FastASR+FFmpeg(音视频开发+语音识别)(二)
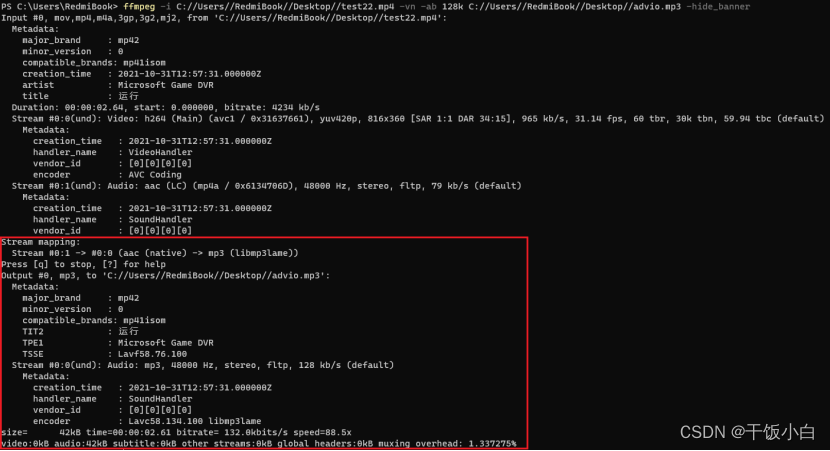
二、视频中提取音频 1.FFmpeg 通过命令行ffmpeg -i 视频文件路径 -vn 音频文件全路径 -hide_banner参数说明:-vn 从视频中提取音频-ab 指定编码比特率(一些常见的比特率 96k、128k、192k、256k、320k)-ar 采样...
FastASR+FFmpeg(音视频开发+语音识别)(一)
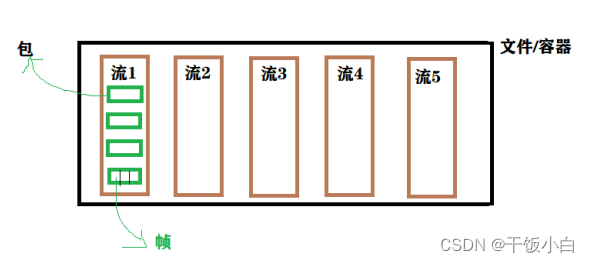
想要更好的做一件事情,不仅仅需要知道如何使用,还应该知道一些基础的概念。一、音视频处理基本梳理 1.多媒体文件的理解 &n...


HarmonyOS学习路之开发篇—AI功能开发(语音识别)
语音识别概述语音识别功能提供面向移动终端的语音识别能力。它基于华为智慧引擎(HUAWEI HiAI Engine)中的语音识别引擎,向开发者提供人工智能应用层API。该技术可以将语音文件、实时语音数据流转换为汉字序列,准确率达到90%以上(本地识别95%)。基本概念语音识别技术,也称为自动语音识别&...
Hololens Unity 开发之 语音识别
一、概述HoloToolKit Unity 包提供了三种 语音输入的方式 :· Phrase Recognition 短语识别* KeywordRecognizer 单一关键词识别* GrammarRecognizer 语法识别· · Dictation Recogni...
Android特色开发之语音识别
本文节选于机械工业出版社推出的《Android应用开发揭秘》一书,作者为杨丰盛。本书内容全面,详细讲解了Android框架、Android组件、用户界面开发、游戏开发、数据存储、多媒体开发和网络开发等基础知识,而且还深入阐述了传感器、语音识别、桌面组件开发、Android游戏引擎设计、Android...
微软开发的语音识别技术超越IBM沃森 出错率仅6.3%
微软的一个研究团队在开发语音识别技术方面取得了新成果,在语音识别准确率上面超过了IBM的超级电脑沃森。微软将其语音识别技术的出错率降到了6.3%,打破了沃森之前保持的6.9%的出错率纪录。 微软的目标是让计算机能够理解语言以及人的意图,从而帮助它改进Cortana、Skype Translator和...
微信快速开发框架(八)-- V2.3--增加语音识别及网页获取用户信息,代码已更新至Github
不知不觉,版本以每周更新一次的脚步进行着,接下来应该是重构我的代码及框架的结构,有朋友反应代码有点乱,确实如此,当时写的时候只是按照订阅号来写的,后来才慢慢增加到支持API接口。目前还在开发第三方微信平台,旨在使用户能够无需自己开发就能简易搭建微信平台。 更新内容 1、增加支持语音识别 2、增加“网...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子


