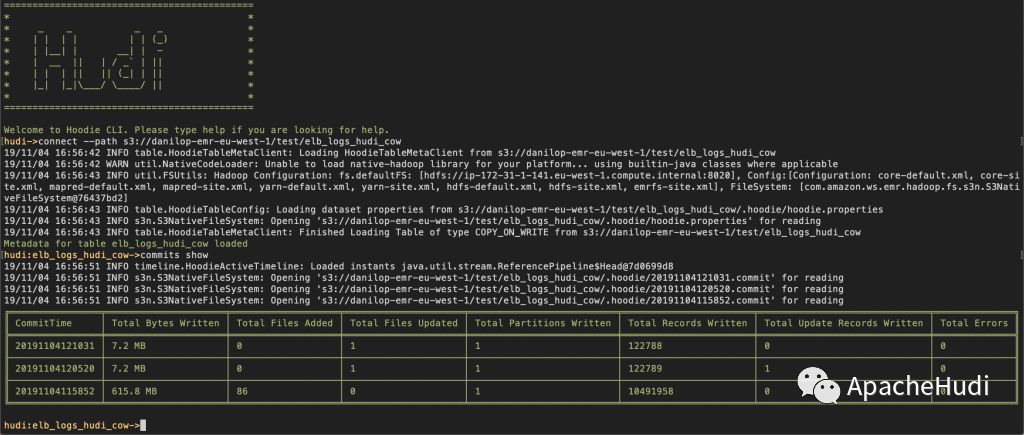
使用Amazon EMR和Apache Hudi在S3上插入,更新,删除数据
将数据存储在Amazon S3中可带来很多好处,包括规模、可靠性、成本效率等方面。最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之类的开源工具来处理和分析数据。尽管这些工具功能强大,但是在处理需要进行增量数据处理以及记录级别插入,更新和删除场景时,仍然...
使用Apache Hudi + Amazon EMR进行变化数据捕获(CDC)
前一篇文章中我们讨论了如何使用Amazon数据库迁移服务(DMS)无缝地收集CDC数据。 https://towardsdatascience.com/data-lake-change-data-capture-cdc-using-amazon-database-migration-service-...

在Amazon EMR中执行Zeppelin笔记本作为重复工作
我正在从Databricks迁移到Amazon EMR,并计划使用Zeppelin笔记本代替Databricks笔记本。目前,许多Databricks笔记本计划作为工作。有什么方法可以创建定期作业或添加Zeppelin笔记本作为Amazon EMR中的重复步骤运行。任何对文档的引用也会有所帮助。
在Amazon EMR上配置Flink Rest API
我在亚马逊的EMR上通过YARN运行Flink应用程序,有一个主服务器和一个服务器。 我正在尝试ssh到主节点然后访问Flink REST API,但无法使EMR静态使用相同的主机/端口。 我已经尝试将此配置添加到EMR并从当前主节点的私有DNS中获取主机。它正在运行的实际端口是不同的yarn-se...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







