[帮助文档] 如何创建LIST DEFAULT HASH混合分区表
本文介绍了创建和修改LIST DEFAULT HASH分区表的方法。
[帮助文档] 如何创建HASH分区表
本文档介绍了创建HASH分区表的方法。

[帮助文档] 如何使用COALESCEPARTITION命令减少基于HASH和KEY分区的分区数
本文档介绍了减少基于HASH和KEY分区的分区数和对应分区的所有子分区,并将数据合并到其他分区和子分区中的方法。
[帮助文档] 什么是LISTDEFAULTHASH分区
本文主要介绍了选择LIST DEFAULT HASH分区的场景。
[帮助文档] 什么是HASH分区
对于分布规则不明显的数据,并没有明显的范围查找等特征,可以使用HASH分区,将数据分区列的值按照HASH算法打散到不同的分区上,将数据随机分布到各个分区。
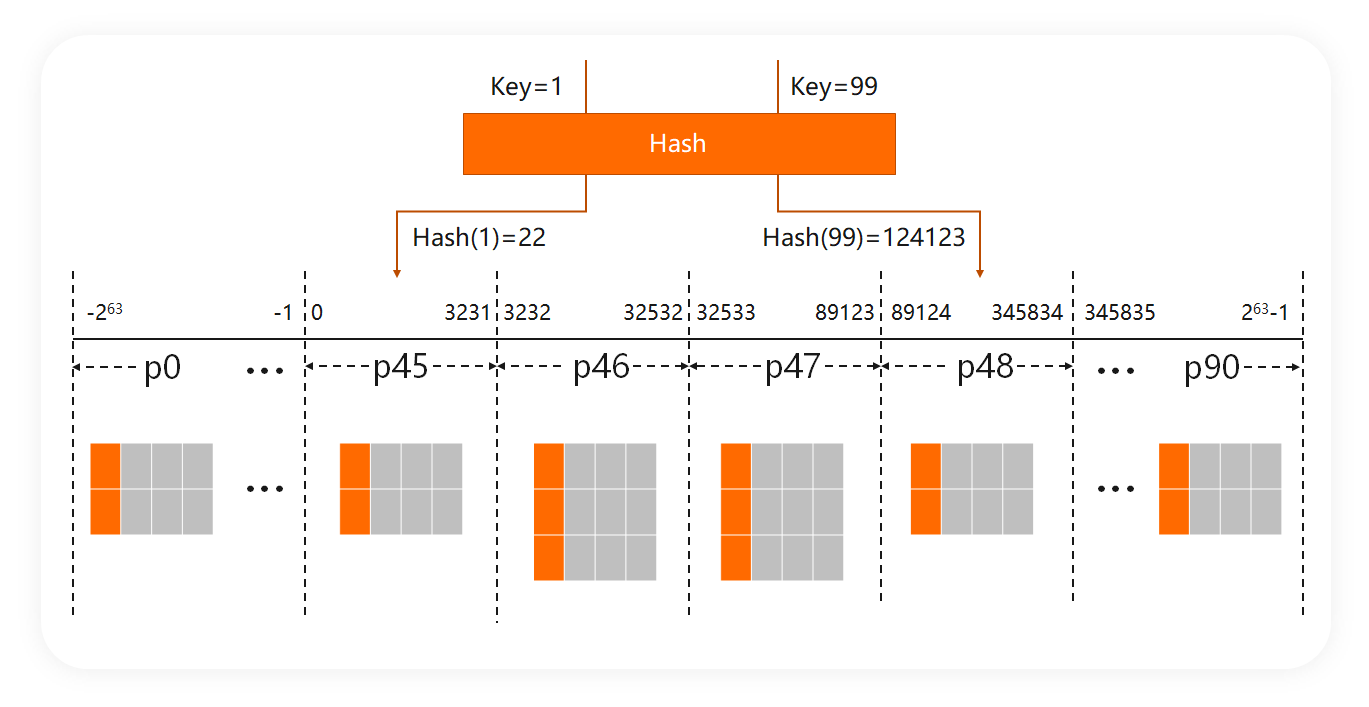
PolarDB-X 数据分布解读 :Hash vs Range
PolarDB-X同时支持Hash与Range的分区算法,但是默认情况下,我们选择了使用Hash算法。像YugabyteDB默认也是Hash的分区算法,而TiDB、CockroachDB是Range分区算法。那么,Hash与Range对于数据库,到底意味着什么?作为应用,又该如何选择?PolarDB...
PolarDB-X 1.0-SQL 手册-拆分函数使用说明-HASH
本文将介绍HASH函数使用方式。注意事项HASH函数的算法是简单取模,要求拆分列的值的自身分布均衡才能保证哈希均衡。使用限制拆分键的数据类型必须是整数类型或字符串类型。路由方式若分库和分表使用不同拆分键进行HASH时,则根据分库键的键值直接按分库数取余。如果键值是字符串,则字符串会先被换算成哈希值再...

PostgreSQL 并行计算解说 之19 - parallel hash join
标签 PostgreSQL , cpu 并行 , smp 并行 , 并行计算 , gpu 并行 , 并行过程支持 背景 PostgreSQL 11 优化器已经支持了非常多场合的并行。简单估计,已支持27余种场景的并行计算。 parallel seq scan ...

PostgreSQL 分区表如何支持多列唯一约束 - 枚举、hash哈希 分区, 多列唯一, insert into on conflict, update, upsert, merge insert
标签 PostgreSQL , 分区表 , native partition , 唯一 , 非分区键唯一 , 组合唯一 , insert into on conflict , upsert , merge insert 背景 PG 11开始支持HASH分区,10的分区如果要支持hash分区,可以通过...
PostgreSQL 11 新特性解读:支持并行哈希连接(Parallel Hash Joins)"
PostgreSQL 11 版本在并行方面得到增强,例如支持并行创建索引(Parallel Index Build)、并行哈希连接(Parallel Hash Join)、并行 CREATE TABLE .. AS等,上篇博客介绍了并行创建索引,本文介绍并行 Hash Join。 测试环境准备 创建...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








云原生数据库 PolarDB您可能感兴趣
- 云原生数据库 PolarDB参数
- 云原生数据库 PolarDB数据库
- 云原生数据库 PolarDB升级
- 云原生数据库 PolarDB迁移
- 云原生数据库 PolarDB实例
- 云原生数据库 PolarDB扩容
- 云原生数据库 PolarDB配置
- 云原生数据库 PolarDB sql
- 云原生数据库 PolarDB存储
- 云原生数据库 PolarDB规格
- 云原生数据库 PolarDB MySQL
- 云原生数据库 PolarDB rds
- 云原生数据库 PolarDB同步
- 云原生数据库 PolarDB阿里云
- 云原生数据库 PolarDB数据
- 云原生数据库 PolarDB手册
- 云原生数据库 PolarDB analyticdb
- 云原生数据库 PolarDB查询
- 云原生数据库 PolarDB PolarDB
- 云原生数据库 PolarDB版本
- 云原生数据库 PolarDB云原生
- 云原生数据库 PolarDB postgresql
- 云原生数据库 PolarDB开源
- 云原生数据库 PolarDB索引
- 云原生数据库 PolarDB库
- 云原生数据库 PolarDB oracle
- 云原生数据库 PolarDB集群