有序存储的方式,其核心思想是充分利用了磁盘批量顺序读写 的性能要远远高于随机读写的特征,并且结合 LSM tree的设计进一步进行优化,使得 写性能达到最优(可达到 200MB/S...
Function Compute构建高弹性大数据采集系统
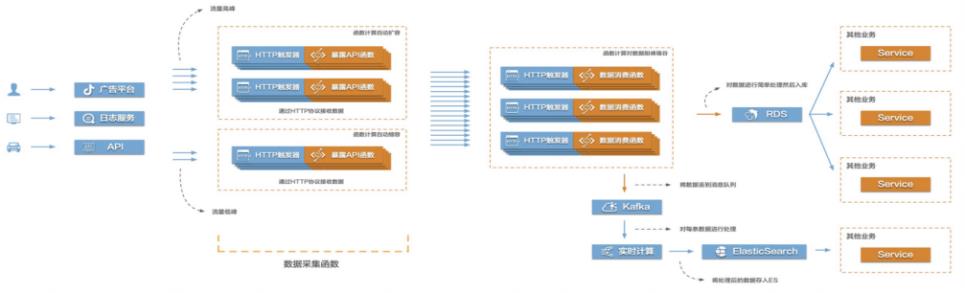
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
产品列表 专有网络 VPC 日志服务 SLS 链路追踪 Tracing Analysis 云服务器 ECS 云数据库 RDS 最佳实践频道 阿里云最佳实践技术分享群 函数计算 FC 消息队列 Kafka 版 性能测试 PTS 云速搭 CADT 如二维码过期,请搜索群号:31852400 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 Function Compute构建...
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
云消息队列 Kafka 版支持连接自建 Logstash服务,实现丰富的数据源导入和导出.Filebeat 日志收集.云消息队列 Kafka 版支持连接自建 Filebeat 日志采集,经由 Kafka 流转到后方 ES 服务.Hbase、Spark 数据处理.云消息队列 Kafka 版数据导入 Hbase 等存储,实现低成本存储和计算分析.Flink 实时数仓.云消息队列 Kafka 版支持...
来自:
云产品
EMR集群安全认证和授权管理
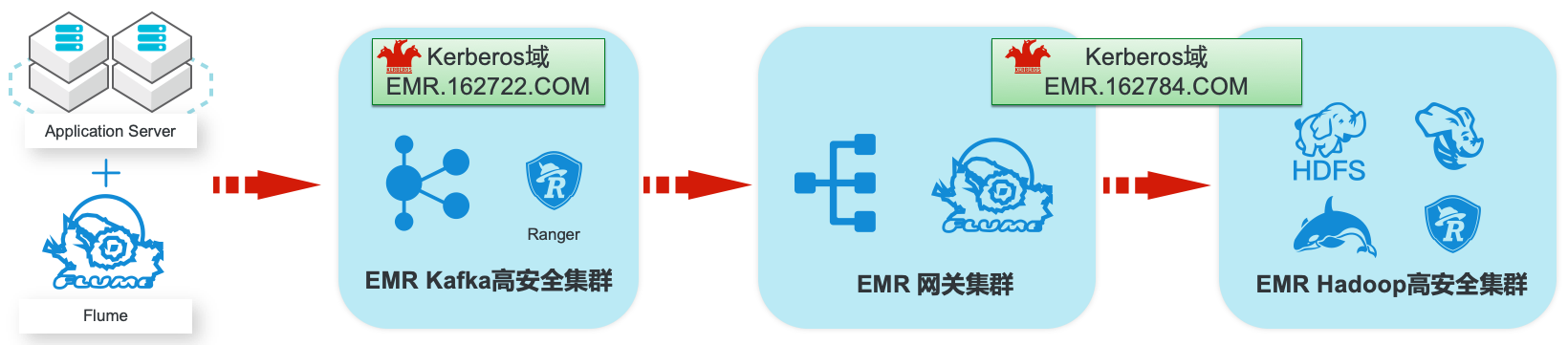
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
详见:https://web.mit.edu/kerberos/krb5-1.4/krb5-1.4.1/doc/krb5- admin/domain_realm.html [capaths]为了执行直接(非分层)跨领域身份验证,需要一个数据库来构造领域 之间的 身份 验 证路径,本节用于定 义该 数 据库。详见:https://web.mit.edu/kerberos/krb5-1.4/krb5-1.4.1/doc/krb5-admin/capaths.html 文档版本...
基于链路追踪+ECI的流量洪峰应对
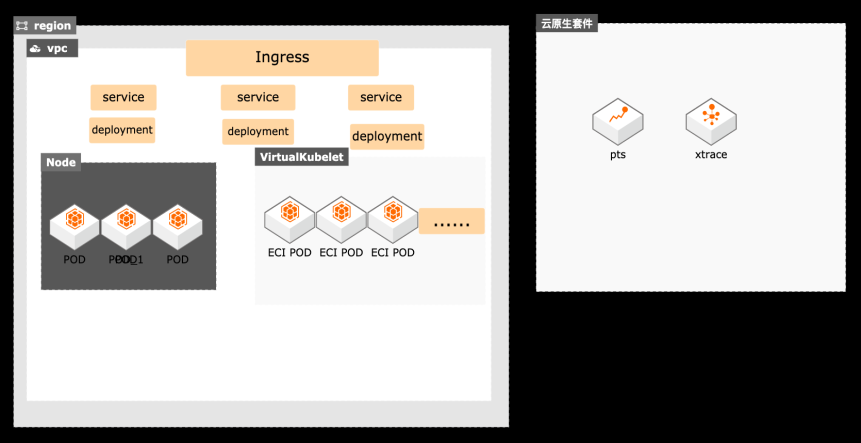
云原生技术已经为越来越多的互联网客户接受,对于在线教育、互动娱乐、电商等类型的客户会由于业务的原因存在突增业务流量,因此对于系统的稳定性非常关注,结合阿里云的容器服务、链路追踪、弹性容器ECI等产品,帮助客户业务实现容器化改造,并且方便发现系统应用架构中的瓶颈等问题,实现系统高弹性的同时优化客户的云资源使用成本。 l 方案优势 ᅳ 支持分布式追踪、调用链分析、DB调用分析、链路拓扑分析、业务指标统计等系统链路调用分析。 ᅳ 运维研发效率提高,链路追踪服务端全托管,免运维。 ᅳ 链路追踪的应用调用链分析能力结合ECI高弹性能力,提升应用系统在洪峰流量冲击下的稳定性。 ᅳ 链路追踪接入方便,ECI POD弹性伸缩,节省用户运维成本和云资源使用成本。 ᅳ 结合SLS Ingress可以基于应用前端访问性能指标做弹性伸缩,更丰富的云原生弹性能力。
文档版本:20201222 9 基于链路追踪+ECI的应用高可用弹性实践 应用部署 环境变量 SQL_ENVIRONMENT配置 mysql的访问地址,按照 1.3章节创建的数 据库服务访问地址进行配置,如下图所示:环境变量 TRACE_ENDPOINT配置链路跟踪接入点地址,获取方式如下:a.登录链路跟踪控制台(https://tracing.console.aliyun.com/)b.获取到...
- 产品推荐
- 这些文档可能帮助您