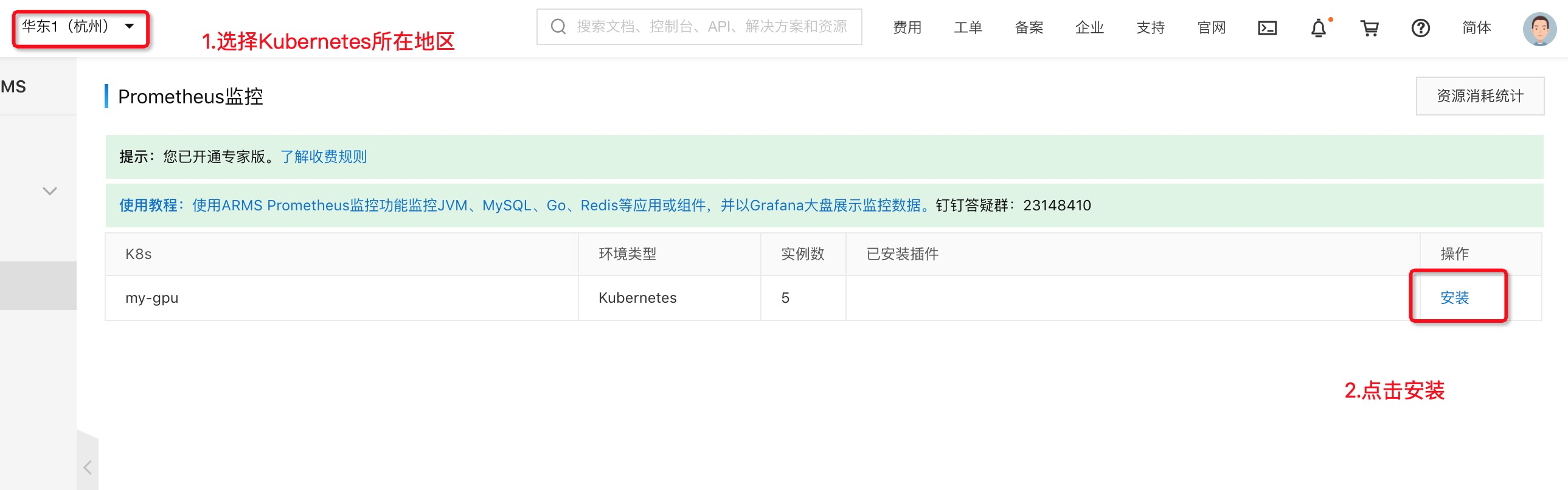
体验托管Prometheus监控阿里云容器服务Kubernetes的GPU资源
在阿里云容器服务中使用GPU资源运行进行AI模型训练和预测时,经常需要了解应用负载的GPU的使用情况,比如每块显存使用情况、GPU利用率,GPU卡温度等监控信息,通过内置ARMS可以从应用的维度去观测GPU的使用情况,了解资源水位,以及设定相应的报警,避免因为GPU资源的约束引发业务风险。另外相比自...
节点管理如何利用阿里云Kubernetes的GPU节点标签进行调度?
节点管理如何利用阿里云Kubernetes的GPU节点标签进行调度?
节点管理如何Kubernetes 集群支持轻量级 GPU 调度?
节点管理如何Kubernetes 集群支持轻量级 GPU 调度?
节点管理如何Kubernetes GPU 集群支持 GPU 调度?
节点管理如何Kubernetes GPU 集群支持 GPU 调度?
Kubernetes必备知识: GPU管理机制
所属技术领域: Kubernetes |名词定义| GPU全称是Graphics Processing Unit,图形处理单元。它的功能最初与名字一致,是专门用于绘制图像和处理图元数据的特定芯片,后来渐渐加入了其它很多功能。 |发展历程| 1 .NV GPU发展史以下是GPU发展节点表:1995 –...
kubernetes可以在pod之间共享单个GPU吗?
kubernetes可以在pod之间共享单个GPU吗?
基于Kubernetes的云上机器学习—GPU弹性扩缩容
前言 在深度学习中,要使用大量GPU进行计算。 而GPU往往价格不菲,随着模型变得越复杂,数据量积累,进行深度学习计算需要耗费极大的经济和时间成本。 解决方案 阿里云容器服务提供的深度学习解决方案,基于Kubernetes为核心,支持cluster-autoscaler 进行节点弹性扩缩容。除了CP...
kubernetes可以在pod之间共享单个GPU吗?
是否有可能在kubernetes pod 之间共享一个GPU ?
阿里云容器服务Kubernetes 基于GPU指标自动伸缩
基于GPU的指标扩缩容 在深度学习训练中,训练完成的模型,通过Serving服务提供模型服务。本文介绍如何构建弹性自动伸缩的Serving服务。 Kubernetes 支持HPA模块进行容器伸缩,默认支持CPU和内存等指标。原生的HPA基于Heapster,不支持GPU指标的伸缩,但是支持通过Cus...
基于阿里云容器服务监控 Kubernetes集群GPU指标
简介 当您在阿里云容器服务中使用GPU ECS主机构建Kubernetes集群进行AI训练时,经常需要知道每个Pod使用的GPU的使用情况,比如每块显存使用情况、GPU利用率,GPU卡温度等监控信息,本文介绍如何快速在阿里云上构建基于Prometheus + Grafana的GPU监控方案。 Pro...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子



最佳实践
更多




GPU云服务器您可能感兴趣
- GPU云服务器modelscope-funasr
- GPU云服务器加载
- GPU云服务器模型
- GPU云服务器函数计算
- GPU云服务器游戏
- GPU云服务器驱动
- GPU云服务器实例
- GPU云服务器安装
- GPU云服务器grid
- GPU云服务器stable
- GPU云服务器阿里云
- GPU云服务器服务器
- GPU云服务器modelscope
- GPU云服务器nvidia
- GPU云服务器cpu
- GPU云服务器ai
- GPU云服务器性能
- GPU云服务器训练
- GPU云服务器部署
- GPU云服务器配置
- GPU云服务器计算
- GPU云服务器版本
- GPU云服务器租用
- GPU云服务器深度学习
- GPU云服务器教程
- GPU云服务器cuda