爬虫实战-Python爬取百度当天热搜内容
学习建议 本文仅用于学习使用,不做他用;本文仅获取页面的内容,作为学习和对Python知识的了解,不会对页面或原始数据造成压力;请规范文明使用本文内容,请仅作为个人学习参考使用。本文主要学习了Python爬虫的基础,及常用的几个模块或库的使用,比如BeautifulSoup、reque...
python网络爬虫,爬百度的示例
以下是一个Python网络爬虫示例,使用BeautifulSoup库来爬取百度搜索结果页面的标题、链接和描述信息: import requests from bs4 import BeautifulSoup url = 'https://www.baidu.com/s?wd=%E6%96%B0%E9...

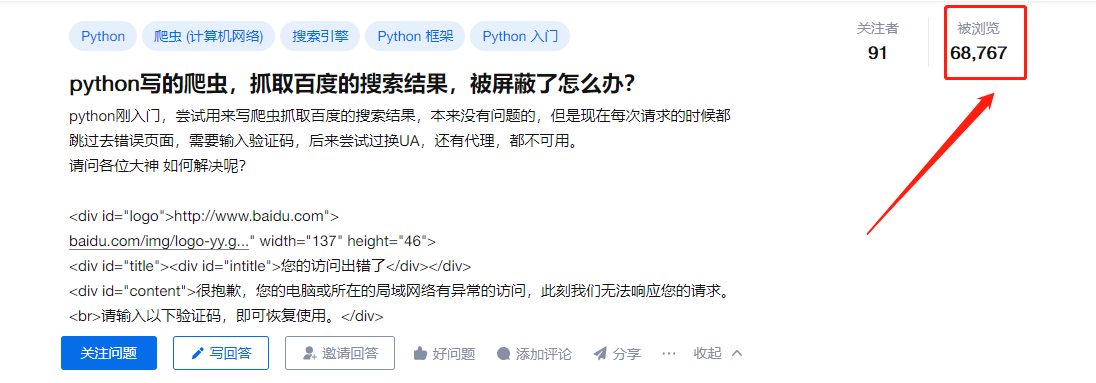
python写的爬虫,抓取百度的搜索结果,被屏蔽了怎么办?
某乎上有个热门话题,引起了很大的讨论。这个问题通常是由于频繁的请求导致百度的反爬虫机制触发了验证码的保护机制。解决办法无非是那几套流程走一遍。1.增加请求的时间间隔通过在每个请求之间增加一些时间间隔,可以降低请求频率,从而避免被反爬虫机制检测到。例如,可以使用time模块中的sleep函数在每个请求...
百度爬虫不主动来原因帮忙找下。现在是有收录了。但是几乎没来。www.20200824.com
百度爬虫不主动来原因帮忙找下。现在是有收录了。但是几乎没来。www.20200824.com
百度蜘蛛ip段大全分析爬虫式
百度蜘蛛ip段大全分析是123开头IP和220开头IP。前面123开头是百度爬虫先进来访问网站,如果对于网站收录和排名有用,首先要这个网站文章对用户有用用是必须原创文章,文章内容字数500字以上2000字以内为好。符合这些要求了接下为220开头百度收录IP段就来了,整个过程就是这样百度蜘蛛,在创建外...
Python爬虫:调用百度翻译接口实现中英翻译功能
百度翻译地址:https://fanyi.baidu.com/上篇文章我使用了爬虫获取了有道翻译的接口,这次通过正规渠道获取翻译结果百度翻译开放平台:http://api.fanyi.baidu.com/api/trans/product/index1、按照提示注册账号,获取 APP ID 和 密钥...
Python爬虫:利用百度短网址缩短url
写爬虫程序的时候,会遇到目标网址太长,存入数据库存入不了的情况,这时,我们可以通过百度短网址服务将网址缩短之后再存入百度短网址:http://dwz.cn/百度短网址接口文档:http://dwz.cn/#/apidoc以下是python代码# -*- coding: utf-8 -*- # @Fi...
请问百度爬虫不主动来原因做茶叶www.20200824.com
备案到现在有20多天了,3天前才从百度站长那里成功添加备案号,之前没有添加成功,现在问题出来了,麻烦问下,请问百度爬虫不主动来原因做茶叶https://www.20200824.com
百度爬虫爬一次时间计算法则
百度爬虫是指未被百度收录之前会有原程序进行对该网站友好程度和文章原创性分析。百度爬虫多久爬一次这个是要按每次更新算法来总结,按常识来分析的话百度爬虫爬一次是2秒-10秒。网站建设者能从百度爬虫来访停留时间获取网站优化程度和友好程度,也就能更好去改善之前没有发现一些错误或不利于网站收录和网站排名技巧。...
阿里服务器 网站不收录查询百度蜘蛛爬虫发起抓取,httpcode返回码是5XX求解
新站使用的是阿里服务器+宝塔面板+程序WP+程序中无控制蜘蛛插件,新站上线好久了,仅收录了一个首页。 百思不得其解,通过百度站长查询域名www.ymcopy.com,所返回的值爬虫发起抓取,httpcode返回码是5XX,我就不明白了。 按理说wordperss程序不至于这样菜的吧。服务器防火墙我也...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


