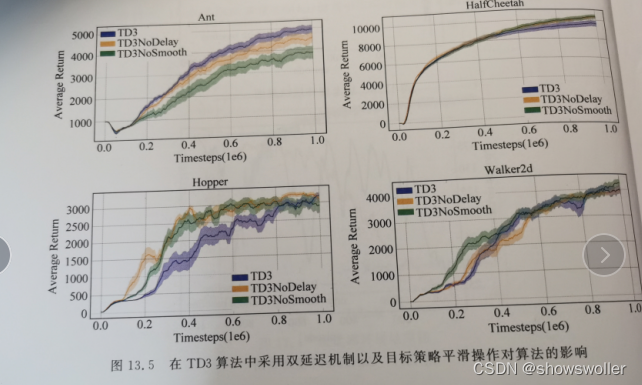
【PyTorch深度强化学习】TD3算法(双延迟-确定策略梯度算法)的讲解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言~~~一、双延迟-确定策略梯度算法在DDPG算法基础上,TD3算法的主要目的在于解决AC框架中,由函数逼近引入的偏差和方差问题。一方面,由于方差会引起过高估计,为解决过高估计问题,TD3将截断式双Q学习(clipped Double Q-Learning)应用于AC...

【PyTorch深度强化学习】DDPG算法的讲解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言留下QQ~~~一、DDPG背景及简介 在动作离散的强化学习任务中,通常可以遍历所有的动作来计算动作值函数q(s,a)q(s,a),从而得到最优动作值函数q∗(s,a)q∗(s,a) 。但在大规模连续动作空间中,遍历所有动作是不现实,且计算代价过大。针对解决连续动作...
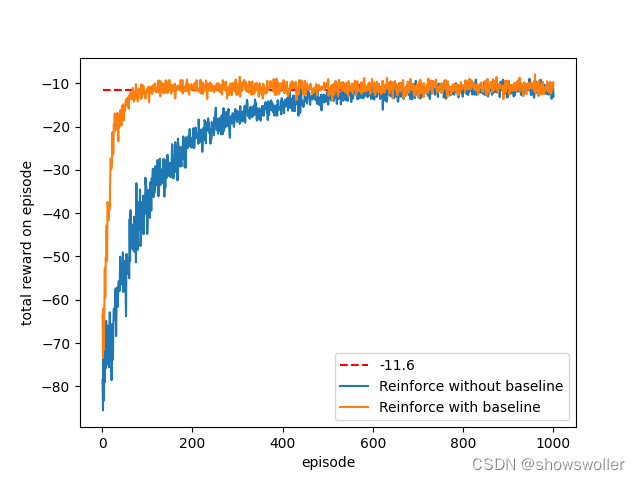
【PyTorch深度强化学习】带基线的蒙特卡洛策略梯度法(REINFOECE)在短走廊和CartPole环境下的实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言留下QQ~~~一、带基线的REINFORCEREINFORCE的优势在于只需要很小的更新步长就能收敛到局部最优,并保证了每次更新都是有利的,但是假设每个动作的奖赏均为正,则每个动作出现的概率将不断提高,这一现象会严重降低学习速率,并增大梯度方差根据这一思想,我们构建...
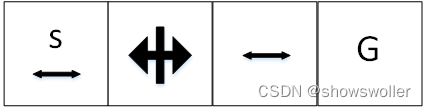
PyTorch深度强化学习中蒙特卡洛策略梯度法在短走廊环境(CartPole-v0)中的实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留下QQ~~~一、策略梯度法策略梯度法(PG)利用策略函数来选择动作,同时使用值函数来辅助策略函数参数的更新,根据策略类型的不同,可以分为随机策略梯度和确定性策略梯度策略梯度法与值函数逼近法相比优点如下1:平滑收敛在学习过程中,PG法每次更新策略函数,权重参数都会朝着最...
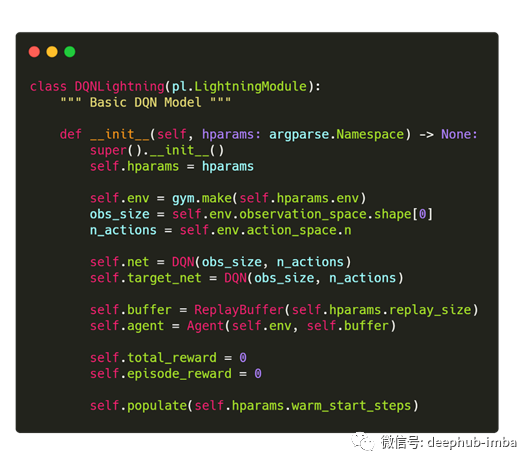
使用PyTorch Lightning构建轻量化强化学习DQN(附完整源码)(二)
智能体智能体类将处理与环境的交互。智能体类主要有三种方法:get_action:使用传递的ε值,智能体决定是使用随机操作,还是从网络输出中执行Q值最高的操作。play_step:在这里,智能体通过从get_action中选择的操作在环境中执行一个步骤。从环境中获得反馈后,经验将存储在重播缓冲区中。如...
使用PyTorch Lightning构建轻量化强化学习DQN(附完整源码)(一)
什么是lighting?Lightning是一个最近发布的Pythorch库,它可以清晰地抽象和自动化ML模型所附带的所有日常样板代码,允许您专注于实际的ML部分(这些也往往是最有趣的部分)。除了自动化样板代码外,Lightning还可以作为一种样式指南,用于构建干净且可复制的ML系统。这非常吸引人...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。