
GPT-4使用混合大模型?研究证明MoE+指令调优确实让大模型性能超群
谷歌、UC 伯克利等证明 MoE + 指令调优起到了 1 + 1 > 2 的效果。自 GPT-4 问世以来,人们一直惊艳于它强大的涌现能力,包括出色的语言理解能力、生成能力、逻辑推理能力等等。这些能力让 GPT-4 成为机器学习领域最前沿的模型之一。然而,OpenAI 至今未公开 GPT-4 ...

GPT-4得不到MIT学位,MIT研究团队回应「作弊」,但网友不买账
避重就轻的解释,还是没能获得大家的认可。几天前,一篇名为《Exploring the MIT Mathematics and EECS Curriculum Using Large Language Models》的论文经历了一场舆论风波。论文地址:https://arxiv.org/pdf/230...
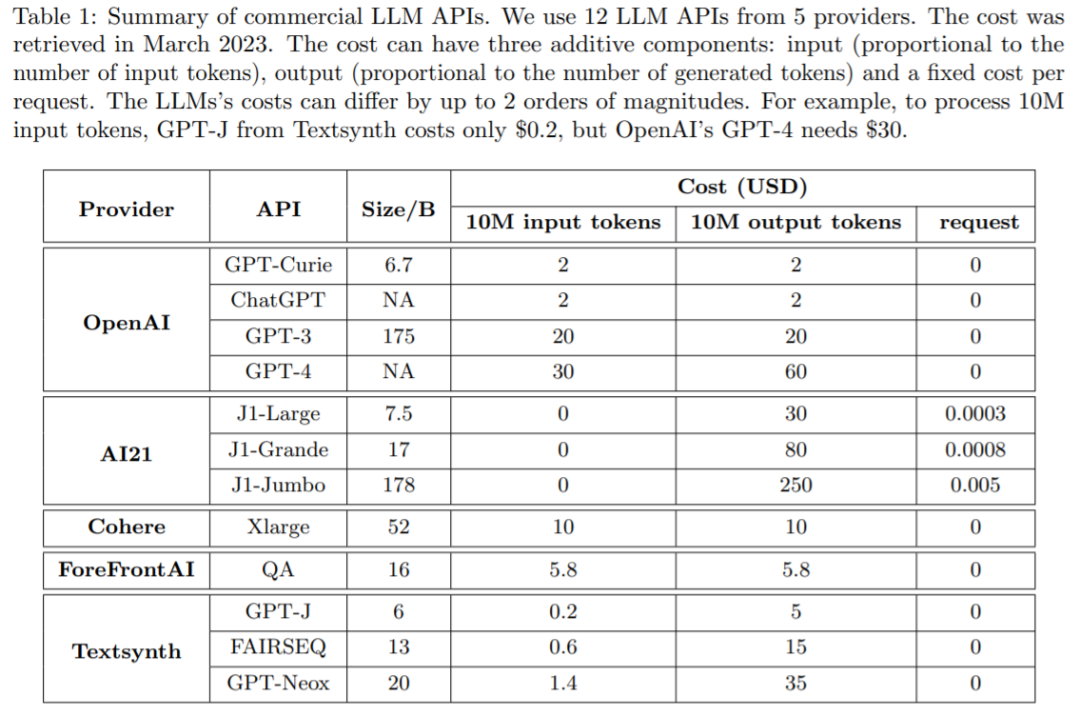
GPT-4 API平替?性能媲美同时成本降低98%,斯坦福提出FrugalGPT,研究却惹争议
Game Changer 还是标题党?随着大型语言模型(LLM)的发展,人工智能正处于变革的爆发期。众所周知,LLM 可用于商业、科学和金融等应用,因而越来越多的公司(OpenAI、AI21、CoHere 等)都在提供 LLM 作为基础服务。虽然像 GPT-4 这样的 LLM 在问答等...
少儿编程领域-基于GPT-3 & 大语言模型的AI助教研究
GPT-3(Generative Pre-trained Transformer 3)是一种自然语言处理模型,它是由 OpenAI 开发的,基于深度学习算法,采用了预训练和微调的方式来生成高质量、高度自然的文本内容。 GPT-3 的技术原理和实现机制如下: 模型架构:GPT-3 模型采用了 Tran...

真·量子速读:突破GPT-4一次只能理解50页文本限制,新研究扩展到百万token
能容纳 50 页文档的输入框不够用,那几千页呢?一个多月前,OpenAI 的 GPT-4 问世。除了各种出色的直观演示外,它还实现了一个重要更新:可以处理的上下文 token 长度默认为 8k,但最长可达 32K(大约 50 页文本)。这意味着,在向 GPT-4 提问时&...
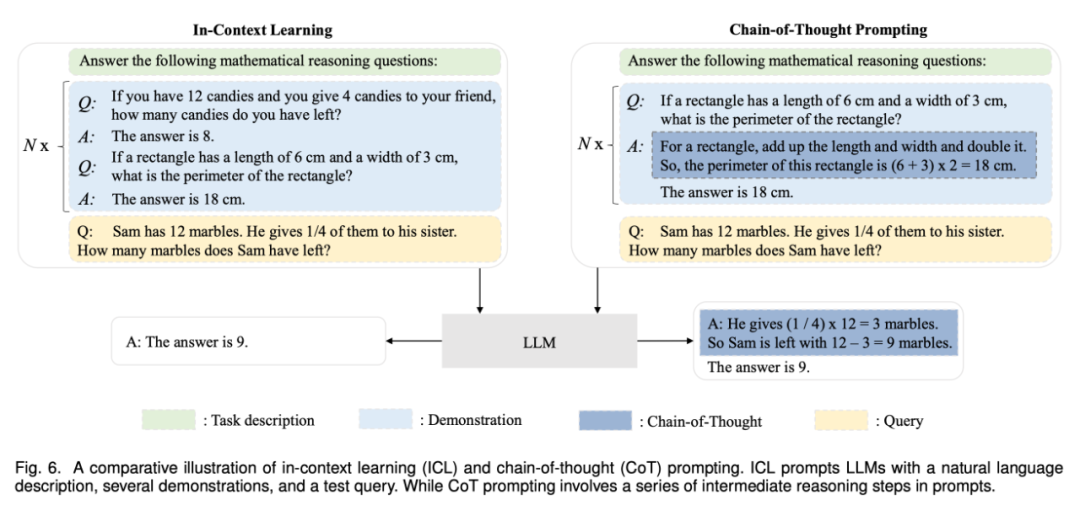
大型语言模型综述全新出炉:从T5到GPT-4最全盘点,国内20余位研究者联合撰写(2)
使用在预训练或适应性调整之后,使用 LLMs 的一个主要方法是为解决各种任务设计合适的 prompt 策略。一个典型的 prompt 方法是上下文学习(in-context learning),它以自然语言文本的形式制定了任务描述或演示。此外,思维链 prompting 方法可以通过将一系列中间推理...

大型语言模型综述全新出炉:从T5到GPT-4最全盘点,国内20余位研究者联合撰写(1)
为什么仿佛一夜之间,自然语言处理(NLP)领域就突然突飞猛进,摸到了通用人工智能的门槛?如今的大语言模型(LLM)发展到了什么程度?未来短时间内,AGI 的发展路线又将如何?自 20 世纪 50 年代图灵测试提出以来,人们始终在探索机器处理语言...
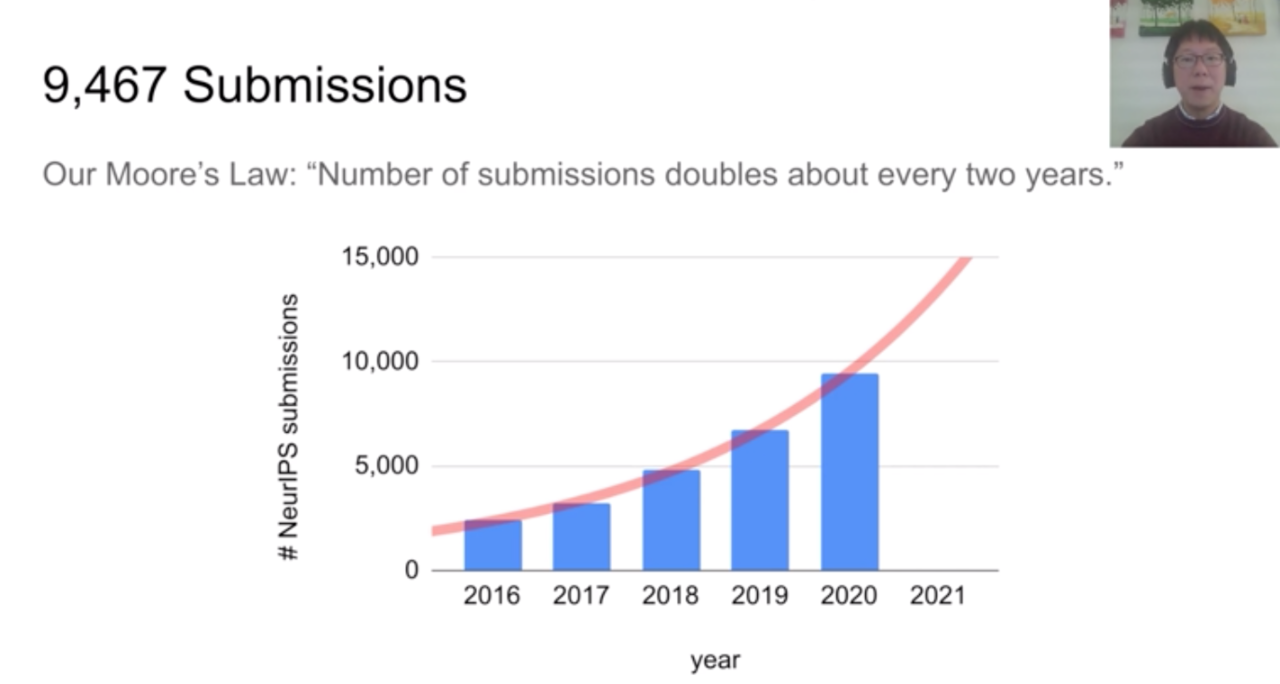
NeurIPS 2020奖项出炉:GPT-3等三项研究获最佳论文奖,华人一作论文获时间检验奖
北京时间 12 月 8 日凌晨,正在线上举行的全球人工智能顶会 NeurIPS 2020 公布了最佳论文等奖项。在一千八百余篇论文中,三篇论文获会议最佳论文奖项,OpenAI 等机构的 GPT-3 研究名列其中,可谓实至名归。人工智能顶会 NeurIPS 2020 于本月 6 日 - 12 日在线上...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
