[帮助文档] 如何使用SparkStructuredStreaming实时处理Kafka数据
本文介绍如何使用阿里云 Databricks 数据洞察创建的集群去访问外部数据源 E-MapReduce,并运行Spark Structured Streaming作业以消费Kafka数据。
[帮助文档] 如何创建EMRSparkStreaming节点并进行数据开发
EMR Spark Streaming节点用于处理高吞吐量的实时流数据,并具备容错机制,可以帮助您快速恢复出错的数据流。本文为您介绍如何创建EMR Spark Streaming节点并进行数据开发。

[帮助文档] SparkStreamingSQL的STREAM语句
EMR-3.23.0版本开始支持STREAM语法。
Spark Streaming实时流处理项目实战笔记——使用KafkaSInk将Flume收集到的数据输出到Kafka
Flume配置文件a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.bind = hadoop a1.sources.r1.port = 44444 a1.sinks.k1.t...
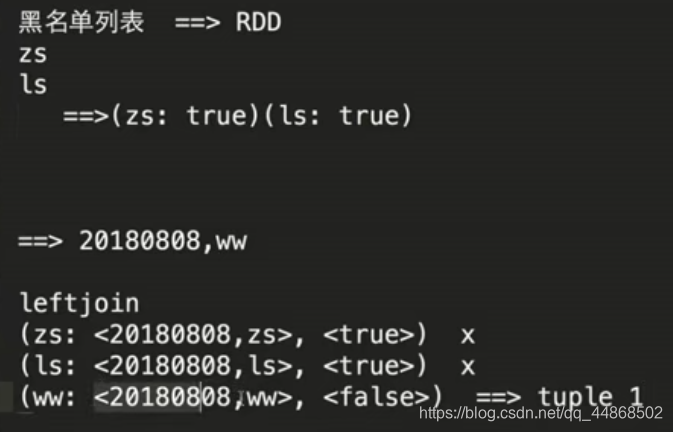
Spark Streaming实时流处理项目实战笔记——实战之黑名单过滤
思路源代码窗口函数 代码实现object Black extends App { import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} val spa...
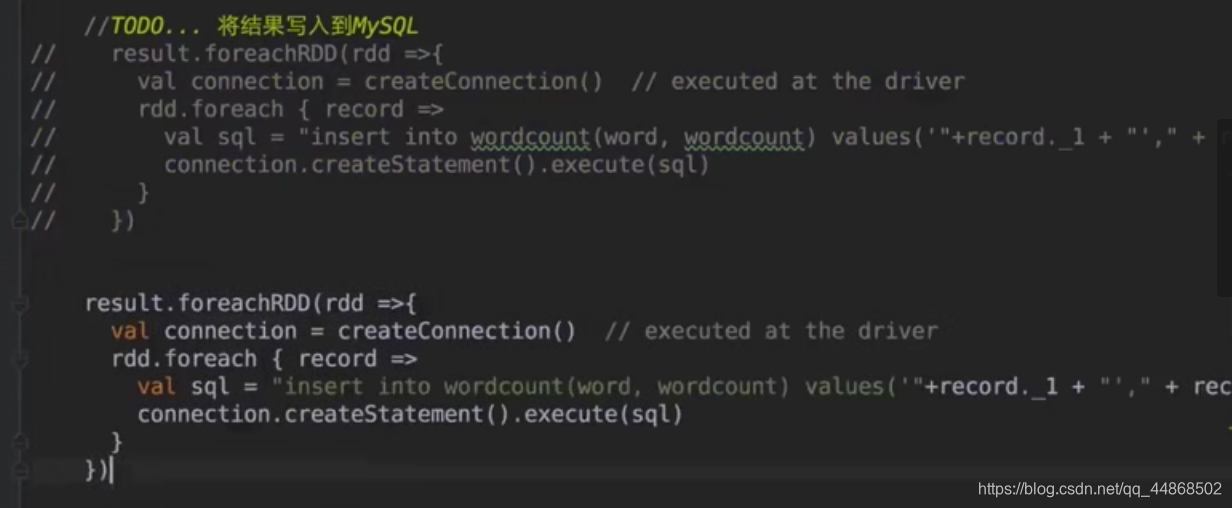
Spark Streaming实时流处理项目实战笔记——将统计结果写入到MySQL数据库中
思路两种方式,一种可优化(foreachRDD后,直接创建连接Mysql),一种在(foreachRDD后通过foreachPartition,通过分区获取)代码实现import java.sql.DriverManager import Spark.UpdateStateByKey....
Spark Streaming实时流处理项目实战笔记——Kafka Consumer Java API编程
1、在控制台创建发送者kafka-console-producer.sh --broker-list hadoop2:9092 --topic zz >hello world2、消费者APIimport java.util.Arrays; import java.util.Properties...
[帮助文档] 如何通过DLAServerlessSpark提交SparkStreaming作业
本文介绍DLA Serverless Spark如何提交Spark Streaming作业以及Spark Streaming作业重试的最佳实践。
[帮助文档] 如何使用DLASparkStreaming访问LogHub
本文介绍了如何使用DLA Spark Streaming访问LogHub。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子





apache sparkstreaming相关内容
- apache spark streaming区别
- flink apache spark streaming
- apache spark Streaming容错性
- apache spark streaming数据源
- apache spark streaming dstream操作
- apache spark streaming操作
- apache spark streaming简介
- apache spark streaming学习笔记
- apache spark structured streaming
- 大数据apache spark streaming
- apache spark streaming实时计算
- apache spark streaming框架
- apache spark streaming应用程序
- apache spark streaming计算
- apache spark全集末尾structured streaming续集
- apache spark streaming实战
- apache spark streaming流处理
- apache spark streaming编程
- apache spark streaming at bing scale
- apache spark Streaming Kafka
- apache spark streaming连接kafka
- 流式计算apache spark streaming
- apache spark streaming应用
- apache spark streaming快速入门
- apache spark streaming算子
- apache spark streaming架构原理
- apache spark streaming分析
- apache spark streaming容错
- apache spark streaming机制
- apache spark streaming checkpoint
- apache spark streaming foreachrdd
- apache spark streaming transform
- apache spark Streaming原理
- apache spark streaming服务
- apache spark Streaming SQL
- apache spark streaming数据统计
- apache spark Streaming如何保证
- apache spark streaming文件典型方法是什么意思
- apache spark streaming文件典型
- apache spark streaming方法
- apache spark streaming文件典型是什么意思
- apache spark streaming小文件
- apache spark streaming文件
- apache spark streaming storm
- kafka apache spark streaming
- noxmobi系统使用流式计算apache spark streaming
- flink相比传统apache spark streaming区别
- apache spark streaming采集
apache spark更多streaming相关
- apache spark streaming作用是什么
- apache spark入门streaming
- apache spark summit eu streaming
- apache spark streaming loghub
- apache spark streaming sql pv uv统计
- apache spark streaming运行
- apache spark streaming receiver
- apache spark streaming kafka stream
- apache spark streaming流计算
- apache spark Streaming例子整理
- apache spark streaming kafka数据
- building apache spark streaming
- apache spark structed streaming
- apache spark Streaming预测股票走势
- apache spark streaming vs
- apache spark streaming步骤
- apache spark streaming系统
- apache spark Streaming框架应用
- apache spark summit east streaming
- apache spark streaming数据清理
- apache spark streaming func
- apache spark使用Streaming SQL统计
- apache spark Streaming DStreams
- apache spark streaming文档
- data apache spark streaming
- apache spark streaming loghub报错
- 日志分析apache spark streaming
- apache spark Streaming概念
- apache spark streaming执行过程
- apache spark学习Streaming
- apache spark streaming实时流处理学习
apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark SQL
- apache spark Apache
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作