
Uber基于Apache Hudi增量 ETL 构建大规模数据湖
Uber 的全球数据仓库团队使用统一的、 PB 级、集中建模的数据湖使所有 Uber 的数据民主化。数据湖由使用维度数据建模技术[1]开发的基础事实、维度和聚合表组成,工程师和数据科学家可以自助方式访问这些表,为 Uber 的数据工程、数据科学、机器学习和报告提供支持。因此,计算这些表的 ETL(提...
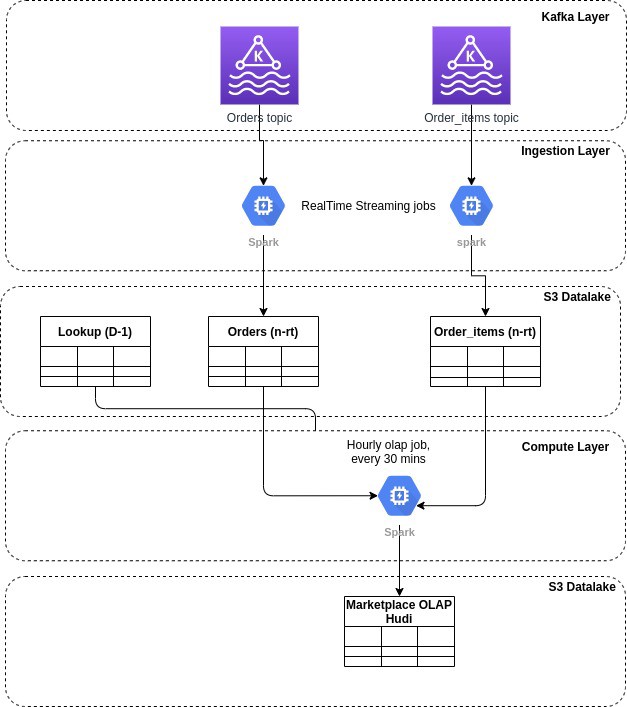
基于 Apache Hudi 构建增量和无限回放事件流的 OLAP 平台
1. 摘要在本博客中,我们将讨论在构建流数据平台时如何利用 Hudi 的两个最令人难以置信的能力。增量消费--每 30 分钟处理一次数据,并在我们的组织内构建每小时级别的OLAP平台事件流的无限回放--利用 Hudi 的提交时间线在超级便宜的云对象存储(如 AWS S3)中存储 10 天的事件流(想...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子







Apache hudi相关内容
- Apache hudi s3
- Apache hudi架构
- Apache hudi最佳实践
- Apache hudi管道
- Apache hudi构建管道
- Apache hudi cdc
- Apache hudi分析
- Apache hudi存储
- Apache hudi索引分析
- Apache hudi索引
- hudi Apache索引分析
- hudi Apache
- Apache hudi deltalake
- Apache hudi示例
- 数据湖Apache hudi
- Apache hudi zeppelin
- Apache hudi集成
- Apache hudi应用场景
- 实战Apache hudi
- 实战datadog监控Apache hudi
- Apache hudi构建数据湖
- Apache hudi数据湖
- Apache hudi事务
- Apache hudi大规模数据湖
- Apache hudi迁移机制
- Apache hudi异步部署
- Apache hudi异步compaction
- Apache hudi异步
- Apache hudi amazon emr
- Apache hudi运行
- Apache hudi功能
- 技术Apache hudi
- 查询Apache hudi
- Apache hudi方案
- Apache hudi构建lakehouse
- Apache hudi lakehouse
- Apache hudi数据湖实践
- Apache hudi实时数据湖
- Apache hudi构建实时数据湖
- Apache pulsar hudi构建lakehouse方案
- Apache hudi清理
- 数据Apache hudi
- Apache hudi类型
- Apache hudi平台
- Apache hudi构建平台
- Apache hudi构建平台实践
- Apache hudi数据湖平台
- Apache hudi流批一体实践
- Apache hudi流批一体架构
Apache更多hudi相关
- Apache hudi概念
- Apache hudi实战
- Apache hudi核心概念
- Apache hudi模式
- Apache hudi机制
- Apache hudi aws
- Apache hudi湖仓一体
- Apache hudi流批一体
- Apache hudi数据集
- Apache hudi流式
- Apache hudi payload
- Apache hudi湖仓
- Apache hudi特性
- Apache hudi pulsar
- Apache hudi分析数据湖
- Apache hudi presto
- Apache hudi clustering
- Apache hudi构建开放
- Apache hudi技术
- Apache hudi流式数据湖
- Apache hudi高达
- Apache hudi s3构建
- Apache hudi性能
- Apache hudi schema
- Apache hudi查询
- Apache hudi架构实践
- Apache hudi核心概念file
- Apache hudi timeline
- 超硬核Apache hudi机制
Apache您可能感兴趣
- Apache required
- Apache more
- Apache options
- Apache connect
- Apache实时计算
- Apache报错
- Apache操作
- Apache kafka
- Apache flink
- Apache模型
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache微服务
- Apache从入门到精通
- Apache doris
- Apache mysql
- Apache访问
- Apache日志