[帮助文档] 如何快速构建一个从Kafka到Hologres的数据同步作业
Flink全托管产品提供丰富强大的日志数据实时入仓能力。本文为您介绍如何在Flink全托管控制台上快速构建一个从Kafka到Hologres的数据同步作业。
[帮助文档] 通过SparkStreaming作业处理Kafka数据
本文介绍在阿里云E-MapReduce创建的包含kafka服务的DataFlow集群中,如何使用Spark Streaming作业从Kafka中实时消费数据。

[帮助文档] 通过PyFlink作业处理Kafka数据
本文介绍在阿里云E-MapReduce创建的包含Flink和kafka服务的DataFlow集群中,如何通过PyFlink来处理Kafka中的实时流数据。
Flink中sql作业发送json格式到kafka,可以指定json里的key值吗?
Flink中sql作业发送json格式到kafka,可以指定json里的key值吗?
大佬们请教一个flink 重启生产者的问题,我通过检查点重启作业,但是sink的Kafka ?
大佬们请教一个flink 重启生产者的问题,我通过检查点重启作业,但是sink的Kafka topic换了,就一直报错说生产者尝试使用producer id,但是当前没有给其分配对应的transactional id,这个怎么解决?我通过网上了解到的 producer启动时Kafka会为其分配一个唯...
大佬们请教一个Flink CDC重启生产者的问题,我通过检查点重启作业,但是sink的Kafka ?
大佬们请教一个Flink CDC重启生产者的问题,我通过检查点重启作业,但是sink的Kafka topic换了,就一直报错说生产者尝试使用producer id,但是当前没有给其分配对应的transactional id,这个怎么解决?我通过网上了解到的 producer启动时Kafka会为其分配...
我用运行flink sql作业:flink kafka conector->hudi->hive,对
我用运行flink sql作业:flink kafka conector->hudi->hive,对于同一个topic里的数据,为何多次启动这个flink作业,最后hive count出来的数据条数每次都不一样(少于topic里的实际数据量)?
我想问一下,我flink作业是以upsert-kafka的方式写入数据的,但是我在mysql里面去更
我想问一下,我flink作业是以upsert-kafka的方式写入数据的,但是我在mysql里面去更新了一条数据,发现在kafka出现了两条数据,一条value有值,一条没有值这是什么原因,哪位大佬可以解释一下吗
在flink作业中从kafka数据源获取数据,没有获取到oldest数据怎么办?
在flink作业中从kafka数据源获取数据,将 参数设置为'scan.startup.mode' = 'earliest-offset', 检测flink运行结果时,发现只抽取了kafka中的newest数据,没有获取到oldest数据。 不知道是不是我这里'scan.startup.mode' ...
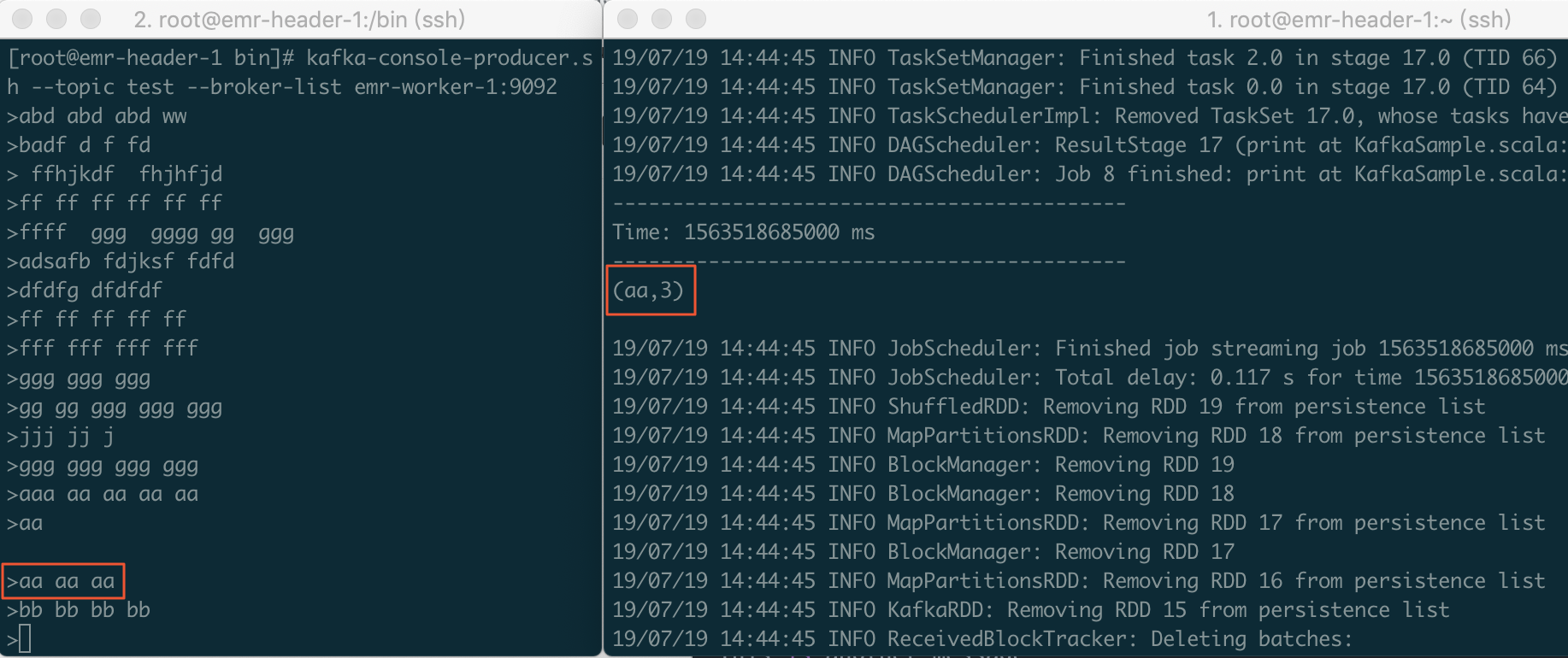
通过Spark Streaming作业处理Kafka数据
本节介绍如何使用阿里云E-MapReduce部署Hadoop集群和Kafka集群,并运行Spark Streaming作业消费Kafka数据。 前提条件 已注册阿里云账号,详情请参见注册云账号。 已开通E-MapReduce服务。 已完成云账号的授权,详情请参见角色授权。 背景信息 在开发过程中,通...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







云消息队列 Kafka 版您可能感兴趣
- 云消息队列 Kafka 版数据
- 云消息队列 Kafka 版python
- 云消息队列 Kafka 版hologres
- 云消息队列 Kafka 版java
- 云消息队列 Kafka 版字段
- 云消息队列 Kafka 版flink
- 云消息队列 Kafka 版mysql
- 云消息队列 Kafka 版功能
- 云消息队列 Kafka 版阿里云
- 云消息队列 Kafka 版组件
- 云消息队列 Kafka 版cdc
- 云消息队列 Kafka 版消费
- 云消息队列 Kafka 版分区
- 云消息队列 Kafka 版集群
- 云消息队列 Kafka 版配置
- 云消息队列 Kafka 版报错
- 云消息队列 Kafka 版同步
- 云消息队列 Kafka 版apache
- 云消息队列 Kafka 版安装
- 云消息队列 Kafka 版消息队列
- 云消息队列 Kafka 版topic
- 云消息队列 Kafka 版消息
- 云消息队列 Kafka 版sql
- 云消息队列 Kafka 版入门
- 云消息队列 Kafka 版消费者
- 云消息队列 Kafka 版实战
- 云消息队列 Kafka 版原理