[帮助文档] Paimon实时入湖分析入门
Apache Paimon是一种流批统一的湖存储格式,支持高吞吐的写入和低延迟的查询。本文通过Paimon Catalog和MySQL连接器,将云数据库RDS中的订单数据和表结构变更导入Paimon表中,并使用Flink对Paimon表进行简单分析。

一次线上Flink 背压情况分析之重新认识java dump 文件
1.背压情况kafka 不消费,Flink端背压高,发送端情况满,可以看背压图以及看flink 任务 back pressure 是否high 2.解决问题thread dump 分析 3.Thread dump 文件关键信息可以看到对应的行数代码分析可能出现异常原因:countDownLatch ...

[帮助文档] 将物联网平台数据集成到阿里云实时计算Flink版中计算和分析
物联网平台数据服务中的产品属性时序表、产品事件表和自定义存储表(时序表)数据,可以集成到阿里云实时计算Flink版中计算和分析,以便您实时分析和诊断设备的运行状况,实时检测运行故障等。本文介绍使用实时计算Flink版的连接器功能集成物联网平台实例下数据服务中数据的完成流程。
Flink CDC现在从Kafka读取消息显示source背压100这种应该怎样分析?
Flink CDC现在从Kafka读取消息显示source背压100这种应该怎样分析,具体应该从哪里看才能得出结论是Kafka压力太大发送的量小了还是集群本身的资源不够了?都是Kafka读取的,web ui的source都是黑的如何分析背压原因,该从哪入手?每次读取才几百?
[帮助文档] 如何实现Flink+DLF数据入湖与分析
数据湖构建(DLF)可以结合阿里云实时计算Flink版(Flink VVP),以及Flink CDC相关技术,实现灵活定制化的数据入湖。并利用DLF统一元数据管理、权限管理等能力,实现数据湖多引擎分析、数据湖管理等功能。本文为您介绍Flink+DLF数据湖方案具体步骤。
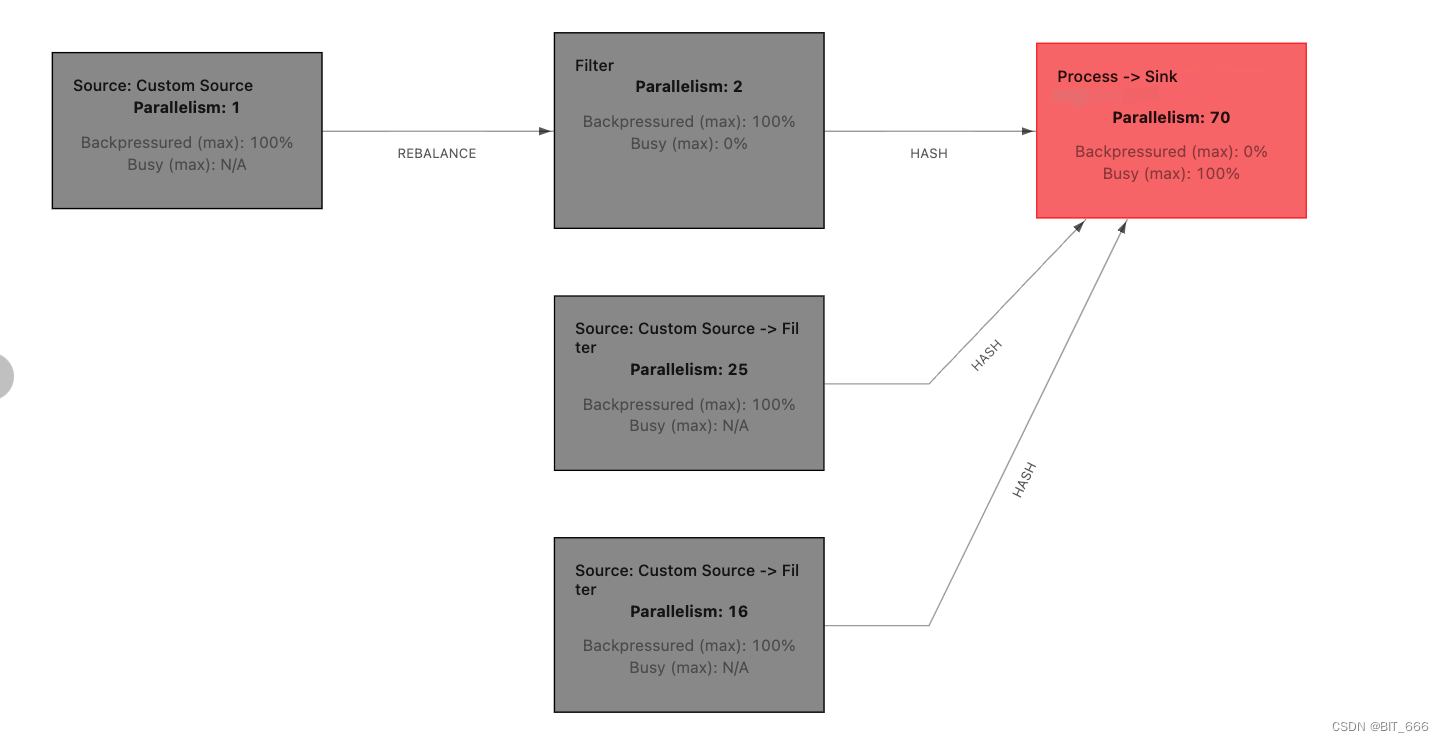
Flink/Hbase - Sink 背压100% 与 hbase.util.RetryCounter.sleepUntilNextRetry 异常分析与排查
一.引言Flink 程序内有读取 hbase 的需求,近期任务启动后偶发 sink 端背压 100% 导致无数据写入下游且无明显 exception 报错,重启任务后有较大概率恢复服务,但也有可能继续背压 100% 从而堵塞任务,遂开始排查。二.问题描述程序执行一段时间后,查看监控发现 Source...
[帮助文档] 表格存储结合Flink实现大数据分析的方案
本文介绍了表格存储结合实时计算Flink实现大数据分析的样例场景、架构设计等。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践
更多



实时计算 Flink版您可能感兴趣
- 实时计算 Flink版json
- 实时计算 Flink版oracle
- 实时计算 Flink版数组
- 实时计算 Flink版临时文件
- 实时计算 Flink版配置参数
- 实时计算 Flink版堆内存
- 实时计算 Flink版捕获
- 实时计算 Flink版办法
- 实时计算 Flink版表
- 实时计算 Flink版pg
- 实时计算 Flink版CDC
- 实时计算 Flink版数据
- 实时计算 Flink版SQL
- 实时计算 Flink版mysql
- 实时计算 Flink版同步
- 实时计算 Flink版报错
- 实时计算 Flink版任务
- 实时计算 Flink版版本
- 实时计算 Flink版kafka
- 实时计算 Flink版Apache
- 实时计算 Flink版配置
- 实时计算 Flink版设置
- 实时计算 Flink版 CDC
- 实时计算 Flink版模式
- 实时计算 Flink版运行
- 实时计算 Flink版数据库
- 实时计算 Flink版Yarn
- 实时计算 Flink版checkpoint