基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。相关命令可以浏览 https://code.aliyun.com/best-practice/199
数据仓库:数据仓库概念最早来源于数据库领域,主要处理面向数据的复杂查询 和分析场景。数据仓库是来自一个或多个不同源的集成数据的中央存储库,经过 数据清洗和转化,将当前和历史数据存储在一起,用于为整个企业的员工创建分 析报告。阿里云 MaxCompute就是数据仓库和云原生技术相结合的云数仓产品。EMR:阿里云 E-...
智能数据建设与治理Dataphin
Dataphin遵循阿里巴巴集团多年实战沉淀的大数据建设OneData体系(OneModel、OneID、OneService),集产品、技术、方法论于一体,一站式地为您提供集数据引入、规范定义、智能建模研发、数据萃取、数据资产管理、数据服务等的全链路智能数据构建及管理服务。助您打造属于自己的标准统一、资产化、服务化和闭环自优化的智能数据体系,驱动创新。
客户应用案例.立即开通(全托管版).立即开通(半托管版).立即开通(全托管版).立即开通(半托管版).<查看全部产品.Dataphin是阿里巴巴...可视化数据仓库模型构建、物理任务全托管生产,分钟级自动化代码生成.数据资产化管理,全链路数据追踪和分析,提升数据价值.数据资产管理.自动聚合主题数据,所见即所得,高度简化查询与分析.
来自:
云产品
数据安全解决方案
数据是企业的核心资产,如何保护企业的云上数据,是每个企业管理者都应当重视的课题。在云平台提供更为安全便捷的数据保护能力的同时,阿里云根据自身多年的经验积累,结合大量云上客户的最佳实践,提供了一套完整的数据安全解决方案,帮助企业提升云上数据风险防御能力,实现企业核心及敏感数据安全可控。
数据不再单纯存储在数据库中,各类数据仓库、中台和非结构化文件、缓存都在企业中扮演着重要角色。分散数据的统一治理和权责定义,对企业提出了要求.数据资产盘点、权责明确与分类分级标准.数据安全风险评估是企业信息系统建设的根基,从多个维度进行安全评估可以达到“事半功倍”的效果。在分析的过程中结合数据生命周期各...
来自:
解决方案
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
Spark on Kubernetes解决方案的用户 对 Spark大数据分析平台计算资源成本控制考虑的用户 需要有灵活可扩展计算平台资源弹性及管控的用户 名词解释 文件存储 HDFS:阿里云文件存储 HDFS是面向阿里云 ECS实例及容器服务等计 算资源的文件存储服务,允许用户像在 Hadoop分布式文件系统中管理和访问数 据,无需对数据分析应用做...
云原生数据库
PolarDB是阿里云自研的云原生数据库,在存储计算分离架构下,利用了软硬件结合的优势,为用户提供秒级弹性、高性能、海量存储、安全可靠的数据库服务。100%兼容MySQL和PostgreSQL生态,支持分布式扩展,高度兼容Oracle语法。
高度兼容MySQL,打通大数据生态,通过将数据实时同步至云原生数据仓库 AnalyticDB,实现对海量数据的实时分析,助力业务智能化.云数据库RDS MySQL.数据传输DTS.云原生数据仓库ADB MySQL.推荐搭配产品.交通物流:每秒万级并发.在线业务超高并发,轻松解决.电商行业中如大型促销秒杀场景对系统整体访问压力巨大。PolarDB ...
来自:
云产品
阿里云最佳实践离线大数据workshop

本最佳实践,首先搭建一个简化的电商 demo 系统,然后为此 demo 系统构建一套离 线大数据分析系统。 实践目标 1. 学习搭建一个离线大数据分析系统,学习从数据采集到数据存储和业务分析的业 务流程。 2. 整个离线大数据分析系统全部基于阿里云产品进行搭建,学习掌运用各个服务组 件及各个组件之间如何联动。 背景知识要求 熟练掌握 SQL 语法 对大数据体系系统知识有一定的了解
MaxCompute向用户提供了完善的数据导入方 案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有 效 降 低 企 业 成 本,并 保 障 数 据 安 全。详 见:https://help.aliyun.com/product/27797.html Dataworks:DataWorks基于MaxCompute/EMR/MC-Hologres等大数据计算引 文档版本:20210802(发布...
来自:
最佳实践
相关产品:云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,日志服务(SLS),大数据计算服务 MaxCompute,DataV数据可视化,数据总线,Quick BI,云速搭
SLS多云日志采集、处理及分析
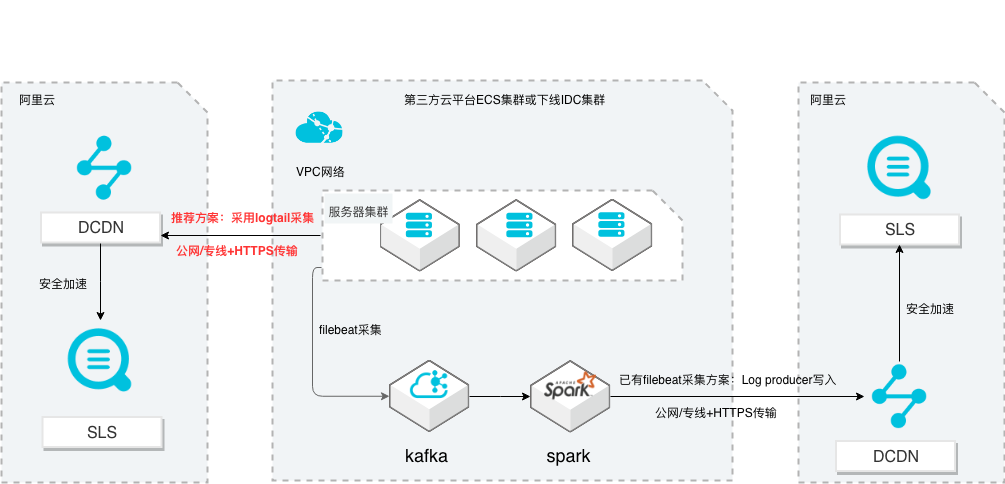
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
提供用户在云上 使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习 等场景下的大数据解决方案。更多信息,请参见专有 E-MapReduce简介(https://www.aliyun.com/product/emapreduce)。全站加速 DCDN:旨在提升动静态资源混合站点的访问体验,支持静态资源边缘 缓存,动态内容最优路由回源传输,...
EMR集群安全认证和授权管理
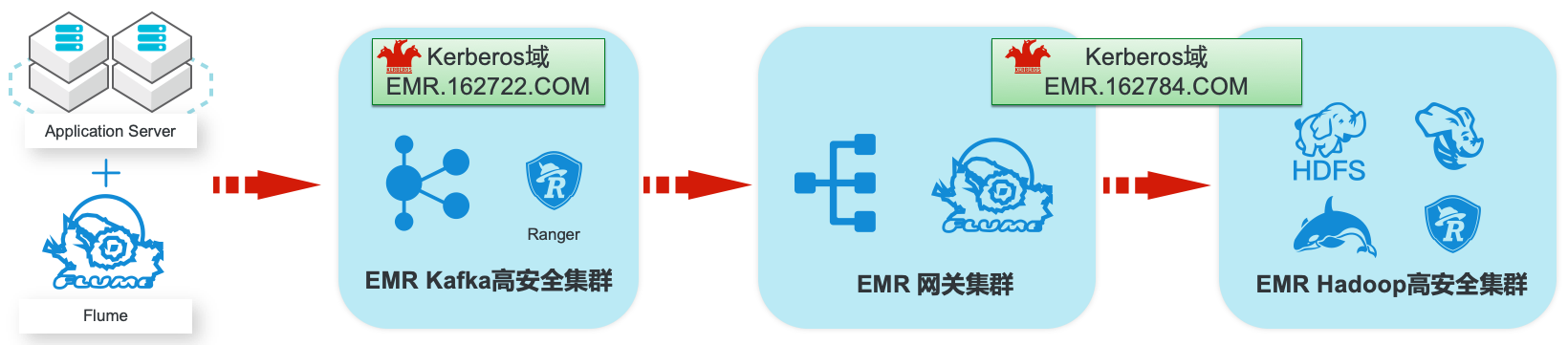
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
提供 用户在云上使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机 器 学 习 等 场 景 下 的 大 数 据 解 决 方 案。详 情 请 查 看 www.aliyun.com/product/emapreduce Kerberos:Kerberos是一种网络身份验证协议,它旨在通过使用密钥加密为客户 端/服务器应用程序提供强身份验证。它提供了网络上的身份...
云基础产品与基础设施
云基础产品与基础设施作为阿里云产品六大版块之一,主要包含弹性计算、存储、网络、安全、云原生应用平台以及无影和基础设施类产品,向客户提供高度自动化的标准化产品对网络功能、计算机(虚拟或专用硬件)和数据存储空间进行访问,同时支持灵活扩展,可以直接使用自助服务界面。
通过阿里云文件存储CPFS和对象存储OSS数据湖存储及数据自由流动解决方案,满足从海量数据采集到清洗、标注、训练到归档的数据自动化,提供了自动驾驶研发云的统一数据平台,极大提升了研发效率.文件存储 CPFS.对象存储 OSS.网络安全升级支持IPV6.杭州悦数科技有限公司与阿里云计算巢达成合作,NebulaGraph 作为首款图数据库...
来自:
云产品
混合云自有K8S弹性使用ECI
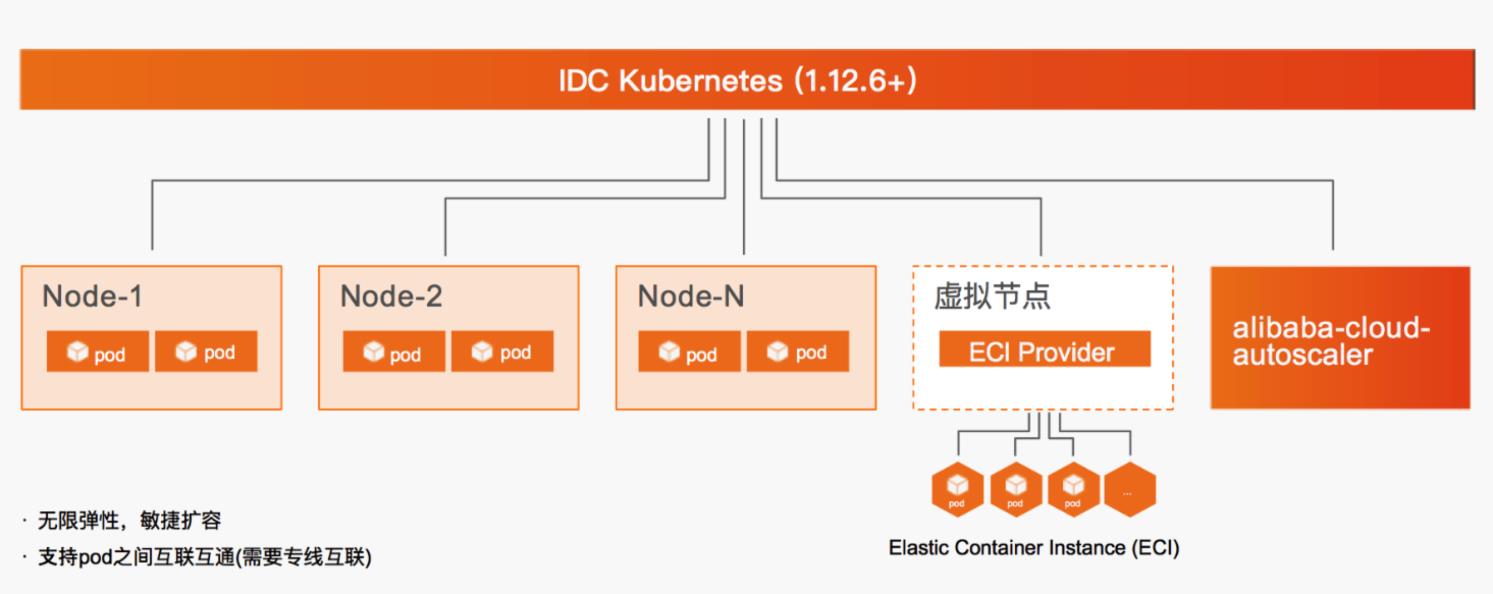
场景描述 本文介绍线下IDC与云端通过专线构建混合云架构,自有K8S利用虚拟节点弹性调用ECI承载业务高峰期资源需求的最佳实践。 解决问题 混合云环境下,自有K8S集群注册至ACK,实现云端纳管。纳管K8S集群部署Virtual Node,使集群具备ECI资源调度能力。在以上环境中部署Web及离线作业应用,并使用ECI资源作为弹性资源池满足业务波峰需求。 产品列表 云服务器ECS 云架构设计工具CADT 专有网络VPC 访问控制RAM 云企业网CEN 弹性容器实例ECI Nat网关NAT 容器镜像服务ACR 负载均衡SLB 容器服务Kubernetes版ACK 弹性公网IPEIP
注:实际当扩展 WordPress Pod实例时,需要使用统一的持久化存储来保证数 据一致性。本例中重点介绍 ECI的资源使用,故此处简化略去。步骤6 完成以上修改后,在 namespace blog下创建 WordPress应用。文档版本:20210520 49 混合云 IDC自有 K8S弹性使用 ECI ECI使用示例 步骤7 创建完成后,点击返回箭头确认应用状态。文档...
CDH迁移升级CDP最佳实践
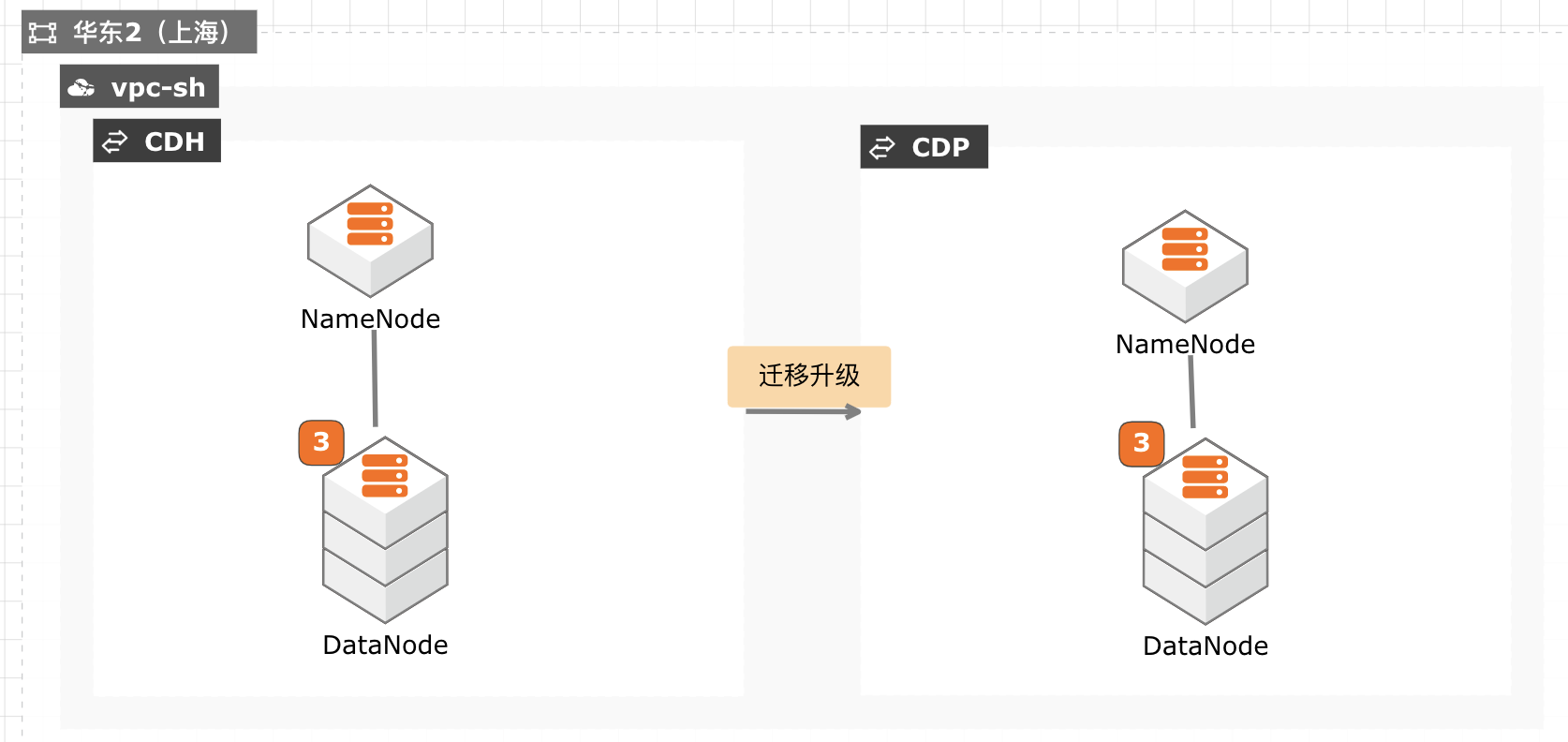
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
构造 Impala测试数据 由于 Impala不支持 date类型数据,所以讲原始 date数据转化为 varchar类型的数 据。Alter table call_center change column cc_rec_start_date cc_rec_start_date varchar(10);Alter table call_center change column cc_rec_end_date cc_rec_end_date varchar(10);Alter table date_dim change column...
基于链路追踪+ECI的流量洪峰应对
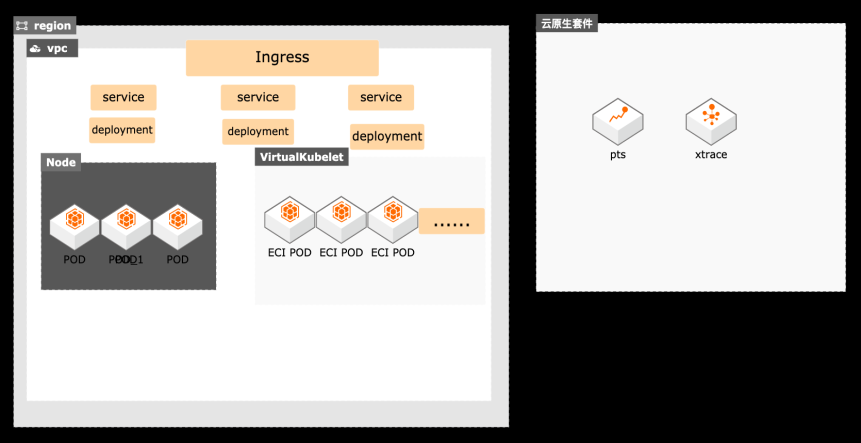
云原生技术已经为越来越多的互联网客户接受,对于在线教育、互动娱乐、电商等类型的客户会由于业务的原因存在突增业务流量,因此对于系统的稳定性非常关注,结合阿里云的容器服务、链路追踪、弹性容器ECI等产品,帮助客户业务实现容器化改造,并且方便发现系统应用架构中的瓶颈等问题,实现系统高弹性的同时优化客户的云资源使用成本。 l 方案优势 ᅳ 支持分布式追踪、调用链分析、DB调用分析、链路拓扑分析、业务指标统计等系统链路调用分析。 ᅳ 运维研发效率提高,链路追踪服务端全托管,免运维。 ᅳ 链路追踪的应用调用链分析能力结合ECI高弹性能力,提升应用系统在洪峰流量冲击下的稳定性。 ᅳ 链路追踪接入方便,ECI POD弹性伸缩,节省用户运维成本和云资源使用成本。 ᅳ 结合SLS Ingress可以基于应用前端访问性能指标做弹性伸缩,更丰富的云原生弹性能力。
文档版本:20201222 9 基于链路追踪+ECI的应用高可用弹性实践 应用部署 环境变量 SQL_ENVIRONMENT配置 mysql的访问地址,按照 1.3章节创建的数 据库服务访问地址进行配置,如下图所示:环境变量 TRACE_ENDPOINT配置链路跟踪接入点地址,获取方式如下:a.登录链路跟踪控制台(https://tracing.console.aliyun.com/)b.获取到...
ACK容器平台集群安全控制
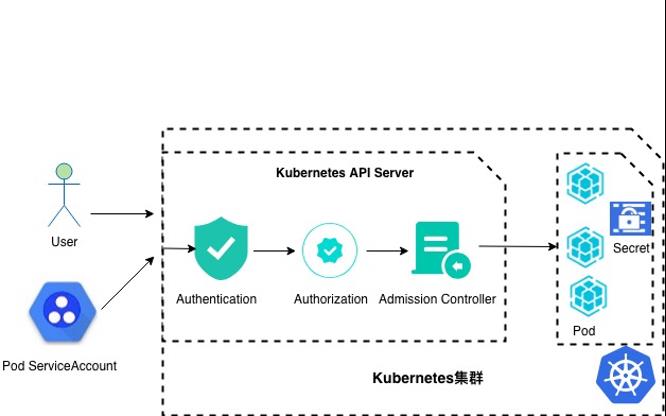
场景描述 本方案实践主要是通过一些实践示例来介绍 用户对于在阿里云上使用Kubernetes集群服 务的容器平台安全管控的实践验证与使用建 议。 方案优势 容器集群部署快捷 授权与安全策略配置方便 丰富的安全控制实践介绍 解决问题 容器集群API Server的安全访问控 制 容器服务多租户场景下的授权管理 容器中的敏感信息数据的存储 容器服务集群安全策略配置管理 产品列表 容器服务Kubernetes版 负载均衡SLB 专有网络VPC 访问控制RAM
文档版本:20220207 43 ACK容器平台集群安全控制最佳实践 Kubernetes集群敏感信息防护 4.Kubernetes集群敏感信息防护 4.1.Kubernetes的 Secret概念 在容器配置时有时需要包含一些敏感数据,例如证书和私钥,需要确保其安全性。为 了存储与分发此类信息;Secret的使用方式可以为:将 Secret作为环境变量传递给容器 将 Secret...
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
通过简单几步配置即可将RDS、PolarDB 或者日志服务中某个日志库中的数据快速同步到云原生数据仓库AnalyticDB MySQL版集群中.将RDS和PolarDB的多个数据库实例一键配置DTS同步链路.数据库数据接入.配置SLS数据同步链路,将日志数据快速接入.日志数据接入.AnalyticDB MySQL使用文档.快速上手AnalyticDB MySQL.查看API使用文档....
来自:
云产品
云原生数据仓库AnalyticDB PostgreSQL版
阿里云MPP架构的云原生数据仓库,可提供PB级海量数据在线/离线分析服务,是面向各行各业的有竞争力的数仓方案,真正做到“人人可用的数据分析服务”。
用户现有的OLTP数据库实例,包括 RDS MySQL,PostgreSQL,或传统数据库实例 Oracle,SQL Server等,数据可以通过 数据传输服务 DTS,数据集成服务 Dataworks 等实时同步到云原生数据仓库AnalyticDB PostgreSQL版,构筑可线性扩展的在线企业数据仓库服务。同时可以结合 Dataworks 的 ETL 调度功能,基于 AnalyticDB for ...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
游戏数据运营融合分析
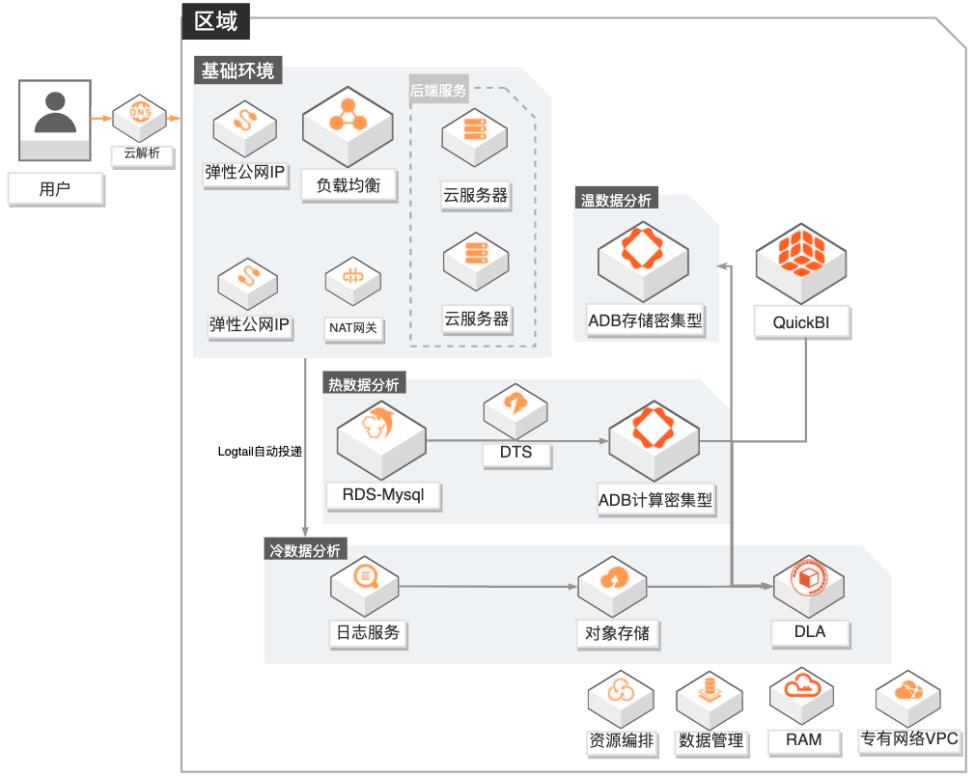
场景描述 1.游戏行业有结构化和非结构化数据融合分 析需求的客户。 2.游戏行业有数据实时分析需求的客户,无法 接受T+1延迟。 3.对数据成本有一定诉求的客户,希望物尽其 用尽量优化成本。 4.其他行业有类似需求的客户。 方案优势/解决问题 1.秒级实时分析:依托ADB计算密集型实例, 秒级监控DAU等数据,为广告投放效果提 供有力的在线决策支撑。 2.高效数据融合分析:打通结构化和非结构化 数据,支撑产品体验分析;广告买量投放效 果实时(分钟级)分析,渠道的评估更准确。 3.低成本:DLA融合冷数据分析+ADB存储密 集型温数据分析+ADB计算密集型热数据分 析,在满足各种分析场景需求的同时,有效 地降低的客户的总体使用成本。 4.学习成本低:DLA和ADB兼容标准SQL语 法,无需额外学习其他技术。 产品列表 专有网络VPC、负载均衡SLB、NAT网关、弹性公网IP 云服务器ECS、日志服务SLS、对象存储OSS 数据库RDSMySQL、数据传输服务DTS、数据管理DMS 分析型数据库MySQL版ADS 数据湖分析DLA、QuickBI
更多信息,请参见:help.aliyun.com/document_detail/32321.html AnalyticDB(简称 ADB):分析型数据库 MySQL版(AnalyticDB for MySQL)是一种高并发低延时的 PB 级实时数据仓库,全面兼容 MySQL 协议以及 SQL:2003 语法标准,可以毫秒级针对万亿级数据进行即时的多维分析透视和 业务探索。更多信息,请参见:help.aliyun...
在线教育流量洪峰
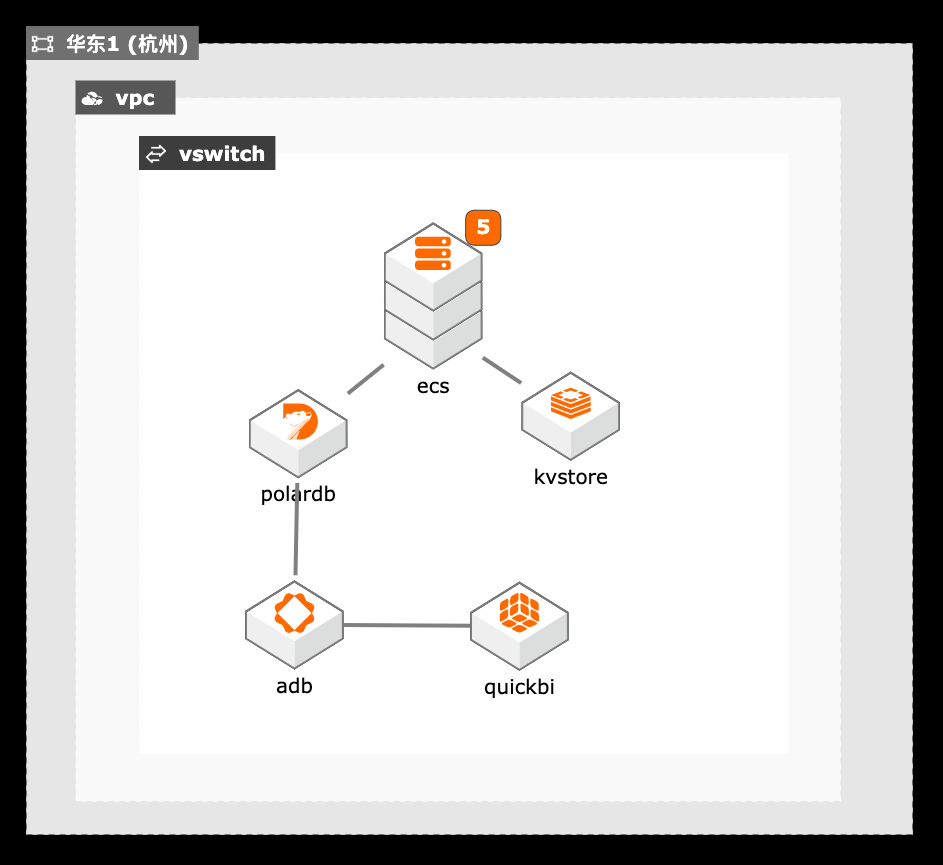
1. 通过Tair缓存的性能增强型解决高并发读的性能问题,通过持久内存型解决大并发写性能及数据可靠性问题。 2. PolarDB作为主数据库保存业务的交易数据,通过弹性能力和并发SQL解决性能瓶颈。 3. ADB+QuickBI提供的数据仓库方案通过分时弹性能力和实时业务展现能力。
TPC-H提供测试用数据模型和测试数 据,MySQL提供客户端连接 PolarDB进行操作。cd/root/2.18.0_rc2/dbgen/mysql-h-u test001-p PolarDB URL在页面获取:u 步骤2 登录数据库并执行语句 use tpch;source dss.ddl 文档版本:20210120 25 在线教育流量洪峰最佳实践 主数据库大流量方案 在数据库页面可以看到表已经创建。步骤3 ...
云速搭部署ADB应用最佳实践

本实践通过云速搭实现一个云原生数据仓库AnalyticDB MySQL版的产品实例。
已开通以下服务:ᅳ 专有网络 VPC ᅳ 云速搭 CADT ᅳ 云原生数据仓库 ADB 文档版本:20211115 2 云速搭部署ADB应用 产品介绍 产品介绍 云速搭 CADT:是一款为上云应用提供自助式云架构管理的产品,显著地降低应 用云上管理的难度和时间成本。本产品提供丰富的预制应用架构模板,同时也支 持自助拖拽方式定义应用云上架构;...
- 产品推荐
- 这些文档可能帮助您