python-scrapy框架(三)Pipeline文件的用法讲解
Pipeline是一个独立的模块,用于处理从Spider中提取的Item对象,实现对数据的进一步处理、存储和清洗等操作。下面将详细介绍Scrapy框架中Pipeline的用法。 1.创建Pipeline类 为了使用Pipeline类,我们需要在Scrapy项目的pipelines.py文件中创建一个...

探秘Python的Pipeline魔法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站AI学习网站。 前言 在Python数据科学领域,Pipeline(管道)是一个强...

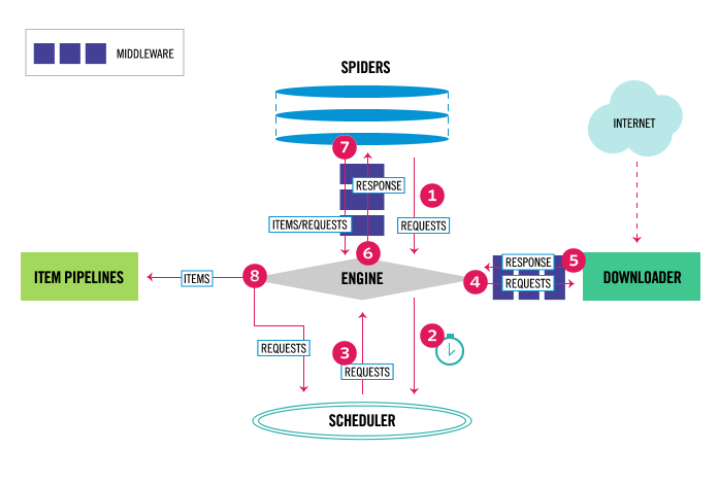
Python爬虫:Scrapy中间件Middleware和Pipeline
1、Spiderbaidu_spider.pyfrom scrapy import Spider, cmdline class BaiduSpider(Spider): name = "baidu_spider" start_urls = [ "https://www.baidu.com/" ] c...
Python:Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是item pipeline的一些典型应用:验证爬取的数据...
Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢弃而不再进行处理 item pipelin...
用 Django 的 Pipeline 优化网站前端-python报错
" 本文来自 @图拉鼎 的博客: 今天开始一步步优化网站,尽可能的让其响应更快、更省流量。第一步就是优化前端。 以前在玩Rails的时候,很羡慕它全自动化的Assets Pipeline,完全不用人操心就可以基本达到前端优化效果——甚至你不知道怎么优化也在不知不觉中优化了。 Ubuntu Tweak...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。