[帮助文档] 通过SparkStreaming作业处理Kafka数据
本文介绍在阿里云E-MapReduce创建的包含kafka服务的DataFlow集群中,如何使用Spark Streaming作业从Kafka中实时消费数据。
[帮助文档] 如何使用SparkStructuredStreaming实时处理Kafka数据
本文介绍如何使用阿里云 Databricks 数据洞察创建的集群去访问外部数据源 E-MapReduce,并运行Spark Structured Streaming作业以消费Kafka数据。

大数据Spark Structured Streaming集成 Kafka
1 Kafka 数据消费Apache Kafka 是目前最流行的一个分布式的实时流消息系统,给下游订阅消费系统提供了并行处理和可靠容错机制,现在大公司在流式数据的处理场景,Kafka基本是标配。StructuredStreaming很好的集成Kafka,可以从Kafka拉取消息,然后就可以把流数据看...
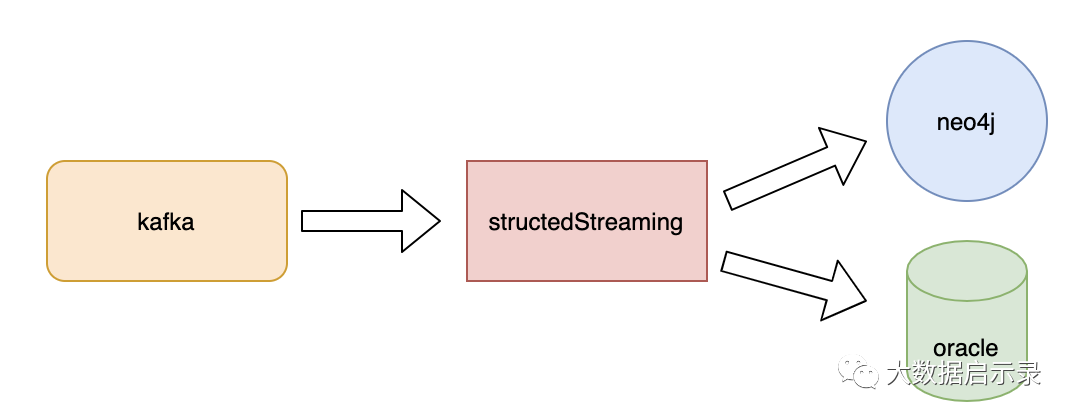
Structured Streaming 读取kafka 写入Neo4j
Output Modes有几种输出模式:Append mode (default) - 这是默认模式,其中只有添加到结果表(因为最后一个触发器)的新行将输出到接收器。这只适用于那些添加到结果表的行永远不会改变的查询。因此,此模式保证每个行只输出一次(假设容错接收器)。例如,只有select...
Spark Structured Streaming获取最后一个Kafka分区的消息
我正在使用Spark Structured Streaming来读取Kafka主题。没有任何分区,Spark Structired Streaming消费者可以读取数据。但是当我向主题添加分区时,客户端仅显示来自最后一个分区的消息。即如果主题中有4个分区,并且I.am推送主题中的1,2,3,4之类的...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







云消息队列 Kafka 版您可能感兴趣
- 云消息队列 Kafka 版事务
- 云消息队列 Kafka 版once
- 云消息队列 Kafka 版语义
- 云消息队列 Kafka 版原理
- 云消息队列 Kafka 版broker
- 云消息队列 Kafka 版consumer
- 云消息队列 Kafka 版应用
- 云消息队列 Kafka 版消息队列
- 云消息队列 Kafka 版数据
- 云消息队列 Kafka 版value
- 云消息队列 Kafka 版flink
- 云消息队列 Kafka 版cdc
- 云消息队列 Kafka 版消费
- 云消息队列 Kafka 版分区
- 云消息队列 Kafka 版集群
- 云消息队列 Kafka 版mysql
- 云消息队列 Kafka 版配置
- 云消息队列 Kafka 版同步
- 云消息队列 Kafka 版报错
- 云消息队列 Kafka 版apache
- 云消息队列 Kafka 版安装
- 云消息队列 Kafka 版topic
- 云消息队列 Kafka 版消息
- 云消息队列 Kafka 版sql
- 云消息队列 Kafka 版入门
- 云消息队列 Kafka 版消费者
- 云消息队列 Kafka 版实战