最火热的分布式流式处理引擎-Flink入门介绍
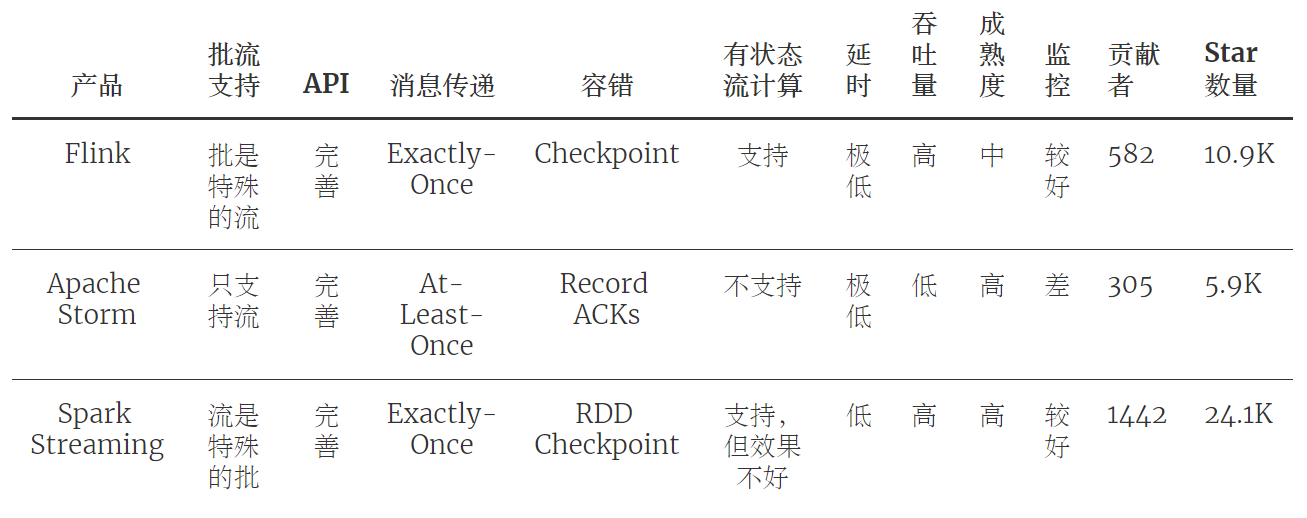
一、什么是Flink?Flink是目前流行的分布式流式处理引擎,是Apache的顶级项目。Flink支持高吞吐、低延迟、高性能、Exactly-Once语义等特性,同时其基于"批是特殊的流"的理念,既实现了流式处理计算,又实现了批处理计算,达到了真正意义上的批流统一。Flink具备极高的处理能力&a...
分布式计算引擎 Flink/Spark on k8s 的实现对比以及实践
以 Flink 和 Spark 为代表的分布式流批计算框架的下层资源管理平台逐渐从 Hadoop 生态的 YARN 转向 Kubernetes 生态的 k8s 原生 scheduler 以及周边资源调度器,比如 Volcano 和 Yunikorn 等。这篇文章简单比较一下两种计算框架在 Nativ...

如果想搭建一套分布式的训练集群,除了kafka、TensorFlow、hadoop、flink、zo
如果想搭建一套分布式的训练集群,除了kafka、TensorFlow、hadoop、flink、zookeeper,还需要搭建什么吗? 本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。 点击这里欢迎加入感兴趣的技术领域群。
用于保持访问配置数据<10 GB的最佳分布式缓存,并从Flink流应用程序访问每条记录?
我的数据不会超过10 GB,我需要将它放在分布式缓存中并为每条记录访问它以便从我的Flink流应用程序进行验证。哪一个最适合这个用例?我在hazelcast和redis之间感到困惑。
分布式Snapshot和Flink Checkpointing简介
阿里巴巴实时计算部-昆仑 最近在学习Flink的Fault Tolerance,了解到Flink在Chandy Lamport Algorithm的基础上扩展实现了一套分布式Checkpointing机制,这个机制在论文"Lightweight Asynchronous Snapshots for ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践
更多




实时计算 Flink版您可能感兴趣
- 实时计算 Flink版数据
- 实时计算 Flink版web
- 实时计算 Flink版界面
- 实时计算 Flink版配置
- 实时计算 Flink版同步
- 实时计算 Flink版oracle
- 实时计算 Flink版对接
- 实时计算 Flink版binlog
- 实时计算 Flink版并行度
- 实时计算 Flink版日志
- 实时计算 Flink版报错
- 实时计算 Flink版任务
- 实时计算 Flink版版本
- 实时计算 Flink版表
- 实时计算 Flink版设置
- 实时计算 Flink版 CDC
- 实时计算 Flink版模式
- 实时计算 Flink版运行
- 实时计算 Flink版数据库
- 实时计算 Flink版连接
- 实时计算 Flink版库
- 实时计算 Flink版作业
- 实时计算 Flink版全量
- 实时计算 Flink版参数
- 实时计算 Flink版集群