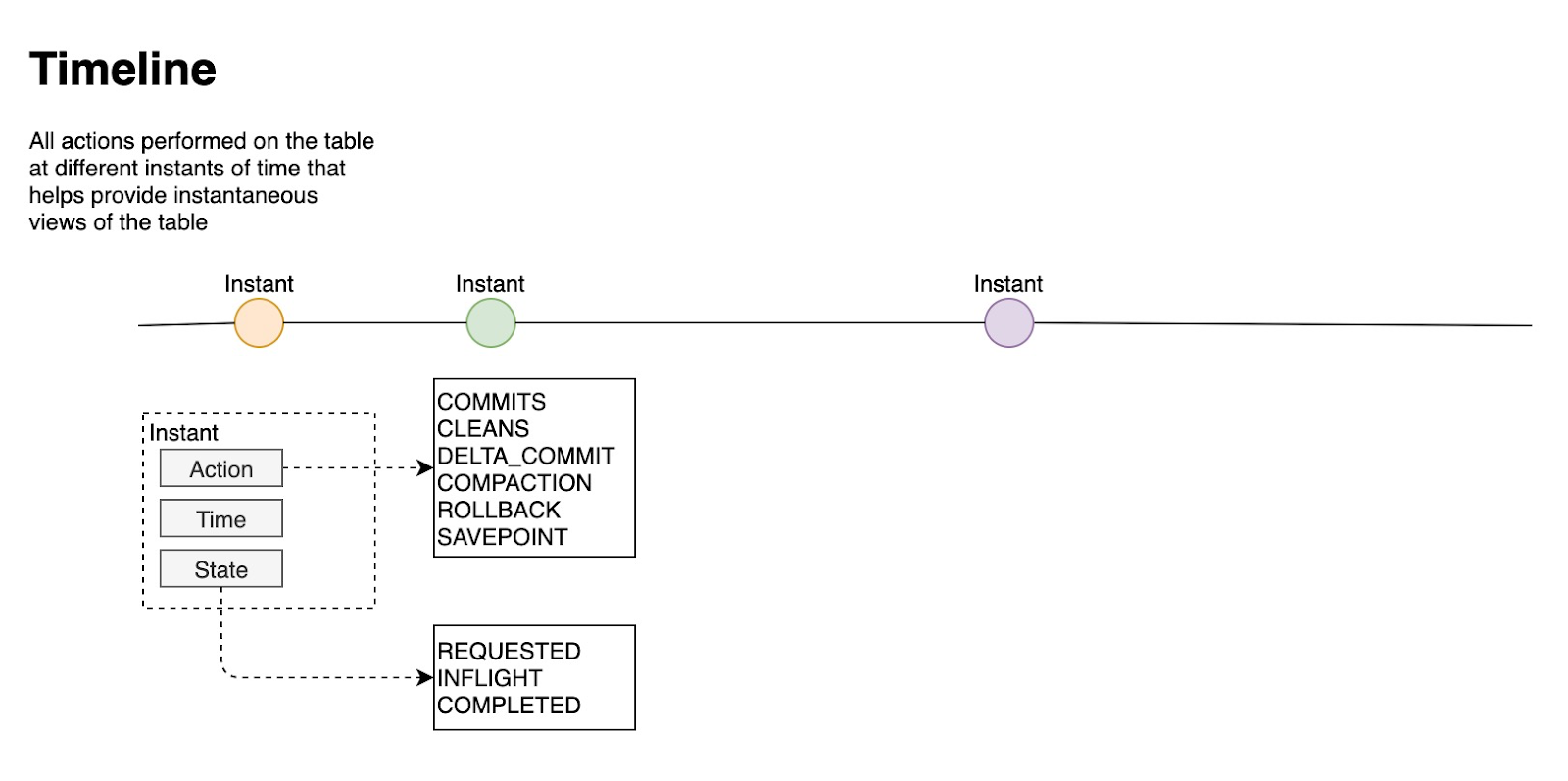
Apache Hudi核心概念一网打尽
1. 场景近实时写入减少碎片化工具的使用CDC 增量导入 RDBMS 数据限制小文件的大小和数量近实时分析相对于秒级存储 (Druid, OpenTSDB) ,节省资源提供分钟级别时效性,支撑更高效的查询Hudi 作为 lib,非常轻量增量 pipeline区分 arrivetime 和 event...
Apache中流计算中的状态有哪两种计算?其概念又是什么?
Apache中流计算中的状态有哪两种计算?其概念又是什么?

Apache Flink 基本概念是什么?
Apache Flink 基本概念是什么?

Apache Flink 零基础入门(一):基础概念解析
作者:陈守元、戴资力 一、Apache Flink 的定义、架构及原理 Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态或无状态的计算,能够部署在各种集群环境,对各种规模大小的数据进行快速计算。 1. Flink Application 了解 Flink 应...
Apache Storm 官方文档 —— 基础概念
Storm 系统中包含以下几个基本概念: 拓扑(Topologies) 流(Streams) 数据源(Spouts) 数据流处理组件(Bolts) 数据流分组(Stream groupings) 可靠性(Reliability) 任务(Tasks) 工作进程(Workers) 译者注:由于 Stor...
Apache Storm 官方文档 —— 理解 Storm 拓扑的并行度(parallelism)概念
一个运行中的拓扑是由什么构成的:工作进程(worker processes),执行器(executors)和任务(tasks) 在一个 Storm 集群中,Storm 主要通过以下三个部件来运行拓扑: 工作进程(worker processes) 执行器(executors) 任务(tasks) 下...
Apache Kylin权威指南2.1 核心概念
第2章 快?速?入?门 第1章介绍了Kylin的概况,以及与其他SQL on Hadoop技术的比较,相信读者对Kylin已经有了一个整体的认识。本章将详细介绍Kylin的一些核心概念,然后带领读者逐步定义数据模型,创建Cube,并通过SQL来查询Cube,以帮助读者对Kylin有更为直观的了解。 ...
Apache Kylin的核心概念
1、表(table):This is definition of hive tables as source of cubes,在build cube 之前,必须同步在 kylin中。2、模型(model):模型描述了一个星型模式的数据结构,它定义了一个事实表(Fact Table)和多个查找表(L...
Apache Beam的基本概念
Apache Beam的基本概念 在使用Apache Beam构建数据处理程序,首先需要使用Beam SDK中的类创建一个Driver程序,在Driver程序中创建一个满足我们数据处理需求的Pipeline,Pipeline中包括输入(Inputs)、转换(Transformations)、输出...
Apache Storm 官方文档 —— 理解 Storm 拓扑的并行度(parallelism)概念
原文链接 译者:魏勇 一个运行中的拓扑是由什么构成的:工作进程(worker processes),执行器(executors)和任务(tasks) 在一个 Storm 集群中,Storm 主要通过以下三个部件来运行拓扑: 工作进程(worker processes) 执行...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子







Apache您可能感兴趣
- Apache开源
- Apache架构
- Apache数据仓库
- Apache实践
- Apache doris
- Apache centos7
- Apache安装
- Apache编译
- Apache库
- Apache数据
- Apache flink
- Apache配置
- Apache rocketmq
- Apache php
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache报错
- Apache服务
- Apache微服务
- Apache从入门到精通
- Apache hudi
- Apache mysql
- Apache访问
- Apache日志