Hadoop序列化、概述、自定义bean对象实现序列化接口(Writable)、序列化案例实操、编写流量统计的Bean对象、编写Mapper类、编写Reducer类、编写Driver驱动类
@[toc]12.Hadoop序列化12.1序列化概述12.1.1什么是序列化序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。 反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。12.1.2为什么要序列化一...
Hadoop中的MapReduce概述、优缺点、核心思想、编程规范、进程、官方WordCount源码、提交到集群测试、常用数据序列化类型、WordCount案例实操
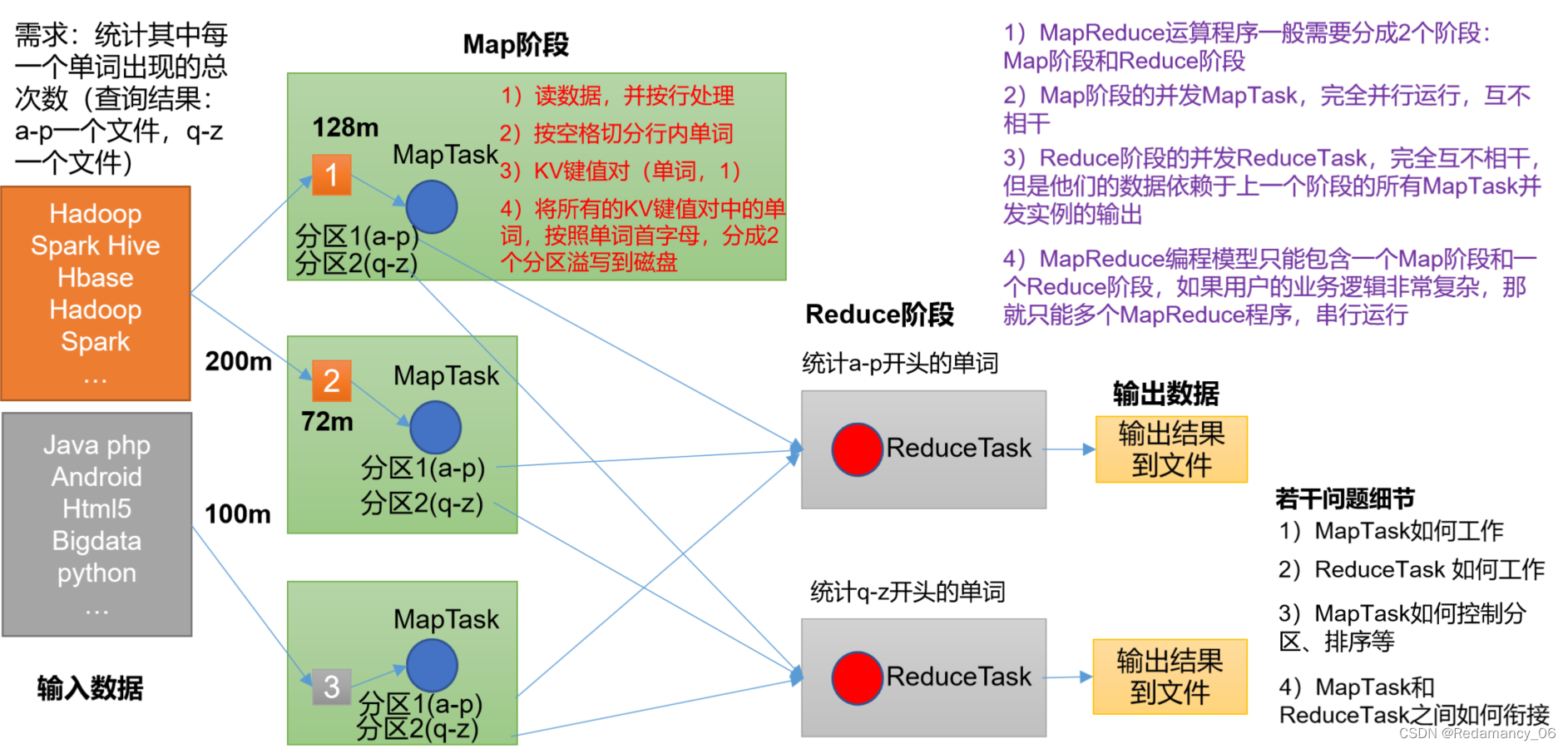
@[toc]11.MapReduce概述11.1MapReduce定义 MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Ha...

Hadoop的序列化与反序列化实操
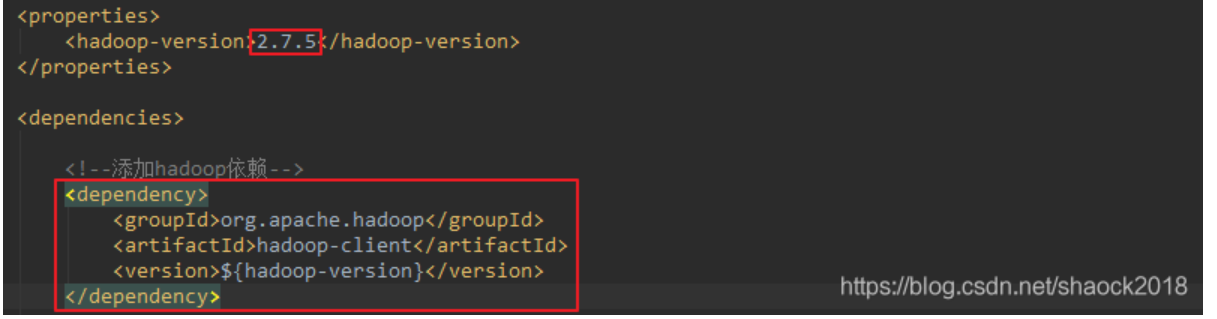
0x00 文章内容编写代码测试结果0x01 编写代码前提:因为需要用到Hadoop,所以需要先引入Hadoop相关的jar包<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>ha...

【Hadoop】(四)Hadoop 序列化 及 MapReduce 序列化案例实操
文章目录1 序列化概述2 自定义bean对象实现序列化接口(Writable)3 序列化案例实操1 序列化概述2 自定义bean对象实现序列化接口(Writable)在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








