Flink CDC 里怎么设置idea打开一个新的github项目,自动索引文件吗?
Flink CDC 里怎么设置idea打开一个新的github项目,自动索引文件吗?每次打开打的项目,都特别的卡,然后索引30多分钟,能不能设置成 间隔性的,打开某个目录,再索引,实在是太卡了,电脑都要烧冒烟了。

git拉取项目时创建.ssh文件,并形成公钥和私钥,设置到Github上
一 :场景:二: 创建.ssh文件步骤:三: 生成.ssh图片四: 设置ssh 公钥到git上步骤:五: Git的下载: https://pan.baidu.com/s/1nyGu7tzLtMxFTisoVD0EAQ 提取码: abcj

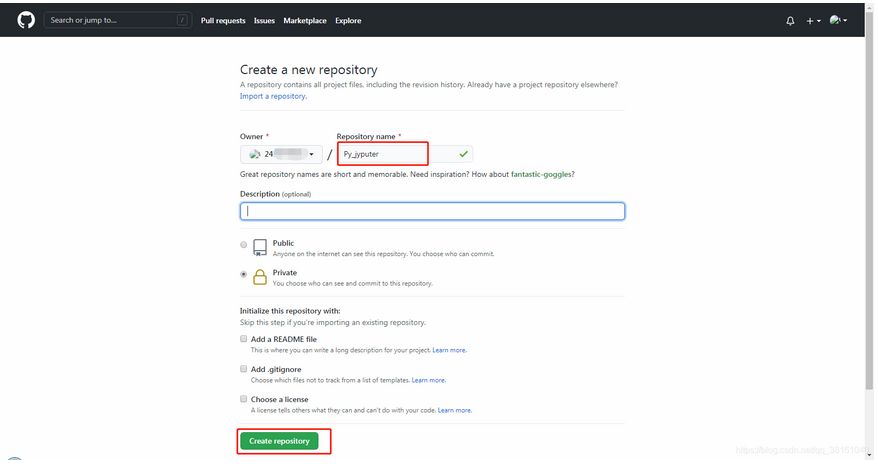
Jyputer 项目工程设置Github同步,本地代码上传Github实例演示
首先在 Github 上创建一个仓库,它将用于存储、同步本地 Jyputer 里的项目。 获取到仓库的 SSH 地址。 下面的文件夹就是我想同步的项目工程。 在当前文件夹下依次使用如下命令: git init 初始化项目。 git add 项目文件夹 添加项目。 git commit -m "说明"...
有一台64GRAM的机器A和一台32G的机器B 都装了PG 11 ,A的参数 share_buffer 设置为 16G,机器B的share_buffer设置为 8G,其它的内存相关的配置参数(work mem 等等) 机器B都是A 的一半,参数设置都是参照的德哥github的文章 pg 参数模板设的。
现在问题是 一套相同的程序连接 A 高峰跑起来时,机器A的内存占用 时 33%, 而程序连接到机器B的PG上,高峰时 内存占用确达到 88%,两台机器的CPU占用水平倒是一样的,。 两条机器的 CPU规格时一样的。那套程序 跑的数据,跑的数据都是一样的,都是往pg里面 多个表 insert/upda...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。






GitHub您可能感兴趣
- GitHub copilot
- GitHub代码管理
- GitHub图床
- GitHub个人博客
- GitHub开源
- GitHub picgo
- GitHub typora
- GitHub函数计算
- GitHub自动部署
- GitHub Actions
- GitHub项目
- Github Git
- GitHub代码
- GitHub Java
- GitHub阿里
- GitHub搭建
- GitHub开源项目
- GitHub下载
- GitHub仓库
- GitHub hexo
- GitHub配置
- GitHub笔记
- GitHub Pages
- GitHub文件
- GitHub博客
- GitHub手册
- GitHub教程
- GitHub gitee
- GitHub上传