
构建一个简单的电影信息爬虫项目:使用Scrapy从豆瓣电影网站爬取数据
Scrapy 是一个用 Python 编写的开源框架,它可以帮助你快速地创建和运行爬虫项目,从网页中提取结构化的数据。Scrapy 有以下几个特点: 高性能:Scrapy 使用了异步网络库 Twisted,可以处理大量的并发请求,提高爬取效率。 灵活:Scrapy 提供了丰富的组件和中间件,可以让你...
【详细步骤解析】爬虫小练习——爬取豆瓣Top250电影,最后以csv文件保存,附源码
豆瓣top250 主要步骤 1.发送请求,根据url地址,然后送请求2.获取数据,获取服务器返回的响应的内容3.解析数据:提取想要爬取的内容4.保存数据:将得到的数据保存为文档 具体实施 #豆瓣top250 import csv #引入csv模块 import requests...

python爬虫爬取豆瓣电影排行榜
import requests import re # 此模块专门用来提取有效信息 url = 'https://movie.douban.com/top250' head = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Ap...

爬虫实例——爬取豆瓣网 top250 电影的信息
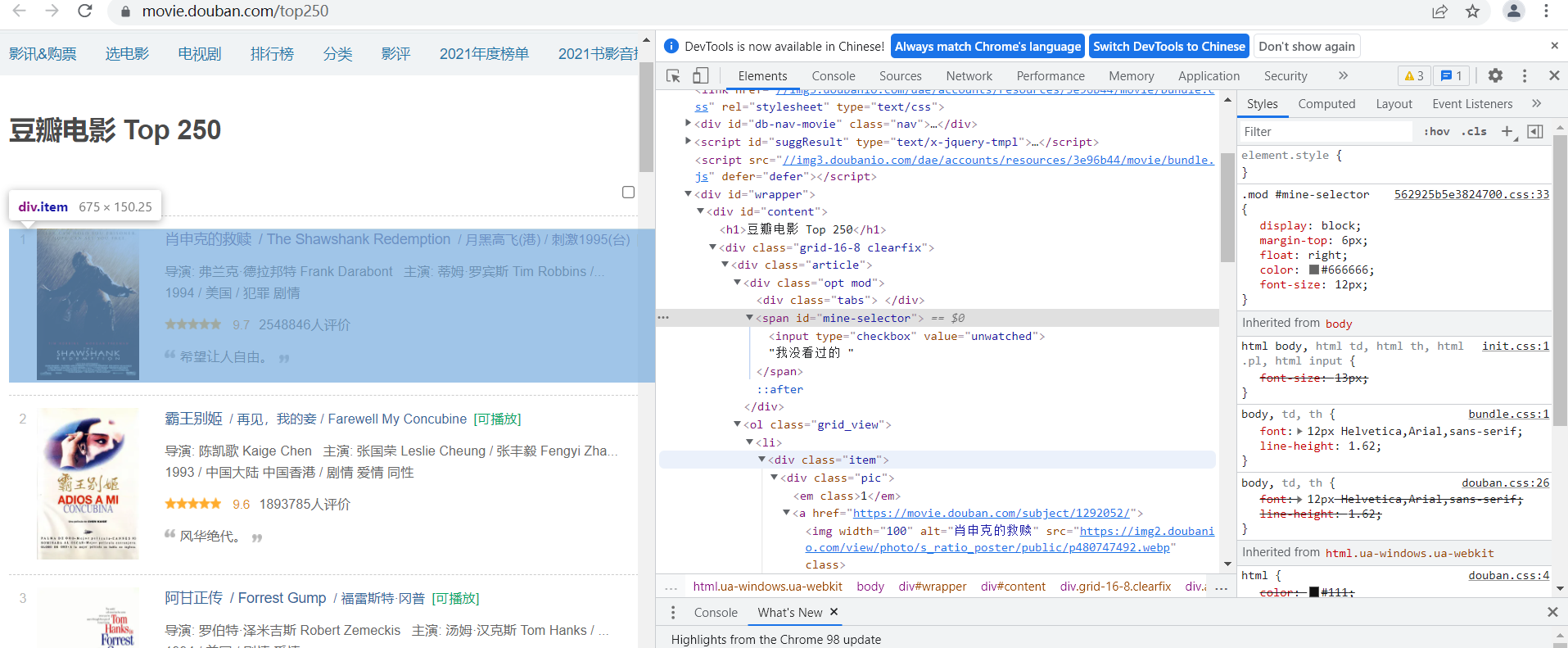
本节通过一个具体的实例来看下编写爬虫的具体过程。以爬取豆瓣网 top250 电影的信息为例,top250 电影的网址为:https://movie.douban.com/top250。在浏览器的地址栏里输入 https://movie.douban.com/top250,我们会看到如下内容:对于每一...
Python学习笔记:通过python爬虫获取豆瓣电影Top250
Step By Step一.什么是python爬虫按照自己的理解就是通过python语言去批量获取一些网页上的信息,并整理好。二.实现思路简单来说就是向豆瓣服务器发送请求,获取到服务器响应的250部电影数据后,响应的数据会分为10页,每页25部。这些数据展示在前台界面是以html格式展示的。我们的思...
14、web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
打码接口文件 # -*- coding: cp936 -*- import sys import os from ctypes import * # 下载接口放目录 http://www.yundama.com/apidoc/YDM_SDK.html # 错误代码请查询 http://www.yun...
Python网络爬虫(JSON, Phantomjs, selenium/Chromedirver,豆瓣电影、斗鱼直播、京东商城爬取)
个人网站刚上线 捧捧场 谢谢~ 项目还是遇到跟多坑的 分享一下 www.baliIT.com 域名备案中 如果不能访问 可以尝试 http://106.12.86.182/ json模块 什么是json? &nbs...
【Python】从0开始写爬虫——把扒到的豆瓣数据存储到数据库
1. 我们扒到了什么? id, 名称, 上映年份,上映日期,所属类目, 导演,主演,片长,评分,星评,评价人数 2. 把这些数据做一个分类。 a..基本信息 :名称, 导演,上映年份, 所属类目, 片长 b.评价信息:评分,星评,评价人数 c.主演表: 主演(我在纠结要...
【Python】从0开始写爬虫——豆瓣电影
1. 最近略忙。。java在搞soap,之前是用工具自动生成代码的。最近可能会写一个soap的java调用 2. 这个豆瓣电影的爬虫。扒信息的部分暂时先做到这了。扒到的信息如下 from scrapy import app import re header = { 'User-Agent': 'Mo...
【Python】从0开始写爬虫——转身扒豆瓣电影
豆瓣就比较符合这个“明人不说暗话”的原则。所以我们扒豆瓣,不多说,直接上代码 from scrapy import app import re header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子


最佳实践


