我们的PolarDB节点内存使用率跑高且高居不下问题,运行中的会话也不多,怎么处理?
我们的PolarDB节点内存使用率跑高且高居不下问题,运行中的会话也不多,能帮看看是应该升级购买内存,还是可以通过优化处理呢?
请教一下,nacos版本1.4.1,集群环境下,节点内存周期性波动,这是什么原因?
请教一下,nacos版本1.4.1,集群环境下,节点内存周期性波动,波动周期大概6分钟左右,这是什么原因,我查看了1.4.1的源码里面也没有发现5分钟左右的定时任务,这一版于什么有关系,distro?求指导一下方向
如下请问EDAS的这个问题怎么解决? 应用id:2b0e6935-47fb-40ec-a11d-7dac320aecc1 集群中的节点内存是足够的,部署跑不起来 可以帮忙看看吗,以前集群下应用发布都是正常的,最近集群下应用部署基本都报错跑不起来,提示节点不可用
在阿里云EDAS中,如果你遇到了应用部署失败并且提示节点不可用的问题,可以尝试以下步骤来排查和解决: 检查集群状态: 在EDAS控制台的“集群管理”页面上,查看你的目标集群的状态。如果它显示为“异常”,可能是由于各种原因导致的,例如网络问题、节点故障等。 检查节点状态: 进入集群详情页...
我EDAS的集群中的节点内存是足够的,为什么我部署应用跑不起来?可以帮忙看看问题吗
我EDAS的集群中的节点内存是足够的,为什么我部署应用跑不起来?可以帮忙看看问题吗
容器服务ACK这个监控看整个集群所有节点的内存使用率不准是为什么呢?
容器服务ACK这个监控看整个集群所有节点的内存使用率不准是为什么呢?
NACOS 2.2.2版本,集群下的某个节点内存100%了,导致整个集群内的所有服务都下线。
NACOS 2.2.2版本,集群下的某个节点内存100%了,导致整个集群内的所有服务都下线。 既然是集群,不应该是某个节点当机了,由其他另外的节点来接管吗?为啥会导致我的所有服务都下线了,只有手动的关闭那台内存100%的节点后;服务才慢慢的恢复回来
Flink我有一个小集群,3个节点,目前4个作业在跑;为啥 都到一个节点上了呀?导致了那个节点的内存
Flink我有一个小集群,3个节点,目前4个作业在跑;为啥 都到一个节点上了呀?导致了那个节点的内存使用超高有没有办法 让作业跑在其他的节点上啊
FinOPS之 节点内存态统计和计算Node-metrics
节点内存态统计和计算 Node-metrics 背景 请查看第一篇:https://kubeservice.cn/2022/11/24/k8s-crane-scheduler-plus/ 实现 Node Metrics是内存态统计计算模块,实现metrics的avg、min、max 等级的数据聚合查...
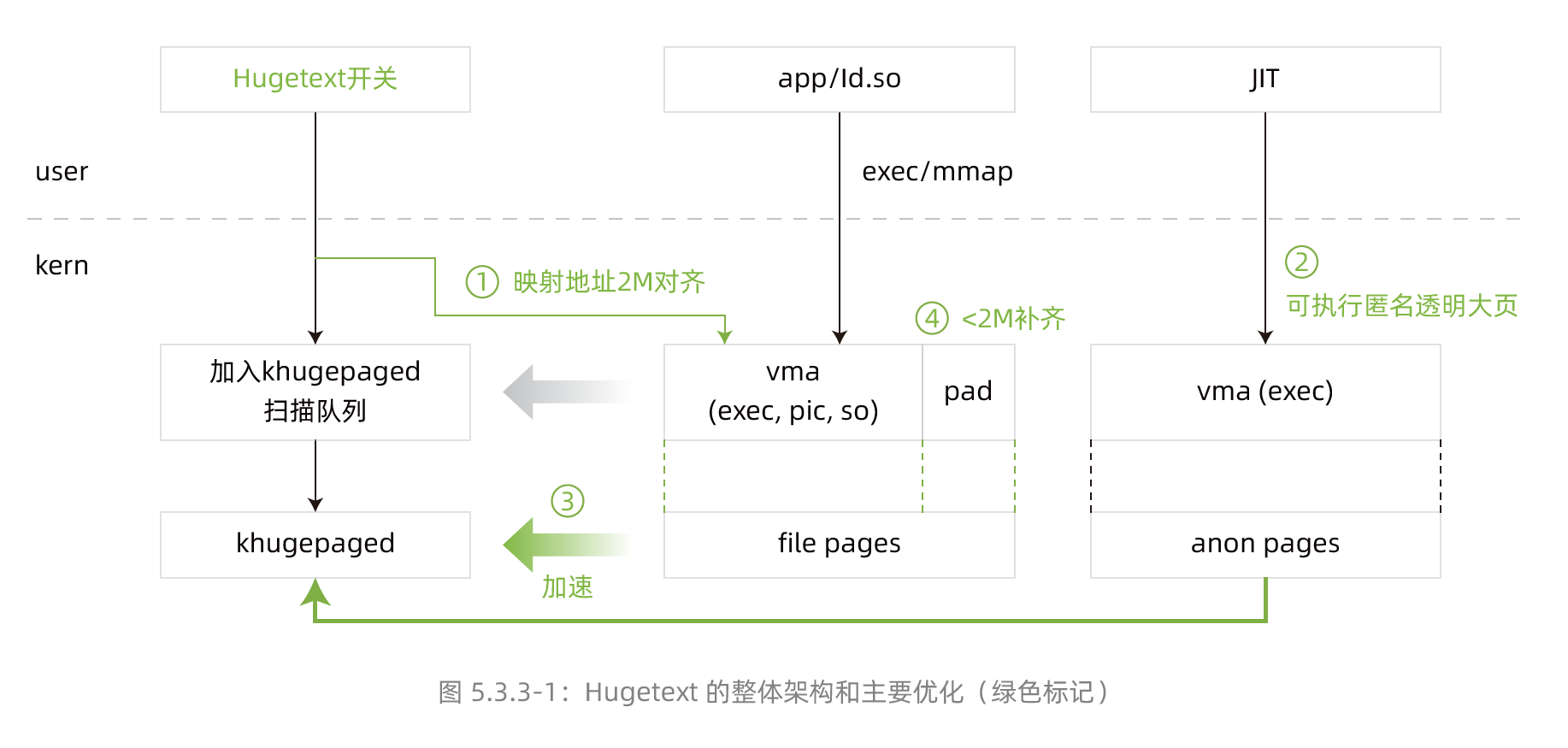
《2022龙蜥社区全景白皮书》——05 原生技术概览——5.3 内核技术——5.3.3 数据库/JAVA等高性能场景中的内存优化
5.3.3 数据库/JAVA等高性能场景中的内存优化 背景概述 在处理器内存缓存层级结构中,iTLB miss性能指标对访存优化至关重要,并且在ARM平台上优化效果更为明显。 在数据库/JAVA 等高性能场景中,iTLB miss可以成为影响性能的主要因素,我们通过实验观察到iTLB miss引入的...
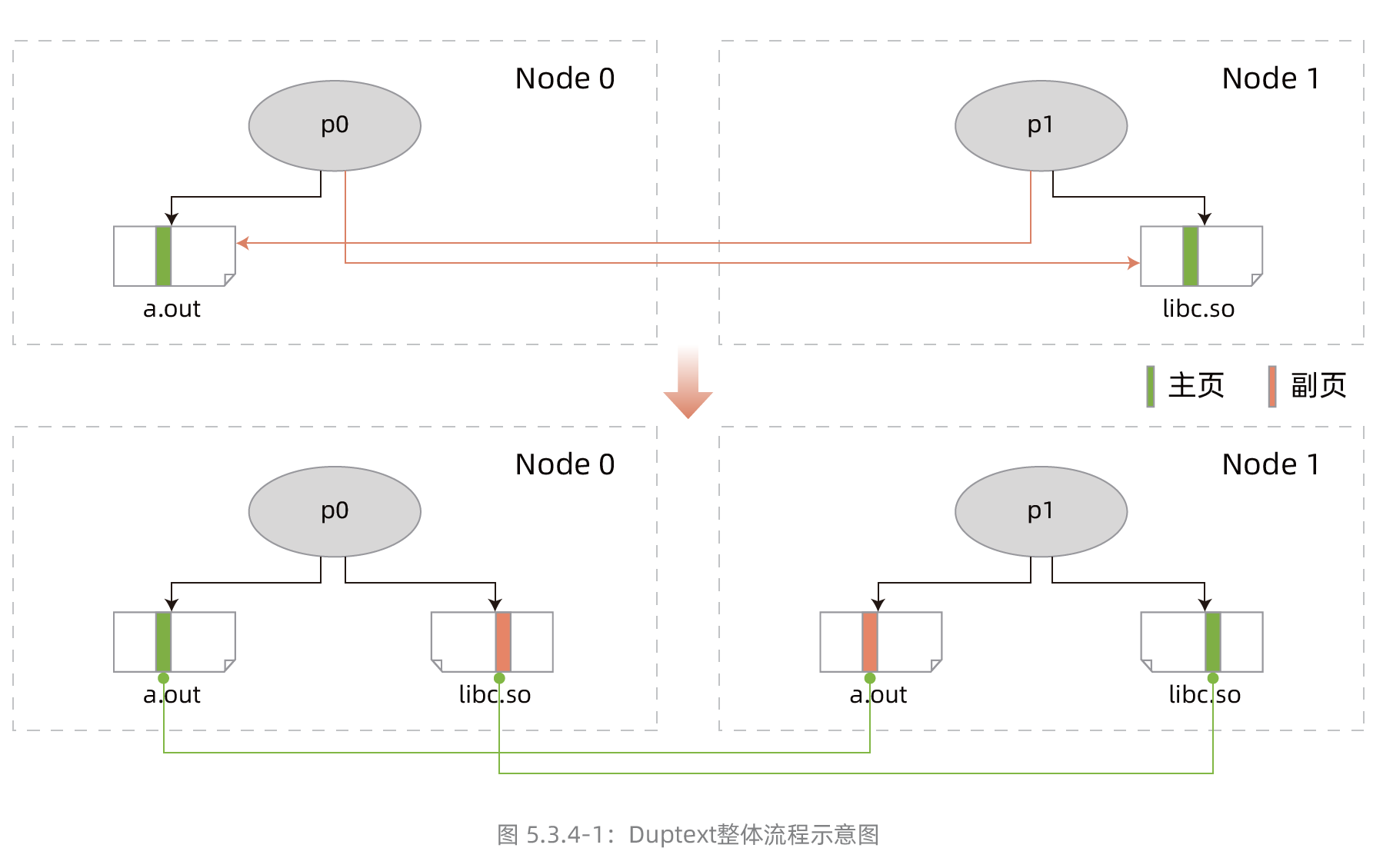
《2022龙蜥社区全景白皮书》——05 原生技术概览——5.3 内核技术——5.3.4 跨处理器节点内存访问优化
5.3.4 跨处理器节点内存访问优化背景概述 在新平台多节点大内存的趋势背景下,打开NUMA是必要的性能手段。随之而来的问题是,跨NUMA访问会引入性能开销。业务一 般配合用户态任务调度,利用绑核等手段规避跨NUMA访问。但文件页跨节点访问不能很好解决。其中,代码段文件页跨节点访问 性能影响比较明显...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐


最佳实践


