Hadoop中NameNode和SecondaryNameNode、NN和2NN工作机制、Fsimage和Edits解析、oiv查看Fsimage、oev查看Edits、CheckPoint时间设置
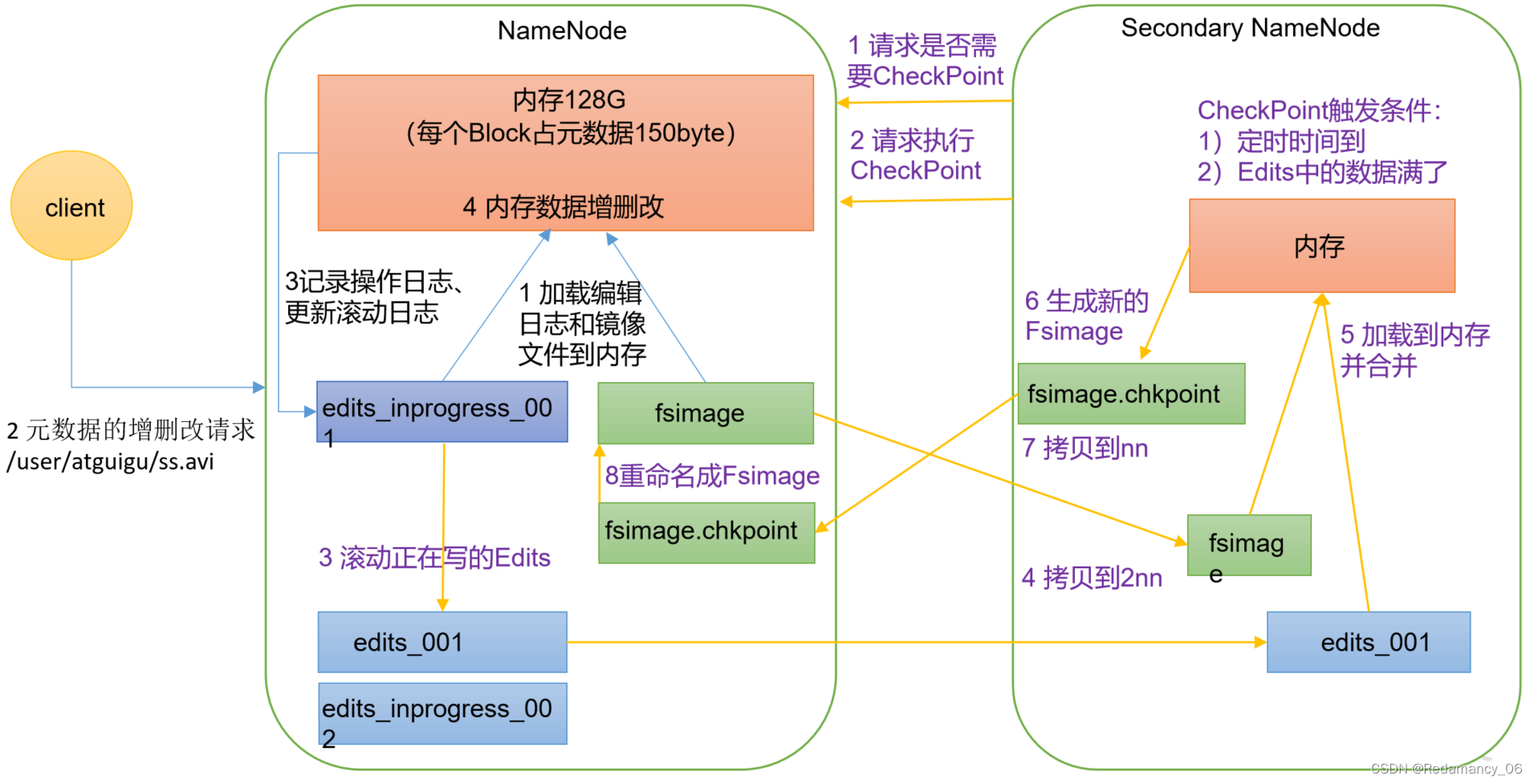
@[toc]9.NameNode和SecondaryNameNode9.1NN和2NN工作机制思考:NameNode中的元数据是存储在哪里的? 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如...
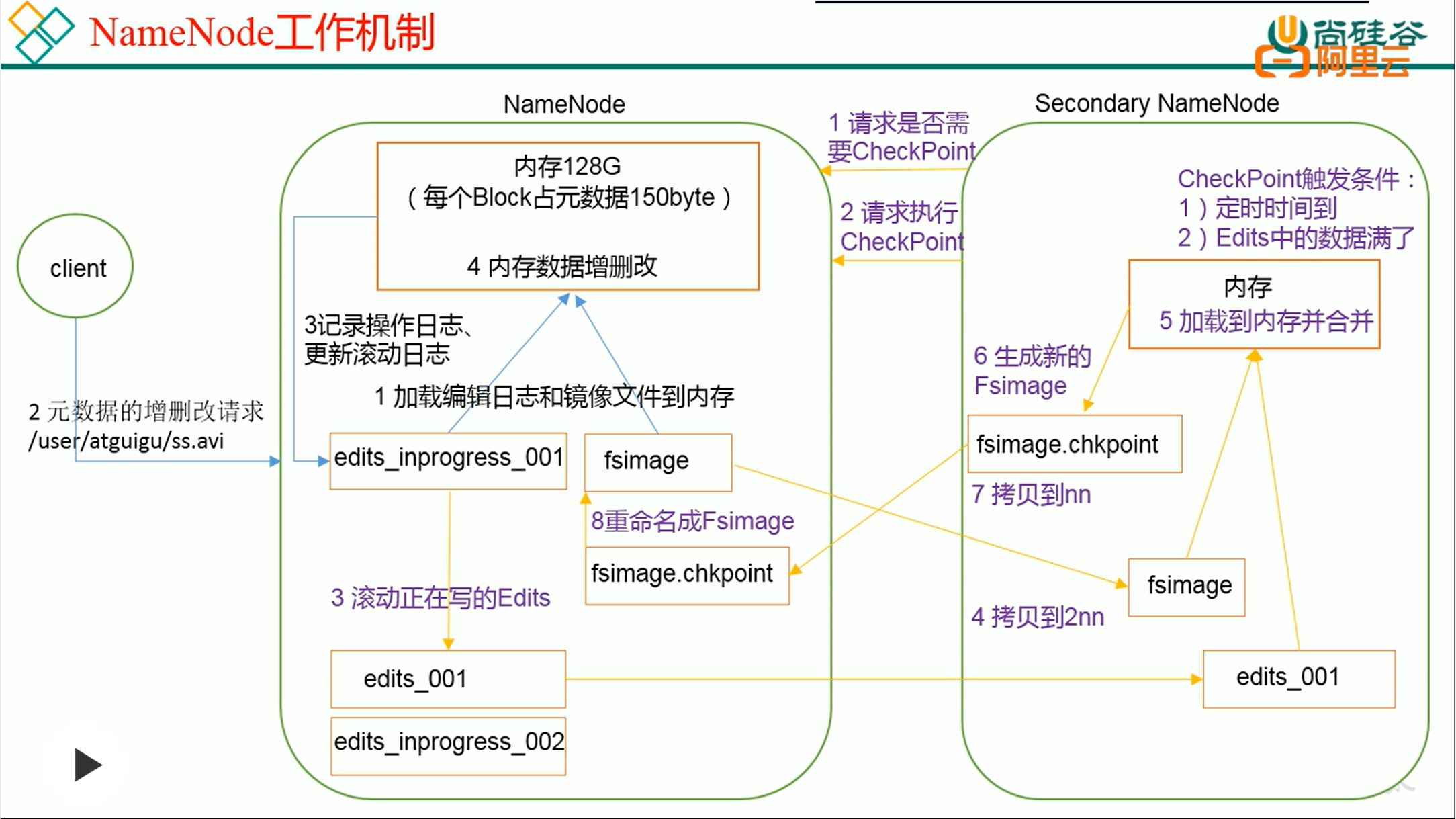
Hadoop-HDFS的NameNode工作机制
NameNode工作机制1、NameNode启动,加载编辑日志和镜像文件;(每个Block元数据约150B),获取最新元数据。2、HDFS客户端进行增删改操作3、NameNode记录编辑日志,之后修改内存中的元数据。4、SecondaryNameNode请求NameNode是否需要CheckPoin...

Hadoop的namenode的管理机制,工作机制和datanode的工作原理
HDFS前言: 1) 设计思想 分而治之:将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析; 2)在大数据系统中作用: 为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务 3)重点概念:文...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









hadoop namenode相关内容
- hadoop数据块namenode
- hadoop secondary namenode
- hadoop namenode datanode
- hadoop namenode宕机怎么解决
- hadoop namenode nn
- hadoop namenode resourcemanager
- hadoop namenode ha
- hadoop namenode同步
- hadoop格式化namenode cluster_id
- hadoop namenode工作原理
- hadoop namenode原理
- hadoop namenode无法启动
- hadoop namenode secondary
- hadoop namenode datanode secondary
- hadoop namenode元数据