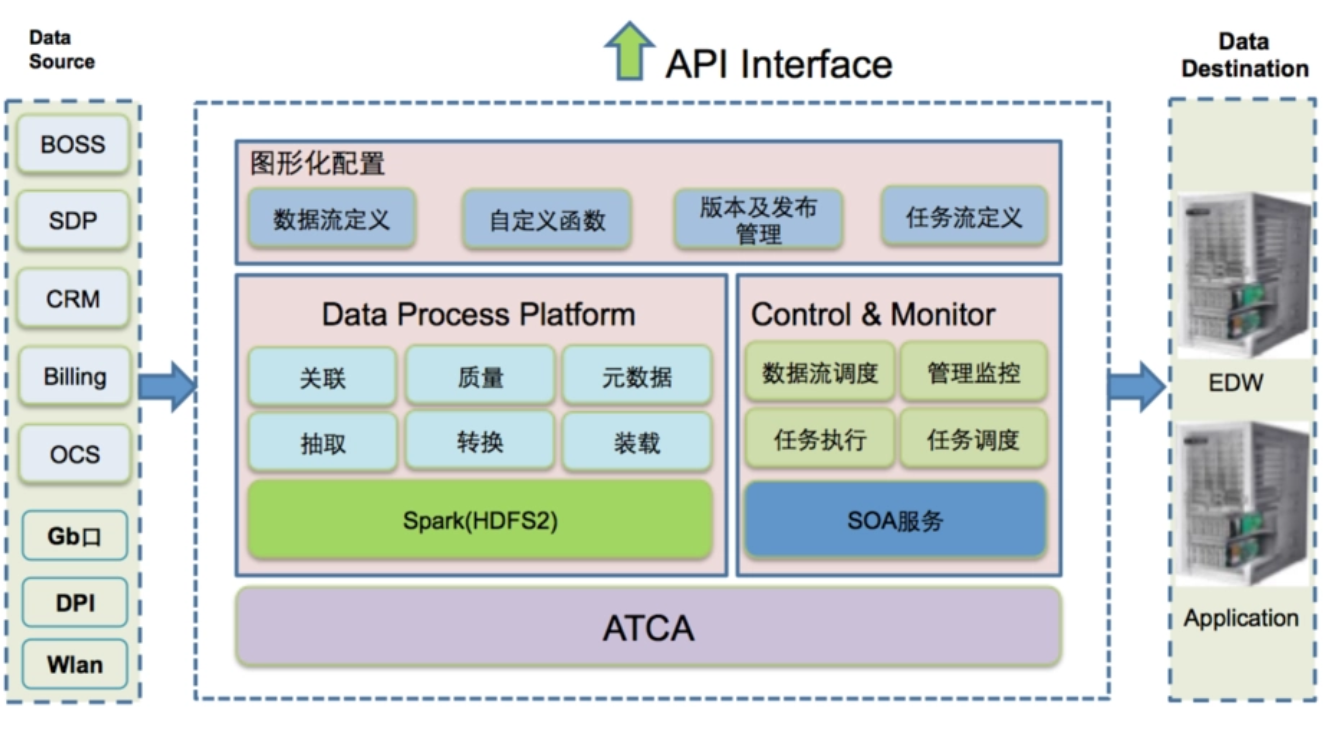
Spark是一个基于内存的通用数据处理引擎,可以进行大规模数据处理和分析
Spark是一个基于内存的通用数据处理引擎,可以进行大规模数据处理和分析。它提供了高效的数据存储、处理和分析功能,支持多种编程语言和数据源,包括Hadoop、Cassandra、HBase等。 Spark具有以下特点: 高效性:Spark使用内存计算技术,可以快速地进行数据处理和分析,比传统的磁盘读...
[帮助文档] 在TDX实例中基于BigDL PPML构建全链路安全的分布式Spark大数据分析应用
本文介绍在基于Intel® TDX安全特性的g8i实例中,使用BigDL PPML解决方案运行分布式的全链路安全的Spark大数据分析应用。

[帮助文档] 使用PythonSDK操作数据湖分析的Spark作业
本文将演示如何使用Python SDK提交一个计算π的任务,查看任务的状态和日志,超时终止任务, 以及查看虚拟集群的历史状态。
[帮助文档] 时空几何之Spark集成分析的概述
用户可以通过DLA Ganos实现Spark加载HBase中的时空数据并进行大规模时空分析操作。DLA Ganos是基于云原生数据湖分析(Data Lake Analytics,DLA)系统设计开发的,面向时空大数据存储与计算的数据引擎产品。基于DLA无服务器化(Serverless)数据湖分析服务...
[帮助文档] 开源自建Spark和DLASpark在3种测试场景下的测试结果及性能对比分析
本次测试采用3种不同的测试场景,针对开源自建的Hadoop+Spark集群与阿里云云原生数据湖分析DLA Spark在执行Terasort基准测试的性能做了对比分析。本文档主要展示了开源自建Spark和DLA Spark在3种测试场景下的测试结果及性能对比分析。
[帮助文档] 调用ListSparkJob用于翻页提取某个数据湖分析Spark虚拟集群的历史作业详情信息
调用ListSparkJob用于翻页提取某个数据湖分析Spark虚拟集群的历史作业详情信息。
【Spark Summit East 2017】Ernest:基于Spark的性能预测大规模分析框架
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。 本讲义出自Shivaram Venkataraman...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子





apache spark分析相关内容
- apache spark原理分析
- apache spark hudi分析
- apache spark数据集分析
- apache spark概念分析
- apache spark kafka分析
- apache spark分析学习笔记
- apache spark多数据源分析
- apache spark优化分析
- apache spark实现分析
- apache spark delta分析
- apache spark文件分析
- apache spark项目分析
- apache spark构建分析
- 大数据apache spark分析数据综合案例
- 分析apache spark系统
- apache spark based shuffle分析
- x-pack apache spark分析
- apache spark通信分析
- apache spark shuffle分析
- pig apache spark分析
- apache spark函数调用分析
- apache spark分析代码
- apache spark分析阅读
- apache spark计算分析
- apache spark部署分析
apache spark您可能感兴趣
- apache spark报错
- apache spark MaxCompute
- apache spark e-mapreduce
- apache spark任务
- apache spark节点
- apache spark SQL
- apache spark实践
- apache spark大数据处理
- apache spark应用
- apache spark Apache
- apache spark streaming
- apache spark数据
- apache spark Hadoop
- apache spark rdd
- apache spark大数据
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark机器学习
- apache spark实战
- apache spark学习
- apache spark flink
- apache spark Scala
- apache spark程序